「なんでTransformerは全部LayerNormなんだよ、BatchNormで統一してくれよ…」
そう心の中でツッコんだこと、ありませんか?😇
画像モデルばかり触ってきたエンジニアがNLPやLLMのコードを開くと、だいたいこうなります。
# CNN 時代の感覚 nn.Conv2d(...) nn.BatchNorm2d(...) # Transformer の世界 nn.Linear(...) nn.LayerNorm(...)
同じ「正規化」なのに、世界が切り替わったようにAPIが変わる。
そしてググるとお決まりの説明が並ぶわけです。
「系列長が違うから BatchNorm は使いづらい」
「バッチサイズが小さいと BatchNorm は不安定」
…いや、それはそうなんだけど、それだけ? と正直モヤモヤしませんか。
この記事は、そのモヤモヤを「システム設計」の視点から殴りにいきます。
結論から言うと、
Transformer に BatchNorm が合わないのは、小バッチだからではなく、「計算モデルがバッチに依存してほしくない」から
だと考えています。
一言で言うと、「グローバル状態 vs ローカル関数」の戦い

一言で例えるなら、
BatchNorm vs LayerNorm は、
「グローバル状態を読む関数」 vs 「完全にローカルな純粋関数」
みたいな構図です。
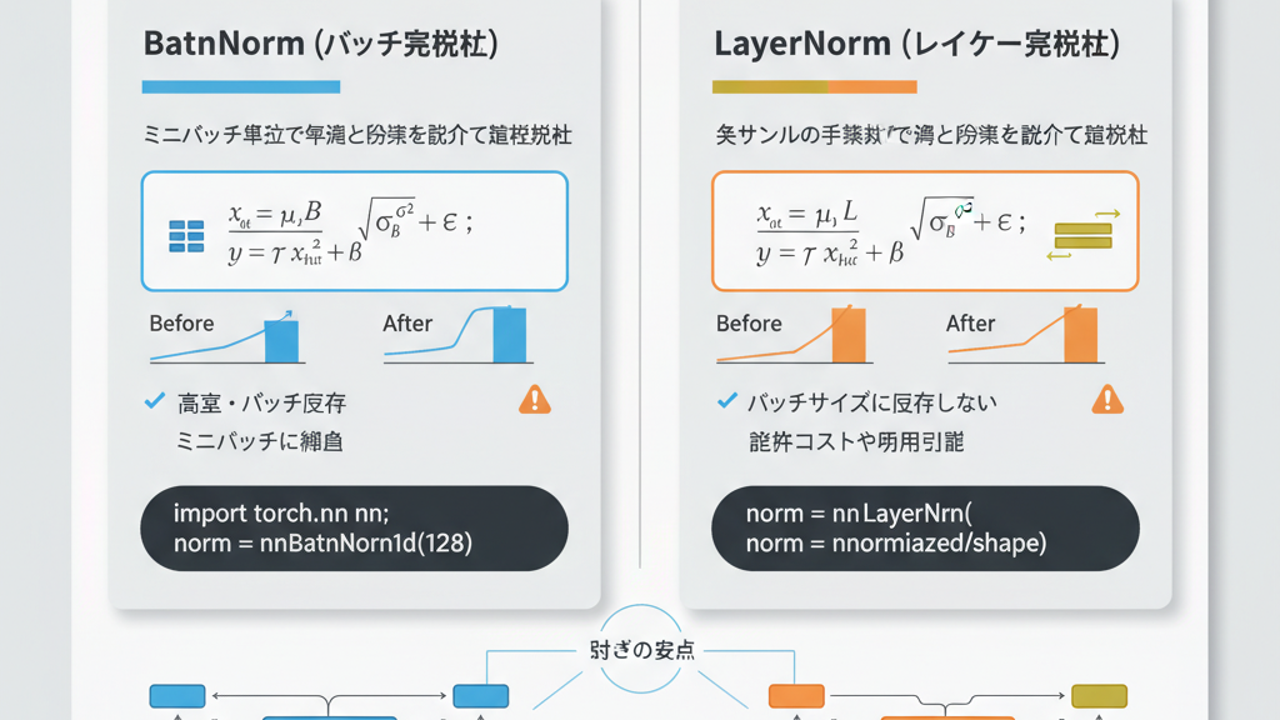
- BatchNorm
- 各サンプルの出力が「バッチ内の他サンプル」に依存
-
つまり「グローバル状態(バッチ統計)」を読みにいく関数
-
LayerNorm
- 各サンプルの出力は、そのサンプルの特徴ベクトルだけを見て完結
- ほぼ「純粋関数」に近いローカル計算
Transformer は、
「各 token をできる限り独立に処理して、Attention でだけ相互作用させる」
という設計思想の塊です。
その世界観に、
「バッチ全体の統計を見ないと出力が決まらない層」を入れるのは、
正直、かなりアンチパターン寄りなんですよね…🤔
なにが違うのか?本当に大事なのは「どこで統計を取るか」
技術的な話はシンプルで、「どの軸で平均・分散を取っているか」だけです。
BatchNorm の発想:バッチ × 空間でまとめてならす
典型的な使い方をざっくり書くと:
- CNN なら
N × H × W(バッチと空間)で統計を取る - MLP なら
N(バッチだけ)で統計を取る - 統計は「ミニバッチ全体で共有」
つまり、
あるサンプルの出力が、同じバッチに入っている他のサンプルに依存する
という設計になっています。
これ、画像ではめちゃくちゃうまくハマります。
