「GPT‑4 クラスを安く回したい。でも 3.5 だと精度が足りないし、4 はお財布が死ぬ」
そんなジレンマで悩んだこと、ありませんか?
エージェントや RAG を本気で組み始めると、「推論が弱いと全部グダグダになる」くせに、まともな推論をするモデルはとにかく高い。
正直、ここ 1 年ぐらいの LLM 選定って、ほぼこれとの戦いだと思います。
そこに出てきたのが DeepSeek v3.2。
「GPT‑5 クラスの思考モデル」「GPT‑4.5 超えの推論性能」「価格はほぼ GPT‑3.5 帯」──こういう文言が並ぶと、エンジニアとしてはどうしても無視できません。
でも、単なるベンチマーク比較の記事はもうお腹いっぱいですよね。
この記事では、「v3.2 の何が“本当に”新しくて、どこが怖いのか」を、エンジニア視点でかなり主観的に整理してみます。
一言で言うと:LLM界の「React Hooks」っぽいものが来た

DeepSeek v3.2 を一言でまとめるなら、
「React Hooks が出てきたときの React」みたいな転換点を、推論に対してやろうとしているモデル
だと感じています。
- Hooks 以前の React:
- それなりに何でも作れたけど、状態管理やロジックの構造化は “頑張り次第” だった。
- Hooks 以後の React:
- 「状態とロジックをこう持つとキレイに書ける」というフレームが明示化されて、複雑な UI もパターン化できるようになった。
LLM もこれまで、
- GPT‑3.5/4 でもそれなりに推論はできたけど、思考プロセスはあくまで「 emergent な副産物」 だった。
- プロンプト職人芸に頼るしかなく、複雑なマルチステップ推論は“たまたま上手くいく”世界。
に留まっていたところを、DeepSeek v3.2 は
「推論そのものを一級市民として学習・運用スタックに組み込む」
という方向に全振りしてきた、という印象です。
何が本当に新しいのか:モデルじゃなく「カリキュラムとスタック」
正直、アーキテクチャ自体は普通の Transformer 系です。
MoE だの新規アテンションだの、魔法のアルゴリズムが出たわけではありません。
新しいのは「どう育てて、どう使わせるか」の統合設計にあると感じます。
三段ロケットの「推論カリキュラム」
DeepSeek v3.2 のトレーニングパイプラインはざっくりこうです:
- プレトレーニング
-
Web + コード + 数学など、従来どおりの大量データで「言語+知識」を叩き込む。
-
推論特化の追加学習
- ここでかなり攻めていて、
- チェイン・オブ・ソート(CoT)系の思考トレース付きデータ
- 数学証明・形式推論・長期計画と分解タスク
-
をメインターゲットとして継続学習させています。
-
好み&安全性を載せる最終段階(RL/Preference)
