
「RAGでサービス作りたいけど、日本語コンテンツを合法的に使えるまともなデータソースがない…」
そう嘆いたこと、ありませんか? 僕はあります。何度も。
スクレイピングはグレー、出版社との個別交渉は重すぎる、かといってWikipediaだけじゃ精度もリッチさも足りない。
その一方で、LLMベンダーは「学習データは企業秘密です✋」で押し通す。開発者としては、だいぶ消耗する構図です。
そんな中で始動したのが、note発・国家プロジェクト「GENIAC」と「RAGデータエコシステム」。
これ、ただの「RAGはじめました」じゃなくて、AI時代の“iTunes”を、本気でインフラから作りにいっているプロジェクトなんですよね。
一言でいうと:AI界の「iTunes / Spotify」を、日本語コンテンツでやろうとしている
一言でまとめると、
「AIが記事を参照したら、権利者にお金が落ちるようにする、RAG版のiTunes/Spotify」
です。
歴史のアナロジーでいうと、今のAI×コンテンツの世界って、完全にNapster時代なんですよね。
- 勝手にクロール
- よく分からないデータセット名(なんとかCorpus)
- 誰にいくら還元されてるのかは霧の中
GENIAC+RAGデータエコシステムは、ここに
- ちゃんと権利処理されたコンテンツだけを集めて
- その利用履歴をトラッキングして
- 使われた分だけお金を分配する
という、AI時代のDRM+ロイヤリティ分配インフラを持ち込もうとしている。
しかも、note単体のSaaSじゃなくて、経産省+NEDOの国家プロジェクト枠で。
この「技術仕様」と「権利のルール」を同じフレームで設計してるのが、正直かなり本気度高いんですよね。
なにがそんなにヤバいのか:単なる「RAG導入」ではない3つのポイント
技術・ビジネス両方を見てるエンジニア視点で、ここが本質だなと思ったのはこの3つです。
「対価付きRAGエコシステム」という発想そのものが新しい
従来のRAGスタックって、ざっくりこうでしたよね:
- どのデータを突っ込むか → ユーザー任せ
- それが著作物かどうか → 知らん
- 誰にいくら払うか → 知らん
つまり「RAG基盤はあくまでパイプ。権利処理とお金は外部の問題」ってスタンス。
対してGENIACのnote案は最初から、
- コンテンツ提供者(出版社/noteクリエイター)が
- 明示的に「AI学習・RAG利用」をON/OFFできて
- 使われた分だけレベニューシェアを受け取る
というところまでをRAGプラットフォームの責務として設計してる。
ぶっちゃけ、ここまでやるRAGプロジェクトは世界的にもほぼ見たことがないです。
「国家プロジェクト」として制度設計ごと実装しにいっている
さらにややこしいのがここで、これは
- 単なるnoteの新機能でもなければ
- ただの「AI活用宣言」でもない
んですよね。
- 経産省・NEDOのGENIAC枠として
- ルール(ガイドライン、契約の型)
- 技術基盤(RAG+トラッキング+メータリング)
- 収益分配ロジック
までまとめて作りに行く。
つまり「プロトコル+プラットフォーム+ビジネスモデル」をワンセットで設計するプロジェクトです。
これ、検索エンジンやLLMベンダーは基本やりたがらない領域なんですよね。
広告モデルと相性悪いし、グローバルな一枚岩ルールを作るのはほぼ不可能だから。
日本語圏というスコープで国家プロジェクトとしてやる、というのは、ある意味「ショートカット」を取りに行ってるとも言えます。
実運用前提の「RAGサプライチェーン」設計
