
「またPoCだけやって終わりの“AIごっこ”案件かよ…」
現場エンジニアなら、一度はそう思ったことがあるはずです。
- 生成AIのデモはすごい
- でも日本語はいまいち
- ロボット連携と言いつつ、裏側は人力オペレーション
- 最後は「セキュリティとコストの懸念」でフェードアウト…
そんな空気の中で、「ソフトバンク主導・1兆円規模・国産AI+フィジカルAI」というニュースが飛び込んできました。
ここで「はいはい、またお金だけ大きい国家プロジェクトね」と流してしまうのはもったいないです。
正直、この構想は開発者の設計思想そのものを変えうるレベルの話になりつつあります。
一言でいうと「日本版 AWS for ロボット×LLM」を取りにきた

このプロジェクト、雑にまとめると:
「日本ローカルのクラウド+LLM+ロボットをまとめて、SoftBankが“物理世界向けAIインフラ”として標準化しにきた」
という動きです。
アナロジーで言うと、
- クラウド以前:
各社がオンプレでサーバー調達、運用もバラバラ - AWS登場後:
「同じAPIでどこでも同じように動く」共通インフラができた
今回やろうとしているのは、そのロボット+エージェント版。
「フィジカルAI」というラベルを貼って、
- GPU/HPC
- 日本語・産業特化LLM
- エージェントフレームワーク
- ロボティクス制御
- 通信インフラ(キャリアとしてのバックボーン)
をほぼ垂直統合でまとめてしまう構想です。
正直、スケール感と構え方がこれまでの「国産AIやります!」とは次元が違う🤔
何が“本当に”新しいのか?単なる「国産LLM」ではないポイント
研究費ではなく「事業スキームとしての1兆円」
よくあるパターン:
- 研究費として数百億
- 期間限定のプロジェクト
- 成果物はレポートとPoCで終了
今回:
- 商用レベルで回す前提の1兆円
- しかも政府支援+民間(SoftBank含む)で総額3兆円規模の文脈
- 「収益が上がるなら続ける、ダメなら打ち切る」という段階的支援
つまり、「GPU買ってモデル作って終わり」ではなく、
- LLMを全国の工場・店舗・倉庫・介護施設のロボットに配布する
- それを通信キャリアのインフラ上で動かす
- ちゃんと黒字にする
までを視野に入れた長期の事業インフラ投資になっています。
「フィジカルAI」をプラットフォーム概念として押し出した
多くの人が「フィジカルAI」と聞いてイメージするのは、
「AIが乗ったロボットでしょ?」
ですが、SoftBankとこの周辺が言っている「フィジカルAI」は、もっとレイヤー構造の話に近いです。
- LLM / マルチモーダルモデル
- エージェントフレームワーク
- ロボットOS・制御API
- センサー・カメラ・IoT
これらを一体として扱うアーキテクチャの名前として「フィジカルAI」を定義しようとしている。
ぶっちゃけると、
「クラウドAI(SaaS)から、物理世界を操作するAI OSへのジャンプ」
を標準化したい、という宣言に近いです。
なぜ開発者に効いてくるのか:AWS初期と同じ“設計思想の転換点”
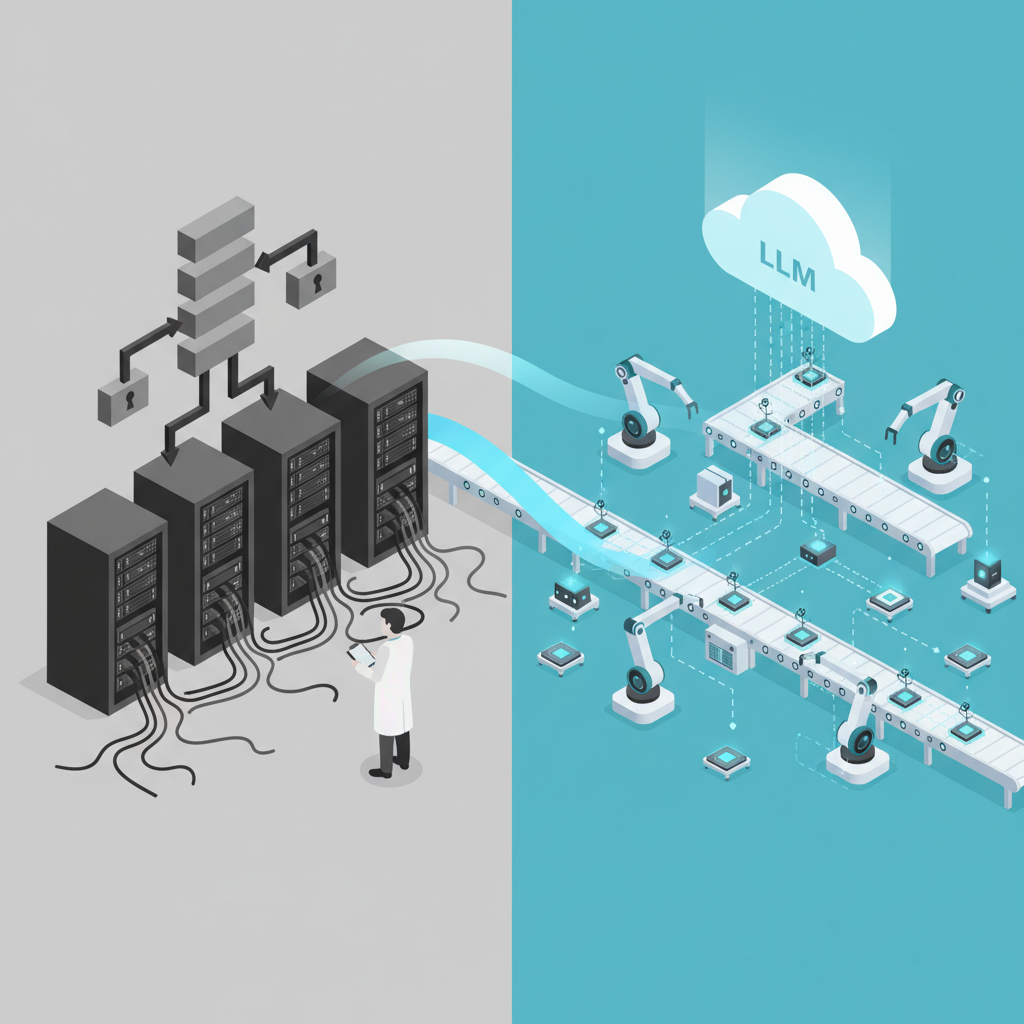