- 人手と自動評価を混ぜて、
- 最終回答の正しさ
- Jailbreak / prompt injection への耐性
- レイテンシ・効率
- を同時に狙う報酬設計。
重要なのは、2 の「推論特化フェーズ」が単なる微調整ではなく、カリキュラムとしてガッツリ組み込まれている点です。
ここでモデルに「途中の考え方」まで教え込んでいる。
訓練では「全部考えさせる」のに、本番では隠す
面白いのはここで、
- 学習時:
- モデル内部で詳細な思考ステップ(CoT)をガンガン出させる。
- それを見ながら「こう考えると正解にたどり着くよ」と報酬を与える。
- 推論時:
- 通常の API ではその思考トレースは非表示。
- ただし内部的には、学習時の癖が残っているので「よく考えてから答える」挙動をしやすい。
という「見えないけど効いている思考スタック」になっているところ。
React で言うと、Hooks の内部実装にアクセスはできないけれど、「状態がちゃんと管理された世界」を前提にコードが書ける感覚に近いです。
ある程度の「推論の冗長さ」を内部で許容しているおかげで、
- 一発回答型のモデルにありがちな
- 「一見それっぽいけど、よく読むと全然違う」回答
- をやや減らせている印象があります(もちろんゼロではありませんが)。
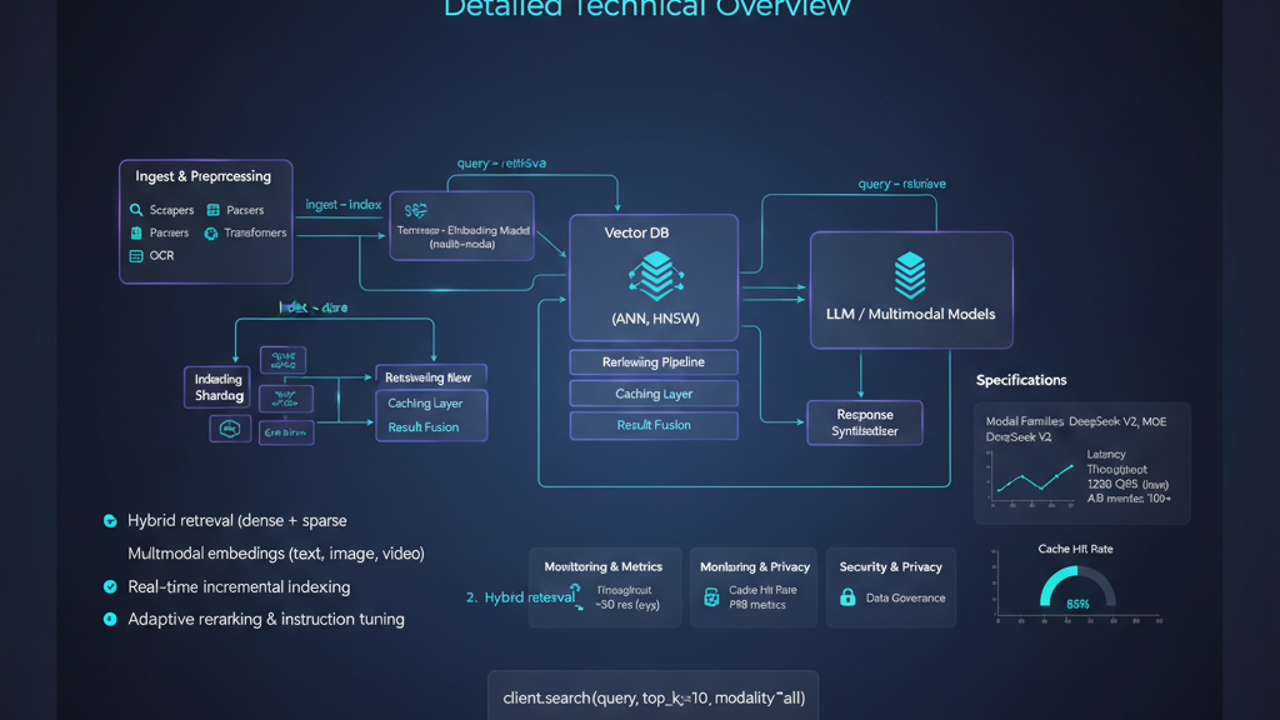
「Thinking API」=LLM を“脳みそ”として扱う設計
さらに、API レイヤーも完全に「推論をさせることが前提」の設計になっています。
- Chat Completions 互換のインターフェイス
- Tool / function calling
- JSON Schema ベースの構造化出力
…までは今どき標準装備ですが、v3.2 の売りはここからで、
- 制約付き推論モード
- エージェント的な長期計画・分解を意識した出力
- 「思考の冗長さ」をコントロールする構想
など、「ただのテキストジェネレータ」ではなく、
バックエンドの“推論エンジン”として組み込むことを前提とした API 設計
になっている点が結構効いています。
ぶっちゃけ、LangChain などの重いエージェントフレームワークを使わずに、素の API だけでそれなりのエージェント構成が組めるレベルに寄せてきている印象です。
競合と比べて何がエグいのか
では、それが実際どこまで効いていて、誰が一番困るのか。
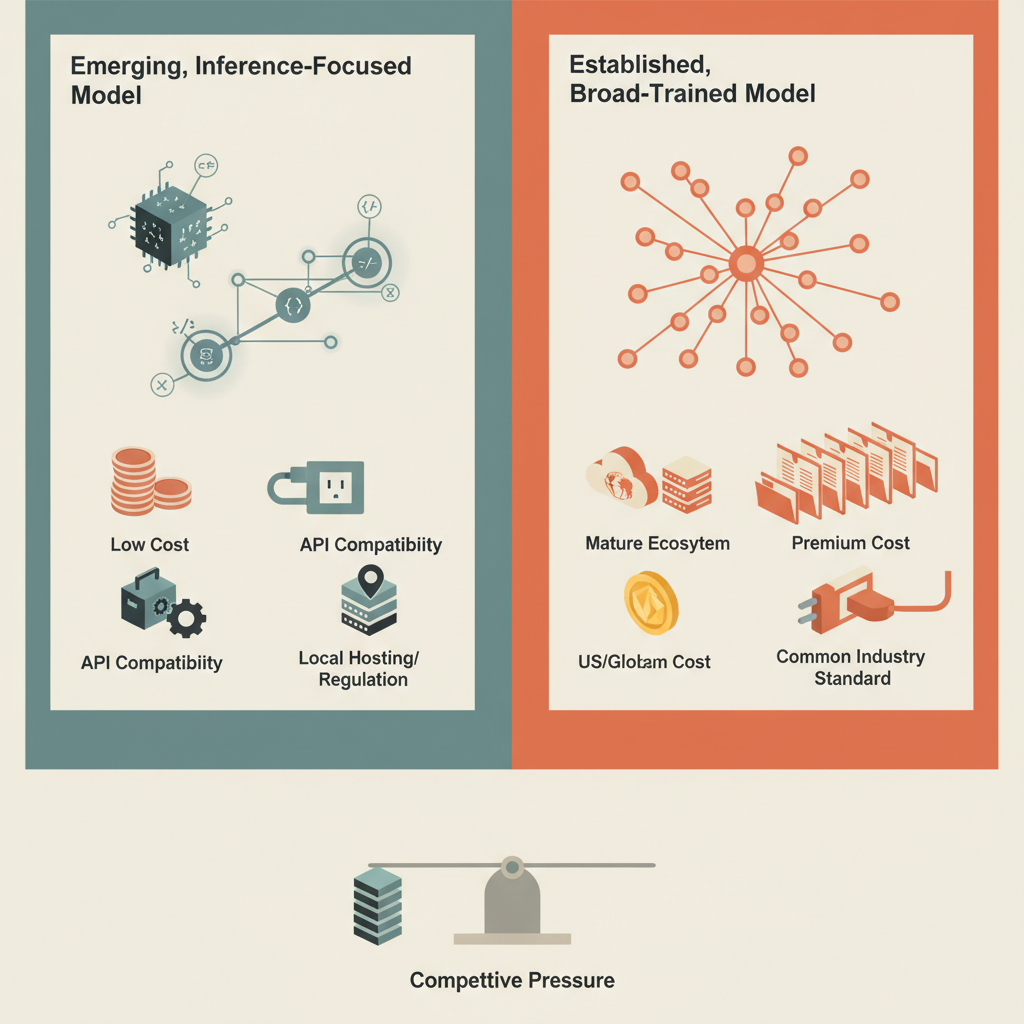
OpenAI GPT‑4.1 / 4.5 と比べると…
技術的なポジション取りはかなり明確です。
| 観点 | DeepSeek v3.2 | GPT‑4.1 / 4.5 | エンジニア的な意味 |
|---|---|---|---|
