
「LLMアプリ、危ないのは分かってるけど、
・プロンプトインジェクション対策
・ツールの権限制御
・ログとコンプラ対応
…この辺りを毎回フルスクラッチで作るの、もう限界じゃないですか?」
そんな空気感の中で出てきたのが、OpenAI が打ち出し始めた「ChatGPT Atlas」という構想です。
一言でいうと:「Docker時代」から「Kubernetes+Service Mesh時代」へのジャンプ

まず勘違いしがちなのですが、ChatGPT Atlas は「新モデル名」ではありません。
「GPT-4の親分」みたいなものでもない。
Atlas はもっとメタな存在で、
モデル+エージェント機能+安全フィルタ+ガバナンスをひっくるめた “統合スタック” 構想 に近いです。
一言でいうと、
「LLM界の Kubernetes+Service Mesh+Policy Engine を、OpenAI が丸ごと用意しようとしている」
という感じ。
- これまで:
- 「ChatGPT」というチャットUI
- 「GPT-4 API」というモデルAPI
- これから(Atlas 的な世界):
- モデル(GPT-4.x)
- エージェント(ツール利用・長期タスク)
- 多層のセーフティ(入力/出力/ツール/ログ)
をセットで「企業向けAI基盤」にしていく
正直、方向性としてはかなり妥当です。
生LLMを直接叩いてプロダクション運用する時代は、そろそろ終わりにした方がいい。
Atlas の「本当に新しいところ」はセーフティの“基盤化”
ニュース系の記事だとふんわり書かれがちですが、エンジニア目線で見ると一番インパクトがあるのはここです。
安全対策が「後付けフィルタ」から「プラットフォーム機能」へ
Atlas 的な構想では、安全対策をざっくりこう分解して考えています:
- 入力前フィルタ
- 有害コンテンツ検知(ヘイト、暴力、違法行為支援など)
- プロンプトインジェクションや越権リクエストの検出
- モデル出力のセーフガード
- 出力ポリシーチェック
- NG なら拒否応答やサニタイズに差し替え
- ツール利用の制限(Function Calling / Tool Use)
- 呼べるツールのホワイトリスト・スコープ
- 引数の検証(SQLインジェクション、権限チェックなど)
- 監査・ログ・ガバナンス
- どの入力に対して何が出力されたか
- どのツールがいつ、どんなパラメータで呼ばれたか
- テナント/ユーザー単位のポリシー管理
今まではここをアプリ側で全部作るしかなかった。
Atlas はこれを「プラットフォーム標準機能」として提供しますよ、という方向性です。
Kubernetes 登場前後を覚えている人なら分かると思いますが、
- 以前:
- nginx 設定もログ収集もスケーリングもアプリ側or手作業
- 以後:
- Service Mesh や OPA でトラフィック制御もポリシー制御も“基盤側で一括”
この構造変化が、そのまま LLM に来ようとしているイメージです。
「モデルが賢くなるほど危険になる」を前提にした設計
正直ここは、ちゃんと言葉にした OpenAI を評価しています。
- モデルが賢くなるほど:
- Jailbreak しやすくなる
- プロンプトインジェクションで機密情報を抜かれやすくなる
- 生成コードがそのまま攻撃に使えるレベルになる
- だから:
- 性能・コストだけでなく、「安全性そのものをKPIに入れる」と宣言している
GPU ベンチマーク一辺倒の時代から、
「安全スループット」という概念を持ち込もうとしているのは、地味に大きい変化です。
じゃあ、Google / Anthropic / AWS と何が違うのか?

Google (Gemini + Vertex AI) と比べると…
Google も Vertex AI で安全フィルタやガバナンス機能を売りにしています。
ただ、Google のスタンスはどちらかと言うと「クラウド基盤の一機能」としての AI。
OpenAI の Atlas は、
- ChatGPT という完成度の高いエンドユーザー向けUI
- GPT-4 系の高性能モデル
- API / Plugins / エージェントなどの開発者エコシステム
この全部を束ねた上で、「安全込みの統合スタック」を作ろうとしている。
ここが Google とは少し違います。
クラウドに AI を“載せる”Google に対して、
OpenAI は AI を“土台にして”プラットフォーム化しようとしている、という印象です。
Anthropic (Claude) と比べると…
正直、一番プレッシャーがかかるのは Anthropic だと思っています。
- 共通点:
- どちらも「安全性」を強く打ち出している
- モデル設計段階からセーフティを入れ込む思想(RLHF / Constitutional AI)
- 違い:
- Anthropic:
- モデル内部の「憲法(Constitution)」で安全性担保をアピール
- ただし、プラットフォームとしての統合運用機能は相対的に薄い
- OpenAI(Atlas):
- モデル+ツール+多層セーフティ+ログ+管理コンソールまでひっくるめて「基盤」にする方向
- 「安全=モデルの性格」だけでなく、「安全=運用スタック全体」として扱う
ぶっちゃけ、「安全性だけ」をUSPにしているベンダーはかなり厳しくなると思います。
Atlas が軌道に乗ると、
「高性能モデル+安全+運用基盤」がセットで“デフォルト”になってしまうので。
AWS Bedrock みたいな「マルチモデル+ポリシー管理勢」は?