机上のRAGプロジェクトと違うのは、
- 既に巨大なコンテンツ基盤(note)
- 出版社/学術団体/Webメディア
- それを使いたいAIサービス事業者
という具体的なサプライチェーン全体を最初から対象にしている点です。
「ベクタDB作りました、API公開します」ではなく、
- クリエイターUIでの許諾ON/OFF
- バックエンドでのメタデータ管理
- RAG検索側でのフィルタリング
- 利用ログのトラッキング
- 月次のアトリビューションと分配
まで含んだ「RAGデータ・インフラ」を国家プロジェクトで仕立てる。
正直、このレイヤまでやらないとAI×著作権の問題は解けないので、やっとそこに手が付いたか…という感覚です。
Googleと何が違うのか:検索 / Geminiとのガチ比較

「でも、どうせGoogleもそのうち同じことやるでしょ?」と思うかもしれません。
ここは一度整理しておいたほうがよくて、ざっくりこういう構図です。
スコープの違い:Web全体 vs 権利処理済みクローズド・ユニバース
- Google/Gemini
- Web全体をクローリング
- 検索やGemini回答で横断的に参照
-
出典リンクは出すけど、基本は「引用レベル」
-
GENIAC+RAGデータエコシステム
- スタート時点のスコープは「ニュース/辞書/実用書/ビジネス/マネー投資」などのファクト系コンテンツ
- 将来はもっと広げる前提だが、いずれも契約ベースで権利処理されたクローズドなデータ空間
つまり、「なんでも入ってる代わりにグレーも多いGoogle」 vs 「クリーンだが範囲が限定されたGENIAC」という構図です。
ビジネスモデルの違い:広告 vs 利用料+ロイヤリティ
- Google:
- 情報アクセスは基本無料
- マネタイズは広告 or 一部サブスク
-
出版社側へのお金の流れは、かなり限定的
-
GENIAC:
- 情報アクセス(RAGのAPI利用)に対価が発生
- その一部が出版社やクリエイターに分配される設計
- 要するに「AIへのデータ提供が、そのまま収益源になりうる」
この差は、エコシステムの空気をだいぶ変えます。
正直、今の「AIは勝手に学習するけど、お金はほとんどプラットフォーマーにしか落ちない」構図は、音楽業界で言うところのNapster〜初期YouTube時代に近い。
GENIACは、そこにSpotify型の「正規ルート」を作ろうとしている。
誰が一番「怖い」はずか:本当に打撃を受けるプレイヤー
一番プレッシャーを感じるべきなのは、GoogleでもOpenAIでもなく、たぶんこんなプレイヤーたちです。
無許諾スクレイピング前提の「なんでもRAGサービス」
- 個人ブログ/まとめサイト/ニュースサイトをゴリゴリクロールして
- 独自の日本語ベクタDBを作り
- 「高精度な日本語RAG検索です」と売っている系のサービス
これらは、法的にもビジネス的にも正当性がかなり揺らぐことになります。
- GENIAC経由なら「権利処理済み+対価還元」のRAGソースが手に入る
- にもかかわらず「うちは黙ってスクレイピングしてます」は、ユーザー企業から見てかなり使いづらくなる
特に金融・医療・公共分野のようなリスクに敏感な領域は、コンプラ的にGENIAC側へ流れていく可能性が高いです。
「技術だけ」のRAGデータプロバイダ
FaissでもWeaviateでもPGVectorでもいいんですが、
- ベクタDB
- セマンティック検索API
だけを提供していて、
- 著作者との契約
- ロイヤリティ分配
- ガイドライン
