
「LLM を本番に入れたら、レスポンス遅いし、コストもじわじわ効いてきてつらい…」
そんな経験、ありませんか?
チャットボットでも、RAG でも、エージェントでも、「とりあえず一番いいモデル」を選んだ結果、
- レイテンシが 2〜3 秒当たり前
- 月末に請求書を見て冷や汗
- 結局「PoC 止まり」でプロダクションに乗らない
こういうパターン、ここ 1 年で何度も見てきました。
そんな中で出てきたのが 「Gemini 3 Flash」。
ただの「新しいモデル」ではなく、アーキテクチャの組み方を変えてしまうタイプのモデルだと感じています。
一言でいうと:LLM 版「Node.js vs Rails」戦争が始まった
Gemini 3 Flash を一言で例えるなら、
LLM 界の「Node.js」ポジションを Google が本気で取りに来た
という印象です。
- いままで:
- GPT‑4 / Gemini Pro / Ultra みたいな「フルスタックで重いフレームワーク(Rails 的なやつ)」に全部投げる世界
- これから:
- 「軽くて並列性高いランタイム(=Flash)」を前段に置く
- 重い推論は必要なときだけ Pro / Ultra にエスカレーション
正直、これをちゃんと使いこなせるチームと、
ずっと「なんとなく一番高いモデルを全部に使う」チームで、
数ヶ月後の運用コストとユーザー体験にかなりの差が出ると思っています。
何がそんなに違うのか?ざっくり Gemini 3 Flash の正体
「速さ」と「安さ」に全振り…ではないのがポイント
Gemini 3 Flash は、
- 低レイテンシ
- 高スループット(並列処理)
- 低コスト
このあたりを前面に出しているモデルです。
ここだけ聞くと「また小さいモデルでしょ?」と思いがちなんですが、ポイントはここ👇
“frontier” クラスの頭脳を、推論側で徹底的に高速化している
つまり、「単にパラメータを減らした小さいモデル」ではなく、
大きめの頭脳を “速く使う” ために調整したモデルクラスという立ち位置です。
- ちゃんと マルチモーダル(テキスト + 画像 + 動画 + ドキュメント)
- ちゃんと ツール実行 / 関数呼び出し もできる
- 長めのコンテキストも扱える(具体的なトークン数は非公開だけど、従来の高性能 Gemini と同じレンジ)
「速いけどバカ」ではなく、
「そこそこ賢くて、とにかくさばける」 ワーカーを大量投入できる感じです。
エージェントの「実働部隊」向けにチューニングされている
ドキュメントを読む限り、Google 自身が強く推している使い方はこうです:
- プランナー / ブレイン役 → Gemini 3.5 Pro / Ultra
- エグゼキュータ / 手足役 → Gemini 3 Flash
つまり、
- ユーザーの要件を分解したり
- ワークフローを計画したり
- どのツールをどう組み合わせるかを考えるのは Pro/Ultra
- 実際の API 叩き、RAG、軽めの推論、多数ユーザーの同時処理は Flash
この「2 段構成」を、Google 自身が前提にした設計になっているのが今回のミソです。
正直、これは「単に新モデルが出ました」という話ではなく、
アーキテクチャの考え方をアップデートしろというメッセージだと受け取りました。
なぜこれが重要か:gpt‑4o-mini / Claude Haiku とのガチ殴り合い

「速いモデル」レーンの本命を取りに来た
競合のポジションで並べるとこういう感じです:
- OpenAI: gpt‑4o-mini / 4.1-mini
- Anthropic: Claude Haiku