クラウド時代と同じ匂いがする理由
クラウド前:
- 物理サーバー前提でアーキテクチャを組む
- スケールアウトを最初から織り込めない
- インフラはSIer任せ
クラウド後:
- 「どうせAWS(GCP/Azure)に乗る前提」で設計
- オートスケール・マネージドサービス前提の発想
今回も同じ匂いがしています。
これまでは:
- 「対話型LLMをSaaSとして呼び出す」前提
- ロボットやIoTは別世界のエンジニアリング
- APIレベルでちょっと連携する程度
これからは:
- 「将来、工場や倉庫のロボットにエージェントを差し込む」ことを前提
- クラウド大モデル+エッジ小モデルのハイブリッドを最初から考慮
- LLMの出力=画面のテキストではなく、「物理アクションのトリガー」になる
という設計思想へのシフトが求められます。
正直、ここが分かっているかどうかで、
5年後に「あの時ちゃんと設計しておけば…」と泣くかどうかが決まると思っています。
「Google/GPTと何が違うの?」を冷静に比較してみる
海外勢 vs SoftBankフィジカルAIのざっくり対比
| 観点 | OpenAI / Google / Anthropic | SoftBank フィジカルAI構想 |
|---|---|---|
| マーケット | グローバル(英語中心) | 日本市場ど真ん中 |
| 強み | モデル性能・研究スピード | 通信インフラ・国内DC・販売チャネル |
| データ | Web全体+一部企業データ | 行政・医療・製造など日本ローカル産業データ |
| 物理連携 | API提供まで(ロボットは各社で連携) | LLM+ロボット制御+通信を事業として束ねる |
| 規制対応 | 各国ローカル対応は後追い | 最初から「国内DC・データ主権」前提 |
英語圏のSaaSを日本ローカルに無理やり当てはめてきたここ数年と比べると、
- 日本語の役所文書
- 製造業の現場マニュアル
- 介護記録
といった日本特有のデータを第一級市民として扱うインフラができるインパクトは小さくありません。
NTT/IOWNとの違い:どっち寄りに賭けるべきか
NTTグループ(IOWN+自前LLM)と比べると、
- NTT:
- 研究色強め、通信インフラ高度化が主戦場
- 国プロ・インフラ系・長期案件に強い
- SoftBank:
- 超商業寄り・スピード重視
- 「数千拠点にAIロボットをばらまく」系のスケールに強い
エンジニア視点で乱暴に言うと、
- 研究・インフラガチ勢 → NTT/IOWNの文脈がフィット
- プロダクト・SaaS・ロボット量産勢 → SoftBankフィジカルAIのほうが相性良さそう
という構図です。
どちらに寄るにせよ、
「日本国内に“もう一つのAIクラウドレイヤー”が立ち上がる」
という事実だけは押さえておくべきだと感じています。
ぶっちゃけ懸念していること:この構想の「落とし穴」
ここまで割とポジティブに書きましたが、エンジニアとしては冷静に見ておきたいポイントも多いです。
「国産」と言いつつ、サプライチェーンはほぼ海外依存問題
正直、「国産AI」という看板にはかなりグレーな部分があります。