| 推論へのフォーカス | CoT・マルチステップ推論中心のカリキュラム | 汎用タスク向けの広い訓練 | 数学/コード/長期計画は v3.2 が有利な場面があり得る |
| API スタイル | OpenAI 互換路線 | 事実上の標準 | 既存アプリの移植コストが低い |
| コスト | GPT‑4 級の推論を GPT‑3.5 に近い価格帯で | プレミアム価格 | 「とりあえず全部 4 で」はやりにくくなる |
| エコシステム | まだ若い | SDK / 事例 / ドキュメント豊富 | 真面目に運用するならまだ OpenAI の安心感が強い |
| 地政学・規制 | 中国発・ローカルホスティング色強め | US ベース | 中国/一部 APAC では v3.2 有利、西側では慎重論 |
正直、OpenAI は一番直接的なプレッシャーを受けると思います。
- 「4 が欲しいけど高いから 3.5 で我慢」していた層に、
- 「4 クラスの推論を 3.5 の価格で」 と言えるカードが出た。
- 特に、エージェント / 高度な RAG / コーディング支援のような、“思考コスト” がクリティカルな系で効いてきます。
個人的には、“GPT‑4 でないと成立しなかったユースケース” が、コスパ的に一気に大衆化する可能性があるのが一番大きいと感じています。
Anthropic, Google, そして「中堅クローズドモデル」勢
正直、一番キツいのは 中途半端な GPT‑4 もどき です。
- OpenAI ほどの性能もブランド力もない
- DeepSeek ほどの価格攻勢も “思考モデル” 的な尖りもない
という位置にいるリージョナル LLM たちは、
「性能でも価格でも負ける」 という典型的なサンドイッチ状態になりかねません。
Anthropic や Google は、
- セーフティ / エンタープライズ連携 / 既存クラウドとの統合
でまだ戦える余地がありますが、
「ただの LLM プロバイダ」としての戦いをすると、v3.2 のようなコスパ特化モデルに相当食われると思います。
コミュニティの空気:期待と違和感の「混合ガス」
実際のユーザーフィードバックを眺めていても、雰囲気はかなり「期待しつつ、微妙な違和感も感じている」という感じです 🤔
良い声:v3.1 / R1 からの進歩はガチ
「新しいモデルはV3.1とR1よりもずっと良い感じです。推論がより自然で、より多くの側面をカバーし、同様の数のトークンを使用しています。」
これはかなり本質的で、
「同じトークン数で、考え方のカバレッジが増えている」のは素直に偉い。
- トークンコストが変わらない
- でも、より多面的な検討やステップが入る
というのは、まさに「内部でちゃんと考えさせている」トレーニングの成果っぽい動きです。
微妙な声:バリアント間の品質差と「英語最適化」疑惑