といったレイヤは完全にノータッチ、というプレイヤーも、長期的には差別化が難しくなります。
正直、RAGの“技術”だけなら、既に完全なレッドオーシャンです。
そこに「権利処理」「分配」「トラッキング」を一体化したGENIACモデルが来ると、「ちゃんとした用途」ほどGENIAC側を選びやすくなる。
技術的にはどうなっているのか:RAG+トラッキングの裏側
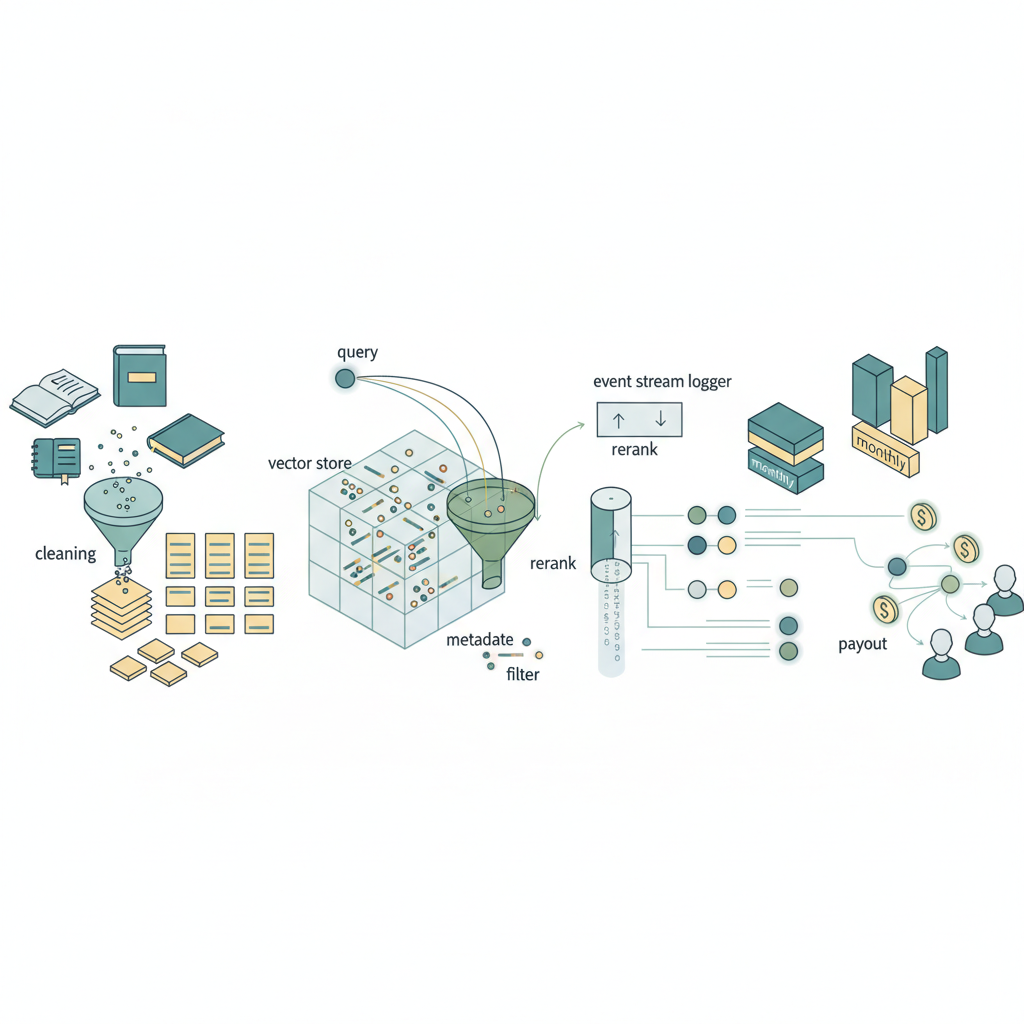
ざっくり、技術アーキテクチャをエンジニア視点で砕くとこうなります。
- noteや出版社・学術団体などからのコンテンツを
- 正規化・クリーニング
- チャンク分割
- 埋め込み生成(Embedding)
- メタデータ付与(クリエイターID/許諾状態/カテゴリ…)
- それをベクターストアに格納し
- クエリに合わせてk-NN/ANN検索
- 許諾済みコンテンツだけをメタデータフィルタ
- 必要に応じてRerank
- ここまでは普通のRAGですが、そこからさらに
- 「どのリクエストIDで、どのcontent_idが、どのスコアでretrievalされたか」
- をイベントストリーム(Kafka的なもの)にログ
- 月次などで集計して、コンテンツごとの「寄与スコア」を計算
- それに基づいてロイヤリティ分配
という、「usage_log → attribution → payout」のフルパイプを作るイメージです。
ポイントは、LLM出力そのものではなく、retrieval段階のログをベースに分配するしかないという割り切りがほぼ必須なこと。
ここは後で「Gotcha」で触れますが、技術的にはかなりチャレンジングです。
ただ、懸念点もあります…🤔
ここまで持ち上げておいてなんですが、「GENIAC最高!全乗り換えだ!」とはさすがに言えません。
現時点で見えている「これは詰まりそうだな」というポイントも、かなりあります。
トラッキングと分配は、そもそも「完全公平」は無理ゲー
LLM+RAGの世界で「どのコンテンツがどの回答にどれだけ寄与したか」を厳密に求めるのは、ほぼ不可能です。
- RAGで取得されたコンテンツA〜Eを
- LLMが統合・要約し
- さらにモデル内部のパラメータ知識も混ざって出力
みたいな世界で、「この回答の37%はコンテンツID 1234の貢献です」とかやり出すと、研究テーマになってしまう。
現実的には、
- 「その回答で参照されたチャンクにスコア比で分配」
- 「request単位の重み付けで集計」
みたいなかなり粗い近似にせざるをえないはずで、
- 「自分の記事がほぼそのまま引用されているのに、分配額が少ない」
- 「逆に、ほとんどノイズだったのに分配されている」
みたいな不満は、正直かなり出ると思います。
ここをどこまで透明化するか、ルールをどこまでシンプルに割り切るかは、エコシステムの信頼性を左右するポイントになりそうです。
コスト構造:AI事業者から見て「高くつくRAG」にならないか
AIサービス側から見ると、
- すでにLLM APIコストがそれなりに高い
- そこに加えて、GENIACのRAGデータ利用料+コンテンツロイヤリティが乗る
という構造になります。
つまり、
オープンWeb勝手RAG(グレーだけど安い)
vs
GENIAC RAG(クリーンだけど高い)
のコスト比較が、かなりシビアに効いてきます。
特にB2C向けの薄利サービスだと、
- Google検索+Gemini+自前RAGで「まあまあの回答」が出せるなら
- GENIACまで使う価値がどれだけあるか?