- Meta: Llama 3.1 8B / 70B(ホスティング含む)
- Google: Gemini 3 Flash(+今後の Flash Lite 系)
このレーンは、
- チャットボット
- RAG
- ツール実行エージェント
- 構造化抽出(JSON 出力)
- マルチモーダルの軽い解析
こういう 「大量トラフィックが来るところ」 が全部乗っかってくる、
LLM インフラのボリュームゾーンです。
ここで勝てると:
- 「とりあえずこのモデルでいいじゃん」がデフォルトになる
- SDK / サンプルコード / ノウハウのほとんどがそのモデル前提になる
- 結果として、クラウド選定まで引きずられる
Google が Gemini 3 Flash を「frontier intelligence built for speed」とうるさく言うのは、
ここで負けると全部持って行かれるのをよくわかっているからだと思います。
GCP / Google エコシステムとの「抱き合わせ戦略」
Gemini 3 Flash が本領を発揮するのは、正直ここです👇
- Vertex AI(エージェント、ワークフロー)
- BigQuery, Dataflow, GCS との連携
- Workspace(Gmail, Drive, Docs)との連動
- Android / Chrome / Google Search サイドとの統合
特にエンタープライズでよくあるパターン:
- すでに GCP を使ってデータ基盤を組んでいる
- ログもドキュメントも GCS / BigQuery に溜まっている
- 社内コラボレーションは Google Workspace 依存
こういう組織だと、
「データは GCP にあるのに、
LLM だけわざわざ Azure OpenAI / OpenAI API / AWS + Anthropic に抜けるのか?」
という構図になるわけで、
そこに 「Gemini 3 Flash + Vertex AI Agents」で完結する世界観 を投げ込まれたら、
現実的には Google 側に寄せる圧力がかなり強くなるはずです。
OpenAI 側ももちろん Azure と組んで同じことをやっているので、
これはもう完全に クラウドの陣取り合戦のフロントライン ですね。
正直な話:1.5 Flash / 2.5 Flash 時代への不信感はデカい
ここまで良いことを書きましたが、コミュニティの空気はそんなに単純ではなくて、
- 「1.5 Flash はマジで GPT‑3.5 と同レベルかそれ以下だった」
- 「2.5 Flash と Pro、最近めちゃくちゃバカになってない?」
みたいな声が普通に飛んでます。
「Gemini(2.5 flashとproの両方)がめちゃくちゃバカになっていて…」
「Flash 1.5 って、マジでクソだったよね。」
このあたり、正直かなり本質的な懸念で:
- ローンチ直後はそこそこ賢い
- 時間が経つと、
- 安全性フィルタ強化
- 内部アップデート
- コスト最適化
…の結果として、
ユーザー側から見ると「なんか最近アホになってない?」と感じる
というパターンは、どのベンダーでも起きがちです。
Gemini 3 Flash についても、
- 「ローンチ時点では確かに 1.5 Flash よりかなり良い」
- でも 数ヶ月後もその品質が維持されるかは誰も保証していない
この点をどう見るかで、
- 「今から本番アーキテクチャの中核に据えるか?」
- 「まだ Pro / 他社モデルと併用しつつ様子を見るか?」
判断が分かれると思います。
The Real Killer Feature:アーキテクチャを変えろ、というメッセージ