- GPU:ほぼNVIDIA
- フレームワーク:PyTorch/TensorFlowなど海外発OSSが中核
- モデル設計の知見:海外論文・海外実装が土台
現実的には、
「海外OSS+日本データ+国内DC」でチューニングした日本向けスタック
という表現が一番しっくりきます。
これは悪いことではないですが、
「完全にサプライチェーンを日本に閉じる」ことはまず無理、という前提は持っておいた方がいいです。
1兆円でも“維持費込み”で見ると結構タイト
GPU/HPCクラスタを本気で運用したことがある人なら分かると思いますが、
- 設備投資
- 電力・冷却
- データセンター維持費
- 運用エンジニア・研究者の人件費
- 継続的なモデル再学習・評価・アップデート
これを5〜10年単位で回し続けるのは、1兆円でもカツカツになり得ます。
「最初だけドカンと投資して、あとは惰性で…」
となった瞬間に、海外モデルとの性能差は一気に開く可能性が高い。
開発者としては、
「この基盤、10年後もちゃんとアップデートされ続けるのか?」
という視点でウォッチしておく必要があります。
ベンダーロックイン:ロボットAPIは特にヤバい
クラウドロックインは今に始まった話ではありませんが、
フィジカルAIでロックインされると桁違いに重いです。
- LLM APIだけなら、最悪プロキシかませばリプレース可能
- でも、ロボティクスAPI+エージェント実行基盤までガッツリ組んでしまうと…
数年後に「やっぱり別クラウド/別LLMに移行したいです」となった時、
- 倉庫のロボット群
- 工場ラインの制御ロジック
- 店舗の業務フロー
全部を張り替える羽目になります。
正直、ここはかなり危険なポイントで、
「ROS2 / OpenAPI / オープンLLM互換レイヤーを自前で一段かませておく」
くらいは、プロダクト側で防衛線を引いておくべきだと思っています。
フィジカルAI特有の「事故リスク」とどう付き合うか
LLMが間違えたからといって、
今は「変な文章が出た」「誤回答だった」で済みます。
フィジカルAIだと:
- ロボットが人にぶつかる
- 誤った操作で機械を破損
- 医療・介護現場での致命的ミス
に繋がりかねません。
しかし根本的に、現行のLLMは
- 確率的挙動
- 完全な保証ができない
という性質を持っています。
従来の機能安全(Safety)の文脈とどう整合させるのか?
ここは、まだ誰も正解を持っていない領域です。
開発者側としては、
- LLMが直接アクチュエータを叩かない設計
- セーフティレイヤーを別系統で設ける
- 必要なところだけ決定木/形式手法に落とす
といった「LLMを万能コントローラにしない設計」が、かなり重要になってきます。
一番のボトルネックは「人材」と「エコシステム」
GPUクラスタは金で買えますが、
- MLOps
- ロボティクス
- エージェント設計
- 安全設計+規制対応
このあたりを全部わかっている人材は、今の日本にはほとんどいません。
1兆円投資しても、
- 現場を回せるエンジニアが育たない
- SIが従来の多重下請け構造のまま
- 「とりあえずPoC」から先に進まない