ここも影響は大きいですが、性質が少し違います。
- Bedrock:
- いろんなモデルをまとめてポリシー管理・監査・ログをかけられる
- 「マルチベンダー・マルチモデル+ガバナンス」が売り
- Atlas:
- まずは「OpenAIモデル前提」で深く入り込む
- ベンダーロックインと引き換えに、きめ細かいセーフティ & 機能統合を狙う
「広く薄くマルチモデル」vs「狭く深くOpenAIスタック」の戦いになるイメージです。
一番の“罠”は、「安全だから任せてOK」と誤解されること
良い話ばかりしても現実的ではないので、落とし穴も書いておきます。
ベンダーロックインは確実に強くなる
セーフティ/監査/ポリシー管理が Atlas レイヤーに深く埋め込まれるほど:
- 乗り換え時に必要になるのは「モデルAPI差し替え」ではなく、
- ポリシー定義の再設計
- 監査ログフォーマットの移行
- 内部統制プロセスの再構築
- つまり、アプリロジック以上に「運用とガバナンス」が OpenAI 仕様に縛られることになります。
正直、「Atlas までべったり依存してからマルチベンダーに切り替える」は、
Kubernetes + Istio どっぷりの世界から「やっぱり全部ECSに戻します」と言うくらいの大工事になりそうです。
「安全=自動的に保証」と思い込む経営層問題
一番怖いのはここかもしれません。
Atlas 的な安全機能が前面に出れば出るほど、
非技術層からはこう見え始めます:
「OpenAI が安全対策やってくれるなら、うちは気にせず使っていいんだよね?」
でも現実には:
- 医療・金融・公共分野ごとのドメイン固有リスク
- 国ごと・業界ごとのコンプライアンス要件
- 自社内ルール(内部統制、情報区分、監査要件)
これは全部、アプリ側・組織側の責任です。
Atlas がどれだけ頑張っても、
- 「この患者の病歴を、このタイミングで、どの部署まで見せていいのか?」
- 「どのログを何年間、どのリージョンに保存するのか?」
といったレベルの判断まではやってくれません。
ここを混同すると、「責任の所在があいまいなまま本番運用」という最悪パターンにハマります。
コストとレイテンシのトレードオフ
多層セーフティは、ほぼ確実に:
- 追加の推論ステップ(セーフティモデルの呼び出し)
- ログ出力・監査処理のオーバーヘッド
を伴います。
Atlas レベルのセキュリティ設定をフルでONにすると、
- 大規模エンタープライズ:
- 「そのコストを払っても安心・コンプラ優先」が理にかなう
- 小〜中規模サービス:
- 「そこまでの安全レイヤーはいらないから、シンプル構成で安く早く動かしたい」
というケースも普通にありえる
ぶっちゃけ、“Atlasフル装備”が常に正解とは限りません。
「どこまで Atlas に任せて、どこからは自前でやるか」を選べる設計がないと、コスパ的に苦しくなる場面は確実に出ます。
複雑さとブラックボックス化
セーフティが高度化・多層化するほど:
- 「なぜこの出力がブロックされたのか?」
- 「どのルールがヒットして拒否になったのか?」
を開発者が理解しづらくなります。
WAF や Zero Trust をがっつり入れたシステムでありがちですが、
- 実運用で「正当なユースケース」が弾かれているのに原因が追いにくい
- 微妙なグレーゾーンのルール調整が地味にしんどい
Atlas も同じ罠にはまりうる。
UI で「安全度スライダー」を動かして終わり、みたいな抽象化だけだと、現場では結構つらいはずです。
開発者として Atlas をどう見るべきか?