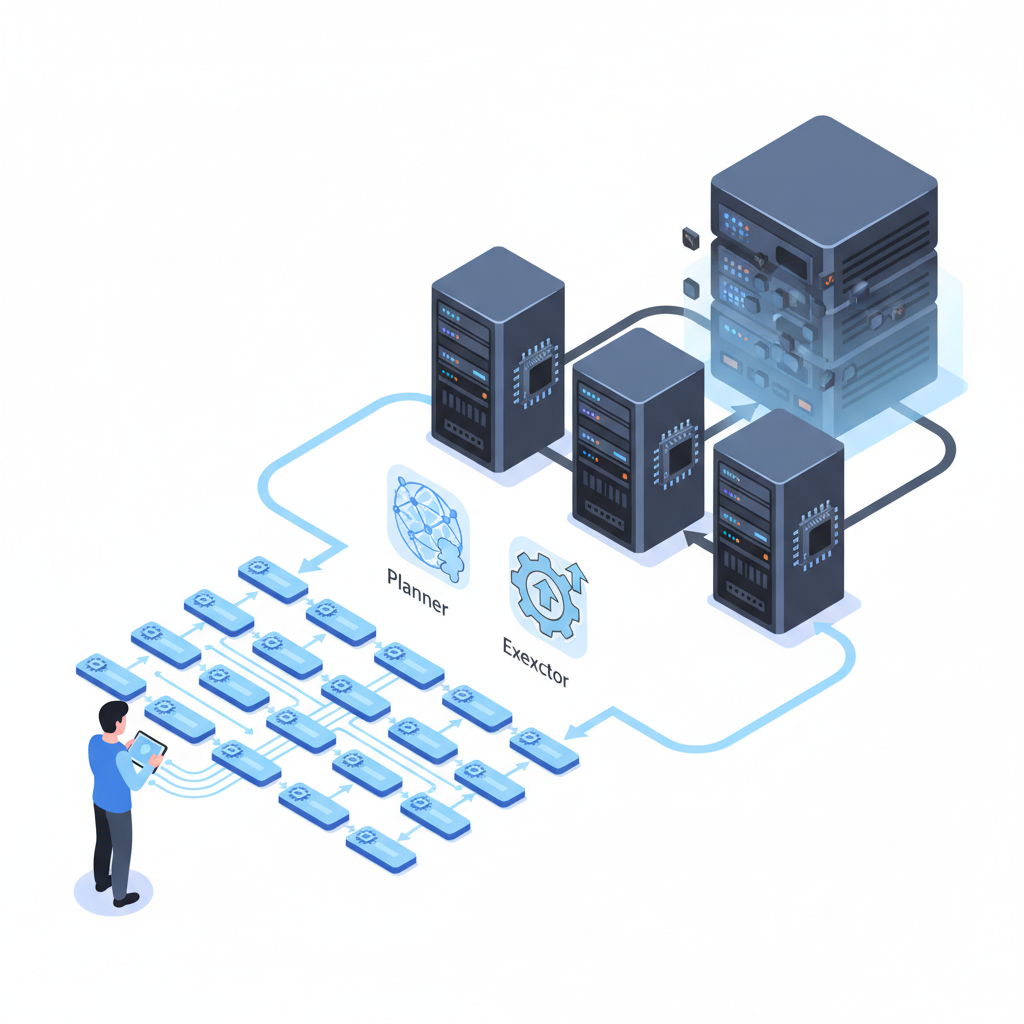
個人的に、Gemini 3 Flash の一番おいしいところはスペックの話ではなくて、
「こういう構成にしろ」という Google からの “設計指針” が明確になったことだと思っています。
推奨アーキテクチャ(勝手に要約)
- フロントのユーザー対話・軽い推論・ツール実行
→ Gemini 3 Flash を常用 - むずかしい長文要約・大規模コードリファクタ・高度な分析
→ 必要なときだけ Gemini 3.5 Pro / Ultra にエスカレーション - 内部的には、明確に二種類の LLM を使い分ける
- Planner(思考)
- Executor(実行)
これ、昔の Web 開発でいうと:
- Rails で全部やるモノリシック API から
- Node.js ベースの軽量 API やマイクロサービスを前段に置く構成 へ
移っていった流れとかなり近いです。
ぶっちゃけ、「LLM を 1 つのサービスとして見ている」設計は、
そろそろ古くなり始めている気がします。
LLM を CPU / GPU リソースと同じように “役割で分けて使う” 時代に入った、
その象徴的なモデルが Gemini 3 Flash、という感じです。
ただ、懸念点もかなりある…
がっつり Google ロックインになる危険性
正直、Gemini 3 Flash のおいしさを全部取ろうとすると、
- Vertex AI Agents
- Google のエージェントテンプレート
- BigQuery / GCS 連携の各種マジック統合
こういう「Google ネイティブな仕組み」をフル活用したくなります。
これは裏を返すと、
一度そこまで組み込むと、
OpenAI / Anthropic / OSS への乗り換えコストが一気に跳ね上がる
ということでもあります。
- エージェントのロジック
- ツール呼び出し部分の仕様
- モデル間の役割分担
これをベンダーの世界観どおりに作り込んでしまうと、
数年後の価格改定や品質変化に対して、身動きが取りづらくなるリスクがあります。
「中の人しかわからないブラックボックス感」
現時点で公開されていないものが多いです:
- パラメータ数
- 具体的な推論アーキテクチャ
- 1.5 Flash / 2.5 Flash との定量比較(精度・レイテンシ)
エンタープライズでよくある
「なぜこのモデルを選んだのかを、社内で説明しないといけない」
という場面で、
資料ベースだけでは説得材料が弱いのは正直つらいところです。
結局、
- 自前でベンチマーク
- 自社データで評価
- 長期的な挙動もモニタリング
をやるしかないのですが、
このコストを払えないチームは「なんとなく最新だから」で選びがちで、
それはそれで危うい。
Reasoning の“天井”問題
Gemini 3 Flash はあくまで「速さ・スループット寄り」。
- 深い推論が必要なケース
- 巨大なコードベースの変更
- 複数ドキュメントをクロスリファレンスしながら長いレポートを書く
こういうものは、
依然として Pro / Ultra クラス、あるいは GPT‑4o / Claude Opus みたいな「重いモデル」の領域です。
現実には、
- なんでもかんでも Flash に投げる
- 「まあ動いてるし、コスト安いからいいか」で済ませる
こうなりがちなので、
じわっと品質が下がっているのに誰も気づかないパターンが怖いです。
正直、「思ったよりちゃんと動くからこそ、
Flash に任せすぎてしまう」危険があると感じています。
プロダクションで使うか?正直まだ「戦略的に様子見しつつ導入」くらいが妥当
エンジニア視点での結論をはっきり書くと:
