
「LSTMで機械翻訳組んだけど、長文になると一気に劣化してBLEUが伸びない…」
そんな経験、ありませんか?学習率いじっても、レイヤー増やしても、勾配クリッピングしても、どうにもならないやつです。
その問題を「前処理1行」である程度マシにしてしまう、古典的だけど本質的に面白いテクニックがあります。
Seq2Seqの入力文をまるごと反転するという、あの手法です。
「入力文を逆さにするだけ」で精度が上がるって正気?
一言で言うと、このテクニックは
RNNベースNMT界の「chrootでなんちゃってコンテナやってた時代の黒魔術」
みたいなものです。
Docker(= Transformer)が出る前、
- chroot
- 自作シェルスクリプト
- 手書きvirtualenv
でどうにか環境分離していた時代がありましたよね。
あれと同じ匂いがする「苦肉の策」なんだけど、理屈をちゃんと理解すると、今でも学ぶ価値がある。
Zenn の colorfulwave さんの記事は、この「入力反転ハック」を
勾配・距離・最適化ダイナミクスの観点から丁寧に言語化していて、古典テクニックの再評価としてかなり良いです。
でもこの記事で一番おもしろいのは、「へぇLSTMってそう動くんだ」だけじゃなくて、
- なぜこんな小技が翻訳者の仕事や
- AI時代の「人間の役割」への不安と
ガッツリつながっているのか、という点だと感じています。
何が起きているのか:平均距離じゃなくて「初速」をごまかすテクニック
技術の中身はシンプルです。
ふつうのSeq2Seq
入力: x = [x1, x2, x3, ..., xT]
出力: y = [y1, y2, y3, ..., yU]
単方向LSTMエンコーダが、左→右に読んで、最後の隠れ状態 h_T をデコーダに渡す、というオーソドックスな構造。
ここで面倒なのは、
- たとえば
x1 ↔ y1が対応するとき、
モデル的には x1の情報が LSTM を T ステップ通ってh_Tにたどり着き- さらにそこからデコーダ側で
y1までたどり着く
という長距離リレーになってしまうことです。
LSTMは長距離依存に強い、とは言うものの、勾配はやっぱり劣化します。
長文だと顕著で、「書き出し」からして怪しくなる。
入力を丸ごと反転させると?
ソースだけこう反転させます:
- もともと:
x = [x1, x2, ..., xT] - 反転後:
x_rev = [xT, ..., x2, x1]
ターゲット y は反転しません。
すると何が起こるか。
- 「ターゲット先頭
y1と強く対応しているソーストークン」が
エンコーダの最後のほうに来るようになります - つまり
「エンコーダの最後の入力」→「デコーダの最初の出力」
という最短距離のペアが1組は必ずできる
colorfulwave さんの記事がうまく言語化していたポイントは、
反転しても平均的な距離は変わらないけど、
一番近いペア(Minimal Time Lag)を意図的に作れる
という点です。
学習は平均からではなく、「一番カンタンなところ」から立ち上がるので、
この「書き出しだけは超近い」構造が、最適化の初速を劇的に上げてしまう。
- まず
a → αのような「短距離・簡単な対応」を覚える - そこを足がかりに、だんだん遠い
c → γみたいな依存も学ぶ
という、局所からグローバルへのブートストラップが起きるわけですね。
ぶっちゃけ、これは数式というより
「最初の1問だけは超サービス問題にしとくと、受験生のエンジンがかかりやすい」
みたいな受験テクと同じ発想です 🤔
テスト全体の平均難易度は変わらないけど、初動の心理とパフォーマンスが変わる。
Transformer全盛の今、なぜまだこの話をするのか?
正直、実務の新規プロジェクトで
「LSTM Seq2Seq を使って翻訳システムをゼロから作ります」
と言うのは、かなりチャレンジングです。
GPUもメモリもあるなら、普通はTransformerか、その派生を選びます。
Transformer は Self-Attention のおかげで
- どのトークンも他のトークンを1ステップで参照できる
- そもそも「位置による距離」の問題がかなり解消される
ので、「入力反転で距離を短くする」という発想自体が時代遅れになりました。
では、このテクニックは完全に死んだのか?