- 同じ「チャンネル + 位置」を、違う画像で平均化
- ノイズが消えて、勾配も安定
- 大規模バッチが取れるGPU環境ならなおさらおいしい
だからこそ、CNN 全盛期には
「とりあえず BatchNorm 入れとけ」が正義
みたいな時代がありました。
LayerNorm の発想:1 サンプルの特徴ベクトルだけで完結
一方で LayerNorm は軸が真逆です。
- 1 サンプル、1 token ごとに
- その特徴ベクトル
x_t ∈ R^{d_model}の 特徴次元方向だけ で平均・分散を取る - バッチも系列長も見ない
つまり、
各 token の出力は、その token 自身のベクトルだけで決まる
ここが本質的に Transformer と噛み合うポイントです。
なぜ Transformer に BatchNorm が「根本的に」合わないのか

よくある説明は、
- 可変長シーケンスだから
- 小バッチだから
- 分散学習だと SyncBatchNorm が面倒だから
全部事実なんですが、どれも「局所的な不便さ」の話に止まっています。
個人的には、もっと根っこにあるのはこれだと思っています:
Transformer は「token ごとの処理を極限まで独立にしたい」
だから「バッチを跨ぐ統計」に依存する設計とは、概念的に衝突している
もう少し噛み砕きます。
Token 中心の計算モデルと、バッチ依存の統計のズレ
Transformer の 1 層を雑に書くと:
for each token t:
h_t = SelfAttention(x_1...x_T) のうち t に対応する部分
h_t = x_t + h_t # residual
h_t = LayerNorm(h_t)
z_t = FeedForward(h_t)
z_t = h_t + z_t # residual
z_t = LayerNorm(z_t)
ここで重要なのは、
- Self-Attention で token 間はちゃんと混ぜる
- でも その後の処理は token ごとにできるだけ独立 に進めたい
- だから FFN も LN も「token ごとに完結する」ように設計されている
ここに BatchNorm を入れるとどうなるか。
BatchNorm(h) # (batch, seq_len, d_model) を跨いで統計を取ることになる
これを真面目にやろうとすると、
- 同じ位置 t の token を、バッチ全体で平均する?
- それとも、バッチ × 全 token で平均する?
- padding や mask はどうする?
- streaming で1サンプルずつ来るとき、統計どうやって取る?