「全面採用」ではなく、「二段構成の Executor として積極的に試す」くらいがちょうどいい
くらいのポジションだと思っています。
こういうチームは今すぐ試したほうがいい
- すでに GCP / Vertex AI を使っている
- GPT‑4o-mini / Claude Haiku あたりで本番を回している
- 「レスポンス 500ms〜1s 以内で、高 QPS さばきたい」ユースケースがある
- マルチモーダル(画像 / PDF / 動画フレーム)を大量処理したい
この場合は、
- 今使っている「速いモデル」を
gemini-3-flashに差し替えたブランチ を作る - 以下をちゃんと測る
- p95 レイテンシ
- 1K トークンあたりの実コスト
- 自社タスクにおける正解率 / 受け入れ率
- うまくいけば Executor(ワーカー)として本番導入
- 複雑なタスクは Pro / 他社モデルへのエスカレーションを設計
このくらいの「冷静な PoC〜限定導入」がベストだと思います。
こういうチームは、もう少し様子見でもいい
- すでに OpenAI / Anthropic にかなり深く寄せたアーキテクチャを持っている
- クラウドは AWS / Azure がメインで、GCP はほぼ触っていない
- 社内的に「ベンダーロックイン」をすごく嫌う文化がある
この場合、
Gemini 3 Flash に乗り換えるための「組織的コスト」が重くなりがちなので、
- まずは 抽象化レイヤ(LLM クライアントの共通インターフェース)の整備
- そこで
- gpt‑4o-mini
- Claude Haiku
- Gemini 3 Flash
あたりを横並びで差し替え可能にしてから評価、
くらいの方がダメージが少ないです。
最後に:Gemini 3 Flash は「モデル」ではなく「設計のインパクト」で評価したい
Gemini 3 Flash の評価軸を「精度が GPT‑4o-mini とどっちが上か?」だけにしてしまうと、
たぶん議論がすごくつまらなくなります。
それよりも、
- LLM を「Planner / Executor」に役割分担する設計が前提になった
- 高速・高スループットモデルが、クラウドと強く結びついたエコシステム争いの主戦場になった
- 「モデルがあとから劣化するかもしれない」ことを前提に、抽象化と評価体制が必要になってきた
このあたりの アーキテクチャと運用のパラダイムシフト の引き金として見ると、
Gemini 3 Flash のインパクトはかなり大きいと感じています。
ぶっちゃけ、
「一番賢いモデルを 1 個だけ選ぶ時代」はもう終わりかけていて、
「用途ごとに複数モデルを組み合わせ、しかもいつでも差し替え可能にする」設計
を前提にしないと、3〜5 年スパンで詰む
Gemini 3 Flash は、その現実をかなりストレートに突きつけてきたモデルだと思います。
個人的なアクションプラン(エンジニア向け)
- まずはサンドボックス環境で:
- 既存の「速いモデル」の呼び出しを
gemini-3-flashに差し替えてみる - ツール実行・JSON 出力の挙動をチェック
- ベンチマークスイートを用意して:
- 自社の代表的なプロンプトセットで横並び評価
- 本番アーキテクチャは:
- Planner = 高性能モデル
- Executor = Gemini 3 Flash / gpt‑4o-mini / Haiku など
を差し替え可能なかたちで設計する
「とりあえず全部 Flash に変えました!」は一番危ないので、
戦略的に冷静に、でも手は早く動かすくらいの距離感がちょうどいいかな、というのがベテラン目線の結論です。


コメント