個人的にはむしろ「教育」と「レガシー保守」で価値が増していると感じています。
LSTMの「体感」を得る最高の教材
Transformerを最初から使うと、
- 「Self-Attentionが勝手に長距離依存を取ってくれる」
- 「位置情報はEmbeddingに埋め込むから、直感的な“距離”は意識しない」
となりがちで、
時系列モデルの痛みを一度も味わわないまま現場に出ることになりがちです。
でも現実のシステムはまだ、
- 音声
- ログ解析
- センサーデータ
などで、RNN系やその亜種にかなり依存しているところも多い。
そういうとき、「なぜ長距離がキツいのか」を身体で理解しているかどうかで、設計の質が変わります。
入力反転は、
「距離」と「勾配」と「最適化の初速」
をまとめて可視化してくれる、非常に教育的なネタです。
正直、大学や企業研修のNLP講義でLSTMを扱うなら、
Transformerより先にこれを一度やらせた方がいいとすら思っています。
レガシーSeq2Seqを“あと3年延命する”ための現実的ハック
現場にはまだ、
- 数年前に作った BiLSTM+Attention ベースの翻訳・要約システム
- 謎の自家製Seq2Seqが本番で動いているサービス
が普通にいます。
「全部Transformerに張り替えたいけど、
テスト・運用・認証・法規制まで含めてやると1年仕事なので、
今年は無理です…」
というプロジェクト、いくつも見てきました。
そういう現場で、前処理1行で
if reverse_source:
src = [list(reversed(s)) for s in src]
を入れるだけでBLEUが数ポイント上がるなら、
“延命のための微整形”としては十分に価値があると思っています。
Transformerに勝つ話ではなく、
「今あるLSTMベースの山を、
できるだけコスパよくなだらかにする」ためのツール
という位置づけです。
一方で、「翻訳者の仕事」が変わる現場の空気
コミュニティの反応を眺めていると、
話題はもはや「入力反転がスゴいかどうか」にはありません。
むしろ、
「こういう精度向上テクが積み重なった結果、
人間の翻訳者って、今どうなってるの?」
に意識が向いている。
典型的なのが、
「昔は翻訳者は高給取りだったが、
今はほとんどがAIの世話係で、
生成されたエラーを修正する仕事になっている」
という声です。
正直、これはエンジニア側も他人事ではありません。
- 機械翻訳
- コード生成
- ドキュメント自動生成
がどんどん賢くなっていく中で、
われわれも気づけば「LLMの出力ログを眺めて、変なところを直す人」になりかねない。
「エラー前提ツール」の時代に、人間の仕事はどう設計すべきか
Seq2Seq入力反転みたいなテクニックは、