みたいな設計ノイズが、一気に雪崩れ込んできます。
正直、Transformer の綺麗なデータフローが一気に濁るんですよね…。
スループット最優先の並列化戦略と相性が悪い
実装レベルで見ると、Transformer の肝は「並列化しやすさ」です。
- 各 token の FFN は完全に独立 → GPU で爆並列
- LayerNorm も token ごとに完結 → そのまま並列
- 学習時も推論時も同じ計算 → カーネル最適化しやすい
BatchNorm を入れた途端、
- バッチ全体の統計計算 → 同期ポイントが増える
- DataParallel / DistributedDataParallel → SyncBatchNorm 必須
- 推論時は running mean / var → 学習時と挙動が変わる
となり、Transformer が本来持っている「スループットの気持ちよさ」が一気に削がれます。
ぶっちゃけ、
「Attention と FFN でいい感じに並列化したいのに、
なんで正規化層のために全 GPU 同期しなきゃいけないの?」
という気持ちになります。
そして、この「実装・並列化のしんどさ」は、LLM が数千 GPU で学習される時代になるほど、致命的なデメリットになっていきます。
なぜ「LayerNorm が勝った」のか:競合比較の視点で見る
ここまで聞くと、
「じゃあもう BatchNorm は時代遅れでオワコンなの?」
と言いたくなるかもしれませんが、そこまで単純ではありません。
まだ強い BatchNorm:CNN というホームグラウンド
画像系(ResNet など)では、未だに BatchNorm が強い世界が存在します。
- バッチサイズが大きく取れる
- 同じ空間位置を複数画像で平均化するのは理にかなっている
- フレームワーク・推論エンジン側の最適化資産が膨大
ここでは、
「ピクセル間の関係・バッチ間の関係は維持しつつ、チャネル方向だけ正規化」
という BatchNorm の設計が、タスクとちゃんと噛み合っている。
一方で、Transformer の世界では状況が真逆です。
Transformer の世界での比較表
ざっくり整理すると:
| 観点 | BatchNorm | LayerNorm |
|---|---|---|
| 統計を取る軸 | バッチ × (空間/系列) | 各サンプルの特徴次元だけ |
| サンプル間依存 | 強く依存(グローバル状態) | 依存なし(ローカル) |
| 学習 / 推論の挙動 | 別(バッチ統計 vs running mean) | 同じ |
| 可変長シーケンス | 面倒(padding, mask, 長さ差) | 自然 |
| 分散学習 | Sync が必要で複雑 | そのままスケール |
| ストリーミング / オンライン推論 | 相性悪い | 相性良い |
Transformer の設計要求を並べると、
- token 中心(token-centric)
- サンプル独立
- 分散前提
- ストリーミングも視野
- 推論パイプラインをシンプルに保ちたい
どう見ても、LayerNorm の圧勝なんですよね。
なので、
「小バッチだから LayerNorm」ではなく、
「Transformer の計算モデルが、そもそもバッチ非依存の正規化しか受け付けない」
と見る方が筋が良いと思っています。
「LayerNorm だけ信仰」にも落とし穴はある
ここまで LayerNorm を持ち上げてきましたが、もちろん欠点もあります。
正直、ここを無視して「全部 LayerNorm でいいじゃん」と言い切るのも危ないです。
計算コストとスケーラビリティ問題
- token × サンプルごとに平均・分散を計算
- 超長シーケンス・超巨大モデルだと、そこそこのオーバーヘッド
この現実があるからこそ、最近の LLM では
- RMSNorm(分散を計算せず、二乗平均だけ)
- ScaleNorm などの簡略版
が採用され始めています。
「LayerNorm 自体も、もう“最終解”ではなくなりつつある」
というのは、実務的には意識しておいた方が良いポイントです。
表現の自由度を削る懸念
LayerNorm は「特徴次元全体を一気にスケール」するので、
- 絶対値に意味がある表現(カウント、ログ確率など)
- 特定次元の絶対スケールを維持したいケース