という経営判断になります。
この「価格設定」と「リーガルリスク」のバランスをどう設計するかは、エンジニアというより事業サイドの腕の見せどころですが、普及を左右するド直球のボトルネックです。
データ量と多様性:クリエイターがどれだけ「ON」にしてくれるか問題
いくら仕組みが良くても、
- クリエイターや出版社が「AI利用許可」をONにしてくれなければ
- RAGデータベースはスカスカなまま
というリスクがあります。
そして、クリエイター側の判断軸はかなりシンプルで、
- RAG経由の収益分配がどれくらい現実的な金額になるのか
- note本体でのPV/スキ/有料販売と比べて魅力があるのか
- AIに要約・再構成されることに心理的な抵抗がないか
このあたりが見えないと、「とりあえずOFFにしとこ」がデフォルトになりかねない。
ぶっちゃけ、「月数十円〜数百円」のレベル感だと、わざわざ許諾をONにするインセンティブが弱い可能性はあります。
プロダクションで使うか? 正直、今は「様子見しつつ、API仕様を睨む」フェーズ

現時点(2025年末)で、エンジニアとしてどう向き合うかを、かなり現実的にまとめるとこんな感じです。
僕の結論(暫定)
- 思想と方向性にはかなり賛成
- Napster時代からSpotify時代へのシフトは、いずれ必ず来る
- それをAI×日本語コンテンツでやろうとしているのは、評価したい
- 技術的にも、ようやく「権利込みRAG-as-a-Service」が見えてきた
- 自前で権利処理と分配までやるのは、ほとんどのスタートアップにとってコストオーバー
- そこをGENIACが肩代わりしてくれる可能性は、大きい
が、プロダクションで今すぐメインデータソースとして採用するか?と聞かれると、
「正直、まだ様子見。ただし、PoCで触りながらAPIのクセとコスト感は押さえておきたい」
というのが、今の本音です。
これからエンジニアとしてやっておくと良さそうなこと
- GENIAC側が出してくるAPI/SDKのインターフェースをウォッチする
semantic_searchなのか- 直接
context付き回答生成なのか -
usage_logへのアクセス権限や粒度はどうなっているか
-
既存のRAGスタック(LangChain/LlamaIndexなど)から差し替えられる設計にしておく
- 「データソースを抽象化するレイヤ」をちゃんと作っておく
-
将来
NoteGenicVectorStoreみたいなクラスを差し込める余地を残す -
リーガル・コンプラにうるさい業界の案件では、GENIACを前提にしたアーキテクチャ案も用意しておく
-
「今はWebベースRAGだけど、将来GENIACベースRAGにスイッチしやすい」構成を提案しておくと、後々楽になります
-
自分がクリエイター側でもあるなら、noteでの「AI利用許諾」の設計を追っておく
- どの粒度でON/OFFできるのか
- 収益レポートがどれくらい細かく出るのか
- クリエイターとして「メリットあるわ」と思えるかどうかを、自分の感覚として持っておく
まとめ:GENIACは「AI時代のiTunes化」を日本語から始める実験場になる
整理すると、このプロジェクトの本質はこうだと思っています。
- AI×著作権の世界は、いままさにNapster期
- どこかが「iTunes/Spotify期」への道を切りひらかないと、クリエイターは消耗するだけ
- GENIAC+noteのRAGデータエコシステムは、その最初の本格的な実験場になりうる
技術的なチャレンジも、ビジネス的な難しさも、正直てんこ盛りです。
完璧には回らないでしょうし、いろんな炎上もあると思います。
それでも、「AIがコンテンツを使ったら、ちゃんとお金とクレジットが戻ってくる世界」をガチで設計しにいくプレイヤーが、日本から出てきたのはポジティブに受け止めたい。
エンジニアとしては、「すぐ飛びつく」よりも、
- 仕様を見て
- コストを測り
- 既存RAGスタックとの接続ポイントを冷静に押さえながら
「いつでも乗り換えられる位置に陣取っておく」のが、2026年に向けた現実的な戦い方かなと思います。
そして、数年後に、
「あのGENIACが、AI時代のコンテンツ流通の転換点だったよね」
と振り返れるのか、それとも
「あれもまた、日本らしい“いい話で終わったプロジェクト”の一つだったね…」
になるのか。
その分かれ目は、僕たち開発者が「ちゃんと使いどころを見つけて、現場に組み込めるかどうか」にも、少なからずかかっているはずです。


コメント