一方で、
「特別なものではないV3.2バージョンはそんなミスはしなかったけど、マジで出力の質が悪かった。中国のモデルは英語コンテンツ向けに最適化されてるんだよね」
という声も出ています。
端的に言うと、
- v3.2 の中にも「当たり外れ」がある
- 特に「Speciale」とか「Exp」とか、実験的バリアントの出来不出来がバラついている
- そしてやっぱり、英語向けの最適化が中心っぽい
という懸念です。
これは中国発 LLM あるあるでもありますが、日本語やその他マイナー言語で運用したい人からすると、
「英語だと神、他言語だと凡庸」というパターンはかなりつらい。
ぶっちゃけ、日本語圏で本気で商用投入するなら、
- 英語での挙動をベースラインにしつつ
- 日本語のカスタムデータで追加ファインチューニング or プロンプト工夫
をしないと、「GPT‑4 から切り替えたけど、なんか日本語だけ質が落ちたよね」問題にハマる可能性が高いです。
「ぶっちゃけどこが killer feature なのか?」

いろいろ書きましたが、エンジニア目線で一番インパクトがあるポイントを一個に絞ると、
「エージェントの“脳みそ”として前提にできる推論力を、GPT‑3.5 価格帯に落としてきたこと」
だと思っています。
エージェント / RAG の「常時 4 クラス」化が現実的になる
これまでの現実:
- L1 判定 → GPT‑3.5
- 難しいときだけ fallback で GPT‑4
みたいな二段構え戦略をよく見かけましたが、
DeepSeek v3.2 が本当に「4.5 クラスの推論」を「3.5 価格」で出してくるなら、
- 最初から最後まで全部 v3.2 に投げる
という設計が現実的になります。
これ、エージェント設計をかなりシンプルにしてくれます。
- モデル切り替えの条件分岐
- コンテキスト再構成
- コスト最適化の枝刈り
…といった「コストのためだけに存在するロジック」が減るので、
システム全体のバグポイントも下がる。
単純な LLM アプリより、「バックエンド的な使い方」で真価が出る
v3.2 のカリキュラム設計を見る限り、
「1 問 1 答のチャットボット」より「裏側でこっそり推論してくれる頭脳」としての利用が真骨頂だと思います。
たとえば:
- ビジネスルールチェック
- ログ解析 & 根本原因推定
- データパイプラインの変換ロジック設計
- コードリファクタリング案の生成
など、「最終的には JSON なりコードなりの“構造化アウトプット”で返してくれた方が嬉しい」系のタスク。
こういう場面で、
- JSON Schema で出力を縛りつつ
- 内部では勝手にマルチステップ推論してくれる
というのは、かなり扱いやすいです。
ここは、「LLM を UI に出さない使い方」が増える中で、確実に価値が出てくるポイントだと感じています。