では、余計なお世話になる可能性があります。
Transformer の文脈ではだいたいメリットに振れますが、
カスタムアーキテクチャでなんでもかんでも LayerNorm を挟むのは、正直ちょっと怖いです。
Pre-LN vs Post-LN 問題という地味に面倒な世界
Transformer では、
- Post-LN(元論文の形):
x + Sublayer(x)の後で LayerNorm - Pre-LN:
LayerNorm(x)をしてから Sublayer、最後にx + Sublayer(LN(x))
という2派閥があって、
- Post-LN は学習不安定になりやすい
- Pre-LN は安定するが、学習ダイナミクスや最適点が少し違う
など、微妙なチューニング論争が継続中です。
つまり、
「LayerNorm を選んだ瞬間に、Residual との組み合わせ設計までセットでついてくる」
という、地味だけど無視できない設計負債もあるわけです。
じゃあプロダクションでどうする?個人的な結論
ここまで踏まえて、現場目線での自分のスタンスはこんな感じです。
Transformer 系(LLM / BERT / seq2seq / encoder-only…)
- 基本は LayerNorm or RMSNorm 一択
- 「BatchNorm を試す」は、正直かなりニッチな研究用途だと割り切るべき
- 特に以下では LayerNorm 系以外を選ぶ理由はほぼない:
- 分散学習(マルチGPU / TPU)
- オンライン推論 / ストリーミング
- 可変長シーケンス
- モデルエクスポート(ONNX / TensorRT / on-device)
CNN / 画像タスク
- まだまだ BatchNorm は現役
- 大きなバッチが取れる
- 既存資産・最適化済みカーネルが豊富
- ただし、
- 小バッチ
- 分散同期が難しい環境
- edge / モバイル推論
では、GroupNorm / LayerNorm / InstanceNorm を検討した方がよいフェーズにきていると思います。
カスタムアーキテクチャでの「雑 BatchNorm」には要注意
一番危ないのはこれです。
画像で BatchNorm に慣れているエンジニアが、
reflex で「とりあえず BatchNorm 差しておくか」とやるパターン
Transformer ライクな構造(token ベース、可変長、分散前提)が混ざると、
かなり高確率で設計と実装が歪みます。
正直、今の時代の「デフォルト正規化」は、
- CNN → まだ BatchNorm 優勢
- Transformer / LLM / sequence → LayerNorm / RMSNorm 優勢
くらいにコンテキスト依存で切り替えるのが現実的だと思っています。
まとめ:なぜ Transformer は LayerNorm なのか、もう一度

あらためて整理すると:
- 理由は「小バッチだから」ではない
- 「バッチに依存しない token-centric な計算モデル」 だから
- BatchNorm は「バッチ統計というグローバル状態を読む関数」
- LayerNorm は「各サンプルの特徴ベクトルだけを見るローカル関数」
- Transformer の設計思想は後者と強く整合している
- 分散学習・ストリーミング・推論パイプラインの単純さという点でも、LayerNorm が圧倒的に扱いやすい
なので、
Transformer に BatchNorm をねじ込むのは、「グローバル状態バンバン読む関数」を FP ライクなパイプラインに混ぜるようなもの
という感覚を持っておくと、変な設計を避けやすくなると思います。
個人的な「今後の見立て」
- LLM 文脈では、LayerNorm から RMSNorm などへの移行はじわじわ進む
- それでも「バッチ非依存ノーマライゼーション」という軸はほぼ不動
- 「なんでも BatchNorm」の時代は、もう完全に終わった
プロダクションでどうするか?と聞かれたら、
- Transformer 系 → LayerNorm / RMSNorm を素直に採用
- CNN 系 → まだ BatchNorm も現実解。ただし小バッチ環境では他手法も検討
- 「とりあえず BatchNorm」は、正直もう封印した方がいい
というのが、今のところの本音です💡


コメント