単体で見ればただの前処理ハックです。
でもその積み重ねで、
- 翻訳の素の精度が上がる
- コスト的に「まずは全件機械翻訳 → 人間が後処理」がデフォルトになる
という流れを加速させてきたのは事実です。
その結果として現場で起きているのは、
- 「ゼロから自分の訳文を書く」 → 「AIの訳の粗を直す」
- 「自分の名前で勝負する成果物」 → 「誰の訳か分からない成果物の最終責任だけ持つ」
というロールチェンジ。
そして開発者の側も、
「とりあえずモデルを賢くする」だけを追うと、
人間の仕事が永遠のポストエディット地獄になる
という構図を無視しがちです。
個人的にここが一番の論点だと思っていて、
- ポストエディットしやすい出力
- エラーのパターンが読みやすいモデル
- “どこを人間に任せるか”が明確なワークフロー
まで含めて設計しないと、
「精度だけ上げて人間を消耗させるシステム」を量産してしまう懸念があります。
入力反転のようなテクニックは、
「モデルが迷子になりにくいようにデータを整形する」発想です。
同じくらい真剣に、
「人間が迷子になりにくいように、ワークフローを整形する」
ことを考えないと、技術だけが一人歩きする。
競合視点:Transformer vs Seq2Seq+入力反転
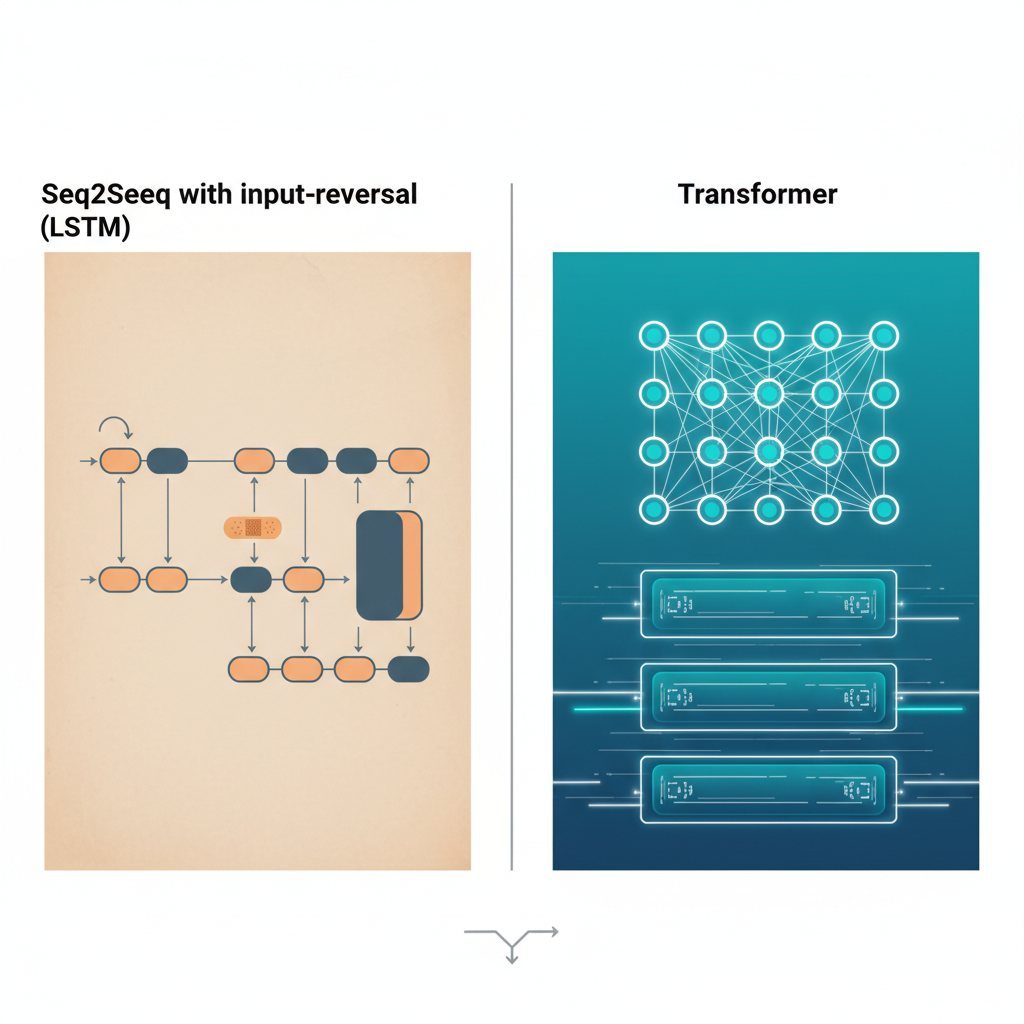
技術的な比較を雑にまとめるとこんな感じです:
| 観点 | LSTM Seq2Seq + 入力反転 | Transformer |
|---|---|---|
| 長距離依存 | 「一部だけ近くする」ローカルハック | 全トークン間を直接接続 |
| 実装コスト | 既存RNNに前処理1行追加 | 新アーキ導入・再設計が必要 |
| 並列計算 | 逐次処理で遅い | 高い並列性・高速 |
| 教育用途 | RNNの弱点・性質がよく見える | 距離の直感が掴みにくい |
| SOTA | もう追いつけない | 現状の主流 |
正直、Transformerがこの先「入力反転ごとき」に脅かされることはありません。
これはもう勝負がついている領域です。
むしろ競合するのは、
- 「現行のLSTM/GRUシステムを全面リプレースするか」
- 「もう数年だけハックで延命するか」
という組織内の意思決定です。
入力反転は、その延命サイドにとっての「安価なブースト剤」になり得る。
だからこそ、ちゃんと理屈を理解して、
どこまで頼るのか/どこからは諦めてTransformerに移るのかを、冷静に線引きした方がいい。
落とし穴もちゃんとある
持ち上げてばかりでもフェアじゃないので、Gotchaも挙げておきます。
- Transformerにはほぼ効かない
- Self-Attentionで距離問題はほぼ解決済み
-
