
「スクレイピング用のプロキシ代だけで、SERP API 何本契約できるんだろ…?」
そんな計算を一度でもしたことがある方、いますよね?🤔
- 自前クローラは IP ブロックとの泥仕合
- Bing Search API は 2026/08 廃止で路線変更
- LLM から“とりあえず Web 検索”したい要件は右肩上がり
この三重苦のタイミングで、Qiita に
「2026年版 最安値Web検索・SERP API完全ガイド」
が出てきたのは、かなり象徴的だなと感じています。
この記事、単なる「API カタログ」ではありません。
「もう自前スクレイピング前提で設計するの、そろそろやめません?」
という宣戦布告に近い。
一言でいうと:SERP界の「オンプレから AWS 移行ガイド」

このガイドを一言で言うなら、
「スクレイピング・オンプレから SERP as a Service へのクラウド移行ガイド(しかも最安値縛り)」
です。
かつて物理サーバを抱えていた時代、
- ラック手配
- 電源・空調
- RAID 死亡対応
- 24/365 監視
を自社でやっていたのが、
「いや、AWS でよくない?」となった瞬間がありましたよね。
今回の SERP API も、かなりそれに近いフェーズに来ていると感じます。
- IP ローテーション
- ヘッドレスブラウザ
- CAPTCHA 回避
- 検索 UI の仕様変更に追従するパーサー更新
これを自社で延々とやるのは、もはや
「物理サーバを自分でラックに突っ込んでる」のと同じ匂いがする。
このガイドの「本当の」新しさはどこか
技術的には、REST / JSON の普通の API です。
Python なら requests で GET、Node なら fetch。特にひねりはありません。
import requests
API_KEY = "YOUR_API_KEY"
params = {
"api_key": API_KEY,
"q": "SERP API 最安値",
"location": "Japan",
"hl": "ja"
}
res = requests.get("https://api.example.com/search", params=params, timeout=30)
data = res.json()
for r in data.get("organic_results", []):
print(r["position"], r["title"], r["link"])
じゃあ何が新しいのかというと、視点です。
「最安値」を“ちゃんと定義した”こと
正直、これまでの SERP API 比較記事って、
- 「1,000 リクエストあたり $0.○」
- 「無料枠あります!」
みたいな表面的な料金表の貼り合わせが多かった。
今回のガイドは、そこをかなり踏み込んでいて:
- リクエスト単価
- 月額最低課金
- 無料枠の有無
- 地域ターゲティング可否
- 商用利用の制限
まで粒度を下げて比較しているのがポイントです。
つまり、
- 単価は安いけど無料枠ゼロ
- 無料は太っ腹だけど商用禁止
みたいな「後から効いてくる罠」を、最初から可視化している。
ぶっちゃけ、
「安いから採用したら商用禁止だった or 有料移行で爆上がり」
という痛い目を見た人、かなりいるはずです(私もその一人です…)。
ユースケースが完全に「ポスト-SEO 時代」寄り
もうひとつ大きいのは、ユースケースの前提が
完全に LLM / AI 時代に寄っていること。
- SEO モニタリング
- ランクトラッキング
みたいな従来の使い方だけでなく、
- LLM プラグイン用のリアルタイム検索ツール
- 価格比較・EC クローラの代替
- ニュース/トレンド監視
- AI エージェントの Web ツール
といった2026 年の現実の使われ方に合わせて、
「どの API がコスパ良いか」を整理し直している。
今からクローラを新規で書くより、
“LLM から叩ける検索 API を前提にする方が自然だよね?」
という空気感が、記事全体から伝わってきます。
スケール別に「選定ロジック」をほぼ完成させている
個人的に一番良かったのはここです。
- 月 数百リクエストの個人開発
- 月 数万〜数十万のプロダクト初期
- 月 数百万〜1,000 万の SaaS / エンタープライズ
みたいに利用規模ごとに「このレンジならこのクラスの API」
という IF/ELSE ロジックがほぼ完成している。
これ、現場だと毎回やってるやつなんですよね:
- 「PoC は無料枠で走らせたい」
- 「でもスケールしたときの単価は抑えたい」
- 「SLA・並列数・失敗率も見ないと怖い」
この悩みを、かなり体系的に整理してくれている。
設計レビュー時にそのまま貼りたいレベルです。
競合構図:自前クローラ vs 専用 SERP API vs 汎用スクレイピング

この記事を読むと、競合構図がきれいに三層に見えてきます。
- 自前スクレイピング基盤
- 専用 SERP API
- 汎用スクレイピング API(RapidAPI 経由など)
自前クローラは「まだ戦うの?」というフェーズに入った
記事でも強調されていますが、
「プロキシプール+ヘッドレスブラウザ+CAPTCHA 対応」を
自前で維持するコストが、
もはや SERP API の従量課金より高いケースが増えている
これは、かなり本質的な指摘です。
- スクレイピングのための人件費
- Google 側 UI 変更への追従
- ブロック・BAN 対応
- ログ・監視・SLO
を全部足し込むと、
「自前の方が安い」と言い切れるケースはかなり減っていると思います。