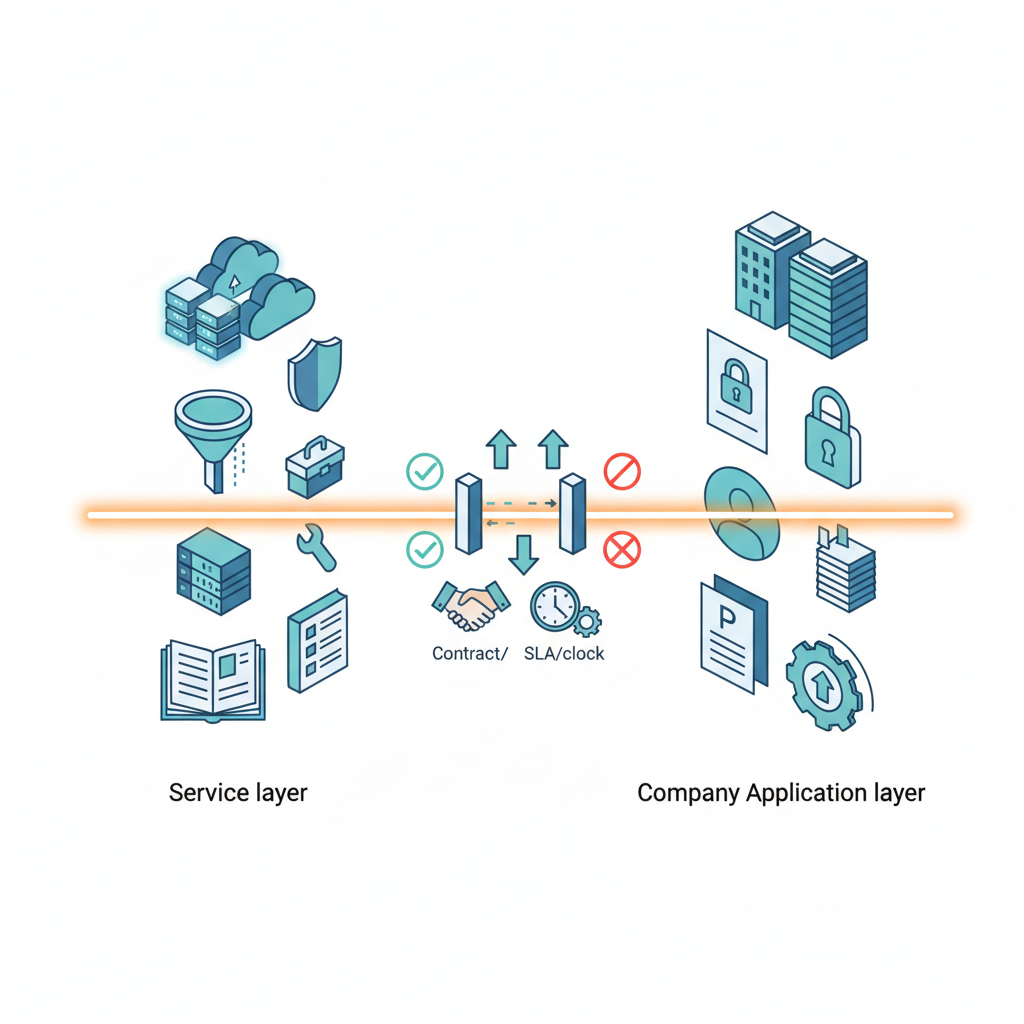
「じゃあ、プロダクションで Atlas 的な世界観に乗るか?」という話ですが、
正直なところ、僕のスタンスはこんな感じです。
使う前提で、“境界設計”に頭を使うべきフェーズ
- 完全スルーして「生LLM+自前ガード」で走り続けるのは、長期的にはしんどい
- とはいえ、「セーフティもガバナンスも全部 OpenAI 任せ」はリスクが大きすぎる
なので現実的には:
- Atlas 側が担うレイヤーを整理する
- 入力・出力の基本的な有害性フィルタ
- ツール利用の最低限のスコープ制限
- ログ取得と監査の土台
- 自社で追加すべきレイヤーを洗い出す
- ドメイン特化ルール(例:金融商品の具体的な勧誘表現など)
- 社内情報区分(社外秘/社内限定/個人情報 等)の扱いルール
- 社内監査部門からの要求(保持期間、アクセス権管理)
- 「Atlas 層」と「自社アプリ層」の責任境界を設計する
- どこまで OpenAI に任せ、どこから先は自分たちの責任とするか
- 契約・SLA・障害/事故時の対応フローまで含めて線引きする
この「境界設計」をちゃんとやる組織だけが、Atlas をうまく使えると思います。
いきなりフルコミットではなく、「部分採用+検証」から
個人的には、いきなり業務基幹システムを Atlas にフル乗せするのはおすすめしません。
- まずは:
- 社内向けアシスタント
- コードレビュー補助
- ドキュメント整理・検索
などのリスク低めのユースケースで、 - Atlas 的な多層セーフティ
- ログ・監査機能
がどこまで現場で役に立つかを検証する。 - そのうえで:
- 自社のコンプラ・監査チームと一緒に、
- 「Atlas 標準機能で OK な範囲」
- 「追加統制が必要な範囲」
をすり合わせていく。
この順番を踏まずに「ベンダーが安全って言ってるから」といきなり本番導入するのは、正直かなり危ないです。
結論:Atlas は「様子見」ではなく、「戦略的に距離を測りながら付き合う対象」
まとめると、僕の見立てはこうです。
- Atlas は新モデルではなく、「安全込みのLLMプラットフォーム像」
- セーフティを入力/出力/ツール/監査の多層でモジュール化する発想は正しいし、遅かれ早かれどこかがやるものだった
- ただし、「安全をプラットフォームに深く埋め込む」ことは、同時にロックインとブラックボックス化を招く
- 「OpenAI が安全だからOK」ではなく、「どこまでを OpenAI に任せるか」を設計するのが、これからの開発者の仕事になる
プロダクションで使うか?と聞かれたら、
「限定ユースケースから段階的に」が今の答えです。
正直、Atlas 的な世界観からは逃げられません。
問題は、「飲み込まれるか」「主体的に付き合うか」です。
開発者としては、
技術スタックの選定だけでなく、「安全と責任のアーキテクチャ」を設計する時代に入った、
その象徴的な一歩が ChatGPT Atlas なんだろうな、と思っています。


コメント