ただし、懸念点もかなりデカい
ここまでベタ褒めっぽく書きましたが、正直、そのままプロダクションで全面採用はおすすめしません。
理由はいくつかあります。
エコシステムの若さ:バグと泥臭さは覚悟が必要
- OpenAI は良くも悪くも「一度は誰かが同じ問題でハマっている」感がありますが、
- DeepSeek はまだ事例も英語ドキュメントも少ない。
つまり、
- レートリミットやエラー仕様の細かい癖
- ツールコーリング周りの edge case
- モデル更新時の挙動変化
あたりを、自分たちで調べて地雷を踏んでいく覚悟が必要です。
日本語圏だと特に、
「Stack Overflow にも Qiita にも答えがない」状態になる可能性が高いので、
小規模チームがいきなりメインプロバイダとして据えるのは、かなりリスキーです。
「推論 ≠ 無謬」問題は依然として残る
思考トレースを学習しているからといって、
「間違わなくなる」わけではありません。
むしろ、
- 論理っぽいステップを踏んだ上で
- 間違った前提から
- とてももっともらしい嘘を言う
というパターンがより高度になるリスクすらあります。
金融・法務・医療・制御系などでは、
- どれだけ推論が賢くなっても
- 「人間のレビュー」「二重チェック」「外部ツールによる検証」は必須
という前提は変わりません。
「GPT‑5 クラスの思考」というマーケティング文言に引っ張られて、
検証プロセスをサボるのが一番危ないと感じています。
ベンダーロックインと「推論スタイルへの最適化」
DeepSeek v3.2 は OpenAI 互換 API をうたっていますが、
- レート制御
- コンテンツポリシー
- ツール呼び出しの“積極性”
- 回答の冗長さ・スタイル
など、挙動にはかなり癖があります。
これに合わせてプロンプトやパイプラインをチューニングし始めると、
- 「DeepSeek v3.2 の推論スタイル前提」の設計
- → いざ他プロバイダに戻そうとしても、挙動がズレまくる
という、見えづらいロックインが発生します。
個人的には、
- 最初から「複数プロバイダ」を前提とした抽象レイヤー
- テストスイートによるモデル切り替え時のリグレッションチェック
を整えておかないと、
後で「なんでこんなに v3.2 前提のコードなんだ…?」と未来の自分にキレることになると思います。
中国発モデルならではのガバナンス・コンプラ問題
これは技術というよりガバナンスの話ですが、西側企業からすると、
- データの所在
- プライバシー規制(GDPR など)との整合
- 政治的リスク
といった懸念はどうしてもついて回ります。
逆に、中国 / 一部 APAC では
- 米国発クラウドに載せにくい事情
- ローカルホスティングの要件
があったりするので、