特に、Bing Search API 廃止 → サードパーティ SERP API へ移行、
という流れがすでに起きているのを見ていると、
Search / SERP 取得そのものは、
インフラではなく“買うもの”になった
という流れはもう止まらないな、という印象です。
専用 SERP API が「検索結果だけ欲しい」需要をほぼ総取りしつつある
専用 SERP API の強みはシンプルで、
organic_results,ads,knowledge_graph,local_packなど
「欲しい単位」で JSON が返ってくる- 地域 (
gl), 言語 (hl), デバイス (device) が自然に指定できる - AI Overviews / SGE 領域への追従が進んでいる
つまり、“検索結果だけ欲しい”ユースケースには最適化されすぎている。
汎用スクレイピングで HTML を取って自前パースするのは、
正直もう「やりたくない仕事」の部類です。
汎用スクレイピング API は「なんでも取れる」のが逆に弱点になる
RapidAPI 系・Web Scraper API 系も、もちろん生き残ります。
ただし、ポジションは明確に変わると思います。
- 任意サイトの HTML / JS 実行が必要
- EC サイト / SNS / ニュース / 自社ページ など多様なソース
- SERP 以外の構造もガッツリ取る
こういう時は汎用スクレイピング一択です。
でも、
検索結果「だけ」欲しいのに汎用を選ぶのは、
EC サイト構築に Kubernetes を直で立てるようなもので、
もはや割に合わない。
このガイドは、そのことを価格の面からハッキリ突きつけていると感じます。
「最安値」に飛びつく前に知っておきたい“闇のコスト”
とはいえ、「最安値ガイド」と聞くと
「とにかく単価が安いところに乗り換えよう」という話に
短絡しがちですが、そこにちゃんと釘を刺しているのも良い点です。
真のコストは「単価」ではなく「ロックイン+マイグレーション」
正直、ここをちゃんと書いているのは偉いなと思いました。
- ベンダー固有のレスポンススキーマ
- 独自の
search_metadata/error_code - Rate Limit の挙動
- リトライポリシー
にがっつり依存した実装をしてしまうと、
別プロバイダへの移行コストが一気に跳ね上がる。
「月 $20 安いから乗り換えよう」と言い出した瞬間に、
- 実装変更
- テスト
- 本番切り替え
- モニタリング更新
で普通に人件費が数十万円〜飛びます。
ここを「見えない CAPEX」としてちゃんと考えないと赤字です。
👉 個人的には:
- 抽象インタフェースを必ず一枚かませる
ISerpClient的なインタフェースsearch(query, options) -> NormalizedResultまでを自前定義- レスポンスは内部標準スキーマに正規化してから扱う
をやらないと、2026 年以降の SERP 運用はヤバいと思っています。
無料枠の甘さと「商用禁止」の地雷
無料枠が太っ腹なサービスほど、
利用規約の行間がきついケースも多いです。
- 商用利用禁止
- 転売 / 再配布禁止
- SaaS への組み込み NG
などなど。
PoC ではノーコストで回っていたのに、
プロダクションイン時に法務チェックで一発NG
……という話も実際に聞きます。
最安値ガイドを読むときは、
価格表と同じくらい「Terms / ToS」を読めというメッセージだと受け取りました。
ベンダー・リージョン依存は普通に SRE 的リスク
一部の SERP プロバイダは、
- 特定のクラウドリージョンに集中
- 検索エンジン側の規約変更で一時停止
- Bing API 廃止に絡むような「方針転換」
を平気でやってきます。
ミッションクリティカルな SaaS で
1 社にフル依存するのは、正直かなり怖い。
このガイドが言っている
「大規模利用なら、1 社集中より複数プロバイダ併用が安い場合もある」
という指摘は、
コストというより可用性確保の観点からも重要です。
- プライマリ / セカンダリ SERP プロバイダ
- 正常系での分散(例:80% / 20%)
- 障害時のフェイルオーバー
くらいは、最初から設計に埋め込んでおくべき時代になっています。
LLMアプリ設計の「デフォルト」が静かに書き換わる
もうひとつ地味に効いてくるのが、
LLM / エージェント設計の前提が変わりつつあるという点です。
これからの LLM アプリは、たいていこんな感じになります:
- 内部ツール or 外部 API として「検索」を 1 つ以上持つ
- その検索の裏側に どの SERP API を噛ませるか を設計時に決める
- コスト・精度・レイテンシ・SLA を踏まえてチューニング
つまり、
「どの検索プロバイダを選ぶか」が
アーキテクチャ初期の設計パラメータになる
ということです。
これは、クラウド時代の「IaaS どこ使う?」問題にそっくりです。
- AWS 一択で行くのか
- マルチクラウドを前提にするのか
- 地域やコストで使い分けるのか
と同じように、
- Google SERP 特化(SerpApi など)
- マルチエンジン対応(Bright Data, DataForSEO など)
- 汎用スクレイピングで自作 SERP
を最初の設計レビューでちゃんと議論すべきになってきている。
この Qiita ガイドは、
その議論のための「価格・機能前提条件表」として、かなり実用的です。
じゃあ、プロダクションで今すぐ全部 SERP API に寄せるべきか?