「とりあえず全部反転」は、だいたい時間の無駄です
-
モデル解釈が人間の直感とズレる
- 可視化するときに、「ソースの先頭」と思っていた位置が、モデル的には「末尾」
-
アテンションマップ解釈がやや混乱する
-
学習済みモデルとの互換性ゼロ
- 既存モデルに推論時だけ反転かけても意味はなく、再学習必須
-
巨大データセットだと「反転由来の改善 vs 再学習コスト」は要検討
-
短文タスクでは旨味が薄い
- そもそものシーケンス長が短いと、距離短縮のメリットがほとんどない
- コード複雑化の割にゲインが見えないケースも多い
プロダクションで使うか?正直こう見る

自分ならどうするかを率直に書くと、こんな感じです。
新規開発で本気の翻訳システムを作るなら
- Transformer一択
- 入力反転は「歴史の教訓&勉強ネタ」として扱う
- チーム勉強会で一度実装して「距離」「勾配」「初速」の感覚を掴ませるのは強く推奨
既存のLSTMベースが本番で動いているなら
- まずはオフラインで入力反転版を試す価値はある
- 前処理1行+再学習でBLEU数ポイント上がるなら、延命策としてはアリ
- ただし、それを理由に
- 「じゃああと5年LSTMでいきましょう」は危険
→ 技術的負債の雪だるま化
翻訳ワークフロー全体の設計者としては
- 「モデル精度を上げる」だけでなく
「ポストエディットしやすさ」「エラーのわかりやすさ」も同じテーブルに乗せて議論すべき - 入力反転のように「モデルがうまく学習しやすくなる工夫」をしているなら、
同じくらいの熱量で
「人間がうまく働きやすくなる工夫」も入れるべき
結論:これは「古いテクニック」ではなく、「今のAIを読み解くレンズ」
Seq2Seqの入力反転は、もはやSOTAのテクニックではありません。
Transformerが距離問題を根こそぎ解決した今、
- これ単体で最新モデルを倒すことはない
- 新しいプロダクトの決定打にもならない
という意味では、完全に「古典」です。
でも、
- 距離をいじるだけで学習ダイナミクスは激変する
- モデルの都合を理解すると、小さな前処理で大きな改善が出る
- そういう改善の積み重ねが、人間の仕事の中身を静かに変えていく
という大きなストーリーを理解するうえで、
これほど良い教材はなかなかありません。
プロダクションでゴリゴリ使うか?
「新規プロジェクトで主役にする」のは、正直おすすめしません。
でも、
- レガシーSeq2Seqをあと少しだけマシにしたいとき
- チームに「時系列モデルの痛みと工夫」をちゃんと体験させたいとき
- 「AIが賢くなる」と「人間の仕事がどう変わるか」を議論したいとき
には、かなり効くネタだと思っています。
技術としては小さな前処理。でも、そこから見えてくるものは意外と大きいですよ。


コメント