「どの規制圏をターゲットにするか」で評価が真逆になるモデルだと言えます。
プロダクションで使うか?正直、まだ「戦略的なお試し枠」が妥当
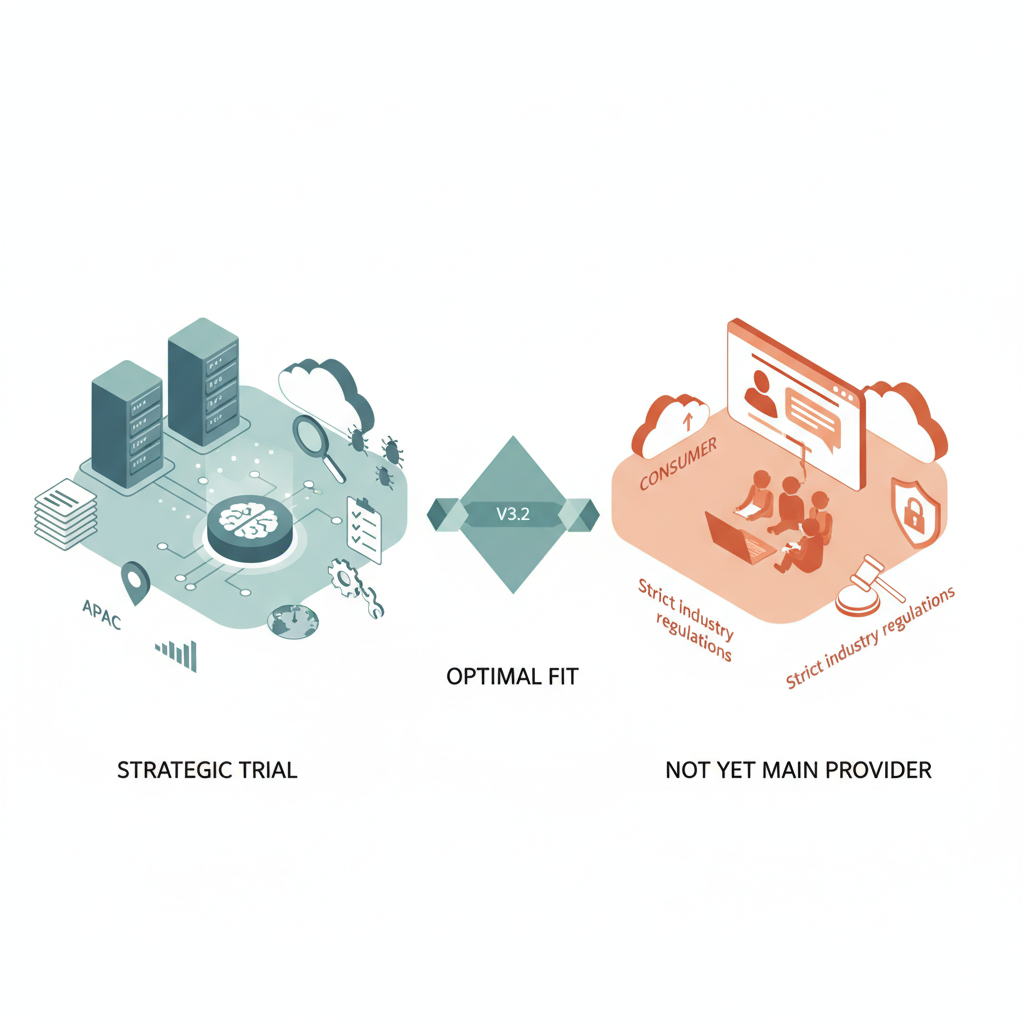
最後に、エンジニアとしての率直な結論です。
メインプロバイダとして全面移行するのは時期尚早。
ただし「推論コストが重い一部ワークロード」に対して、
戦略的に導入する価値はかなり高い。
という立ち位置かなと。
こういう使い方なら、今すぐ PoC する価値あり
- GPT‑4 でしか成立していないが、コストがつらいバッチ推論
- 例:バグレポートの自動分類+原因推定、大量コードの静的レビュー支援
- エージェントの“頭脳”だけを GPT‑4 相当のまま維持したいケース
- 内部でたくさんツールを叩く系
- 英語中心のプロダクトで、APAC / 中国圏向けのレイテンシや規制対応を強化したいケース
このあたりは、v3.2 がちょうどハマるポジションです。
こういうところをメインでやっているなら、まだ様子見推奨
- 日本語中心のコンシューマ向けチャットボット
- 規制が厳しい業種(金融・医療・公共系)でのメイン推論系
- LLM 経験の薄い小規模チームで「とりあえず一社に全振りしたい」ケース
このあたりは、
- まずは OpenAI / Anthropic / Google の「安定株」で土台を固めてから
- DeepSeek v3.2 はサイドカー的な位置づけで導入
するほうが現実的だと思います。
まとめ
- DeepSeek v3.2 は、「推論を一級市民にした LLM」という意味で、確かに React Hooks 以来の感覚的な転換に近いものがあります。
- 技術的な新規性は「モデル構造」よりも、三段カリキュラム+Thinking API というスタック全体の設計にある。
- コスパ的には、「GPT‑4 クラスの思考を GPT‑3.5 価格で」というかなり攻めたポジションを取りに来ており、特にエージェント/RAG/コーディング支援には刺さる。
- 一方で、エコシステムの若さ・英語偏重・ベンダーロックイン・ガバナンスといった懸念は無視できないレベル。
- 結論としては、
「メイン一本足打法にするにはまだ早いが、“推論が重い部分”から戦略的に差し替えていく価値は高い」
という、かなり攻めがいのある第二プロバイダ候補だと感じています。
もしあなたの現行スタック(OpenAI / Anthropic / ローカル LLM など)と、
狙っているユースケース(エージェント、RAG、コーディング支援など)を教えてもらえれば、
- どのワークロードを v3.2 に切り出すと一番コスパが効くか
- どのくらいの検証やガードレールを用意すべきか
まで含めて、もう少し踏み込んだ「実戦投入プラン」を組んでみます。


コメント