となれば、第5世代コンピュータの焼き直しになりかねない懸念があります。
逆に言えば、
今この領域(日本語LLM×ロボティクス×MLOps)に飛び込むエンジニアは、数年後めちゃくちゃレア人材になる
のもほぼ確実です。
キャリア的には大きなチャンスでもあります。
「で、プロダクションで使うか?」に対する自分の結論
現時点(まだ構想+投資コミット段階)での、僕のスタンスはこんな感じです:
- プロダクションで全面採用 → 正直まだ様子見
- API仕様・SLA・料金・サポート体制が見えない
- モデル性能とアップデート方針も未知数
- アーキテクチャ設計での考慮 → 今すぐやるべき
- 「将来フィジカルAIに接続できる前提」でシステムを分割
- LLMの役割を「UIの一種」から「物理世界のオーケストレーター候補」に昇格させておく
具体的には、今からできることはこんなところだと思っています👇
いますぐ開発者がやっておきたいこと
- 抽象レイヤーの設計
- LLM APIを直接ベタ書きしない
-
自前の「LLMサービスラッパー」を用意して、
- OpenAI / Anthropic / オープンLLM / 将来の国産LLM
の切り替えができるようにする
- OpenAI / Anthropic / オープンLLM / 将来の国産LLM
-
ROS2やロボティクスAPIとの距離感をつかむ
- フィジカルAI前提なら、
- ROS2
- シミュレータ(Gazebo, Webots など)
-
を少なくとも触っておくと、世界観が一気に具体的になります。
-
日本語LLM+エージェントの設計パターンを押さえる
- LangChain / LlamaIndex / OpenAI Assistants 等で、
-
「ツール呼び出し+ワークフロー」をどう設計するかを実験しておく
-
ベンダーロックイン回避のガイドラインを決めておく
- 社内アーキテクチャ原則として、
- オープン標準優先
- クラウド依存部分の抽象化
- を文書に落としておくと、数年後自分を助けます。
最後に:これは「また国が無駄遣いしてる話」ではない
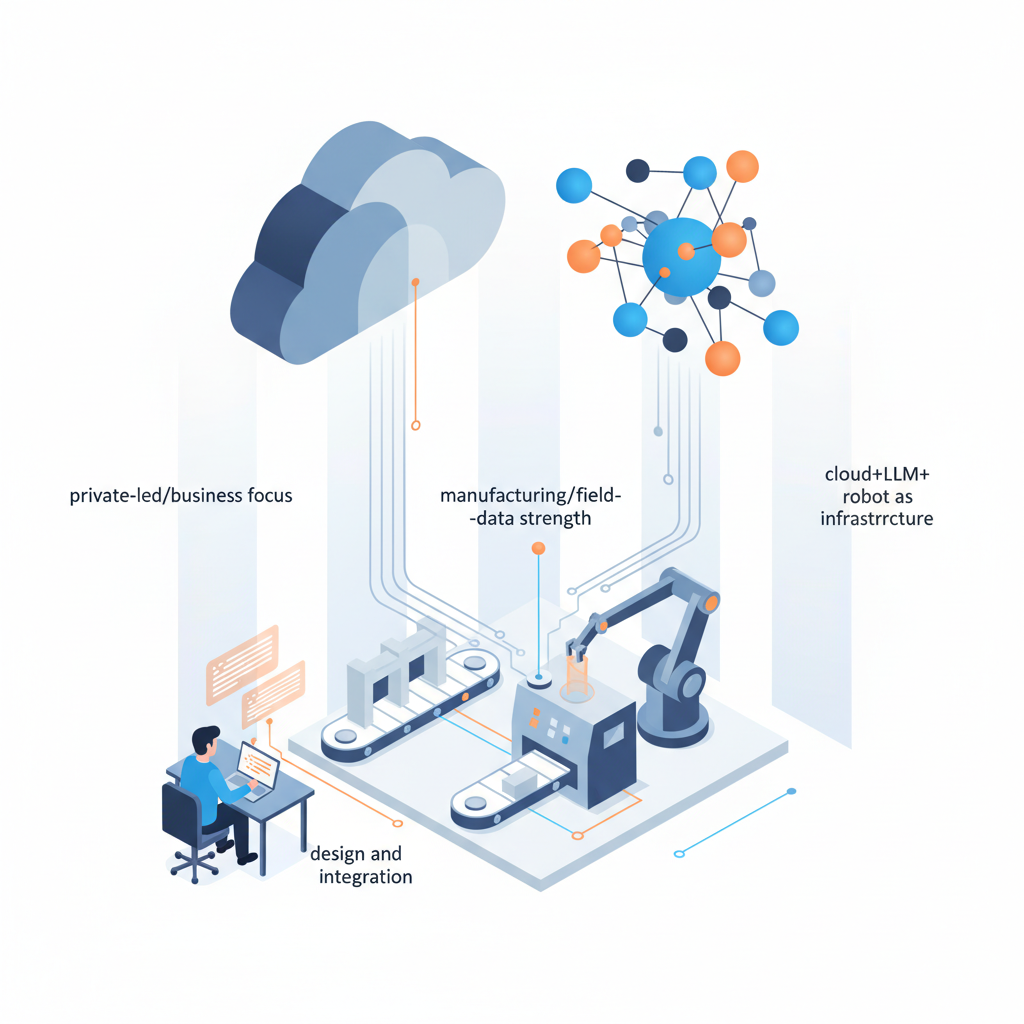
第5世代コンピュータのトラウマからか、
「どうせまた大風呂敷広げて終わるでしょ」と冷笑する空気もあります。
でも、今回は少なくとも次の3点が違います。
- 民間主導+事業性重視
- 日本の強み(製造・現場データ)ど真ん中
- クラウド+LLM+ロボットを“インフラ”として設計しにきた
ここまで要素がそろっている国家レベルの試みは、日本では初めてと言っていい。
成功するかどうかは、
SoftBankや政府だけではなく、我々開発者がどれだけ“ちゃんと設計して”乗っかれるかにもかかっています。
- 目先のPoCで消費するか
- 10年スパンで通用するアーキテクチャを、この波に合わせて組み替えるか
正直、その分かれ目に来ていると感じています。
少なくとも、
「フィジカルAIを前提にした設計」というキーワードだけは、
2025年のうちに自分の頭とコードベースにインストールしておいた方がいいと思います。


コメント