正直に言うと、「ケースバイケースだけど、方向性としては Yes」
というのが私の結論です。
すぐに寄せていいケース
- 新規プロダクト / PoC
- LLM エージェントの Web 検索機能
- 既に Bing Search API 依存で、廃止に怯えているシステム
- SEO モニタリング / 競合調査系の新規サービス
ここは、最初から SERP API 前提で設計した方が素直です。
- インフラを持たない
- 検索エンジン UI 変更を外部に丸投げ
- LLM から JSON を直接食べやすい
メリットが明確にコストを上回ります。
ちょっと様子見した方がいいケース
一方で、全部を一気に SERP API に寄せるのは危険なケースもあります。
- 既に巨大な自前クローラ基盤があり、
- SERP 以外のページも大量に取っている
- 独自ログ / 履歴 / データマートが積み上がっている
- 法務・コンプラ的に「グレーなスクレイピングは全部チェック対象」な大企業
- 金融・公共など、対検索エンジンの規約リスクに極端に敏感な業界
この辺りは、
- SERP 部分だけ外部 API に切り出すハイブリッド構成
- 一部トラフィックだけ SERP API に流してコスト・安定性を観測
- 利用規約・法的リスクを丁寧に精査
といったソフトランディング戦略が現実的だと思います。
「最安値ガイド」を見て即全振り、はさすがに乱暴です。
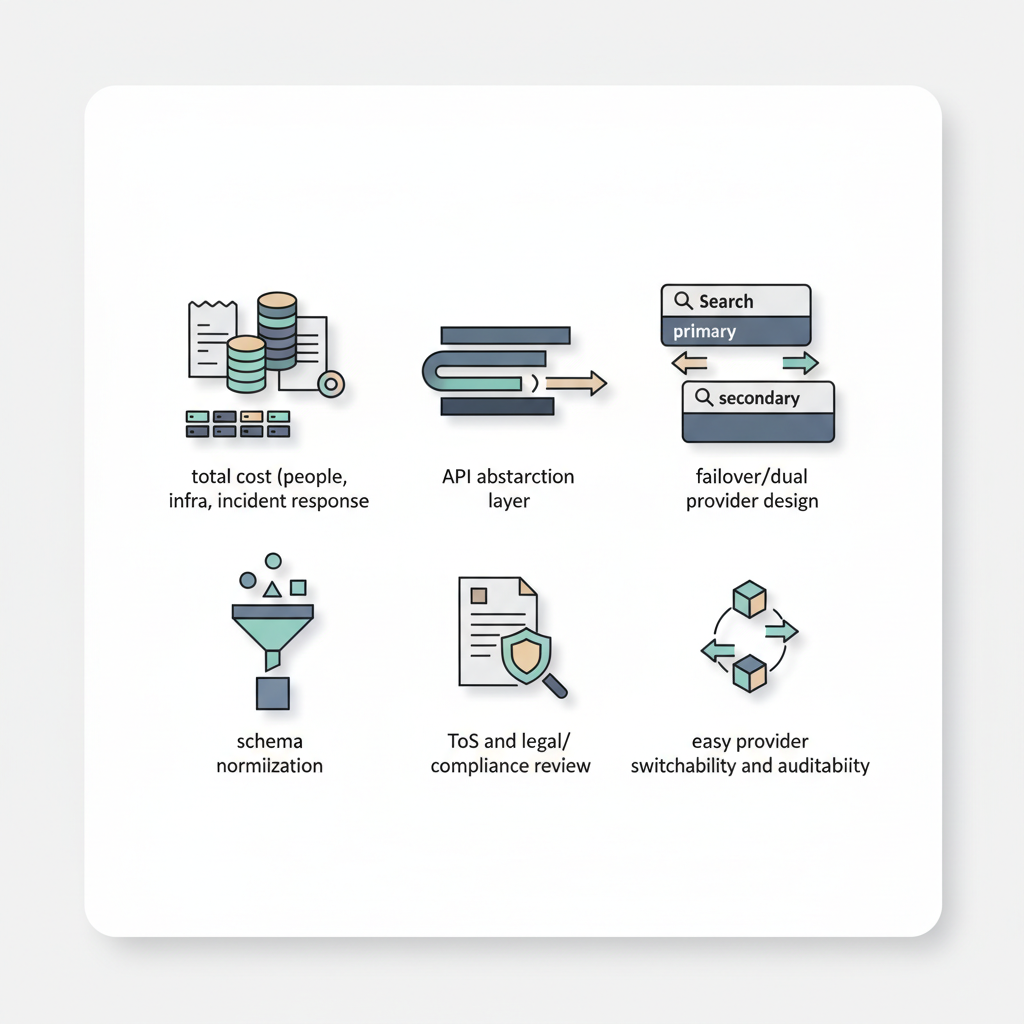
個人的な「今やるべきこと」チェックリスト
この記事を読んで、
2026 年の開発者が今やっておくべきことを、自分なりにまとめるとこうなります👇
- 自前クローラの「総コスト」をちゃんと計算し直す
-
人件費・インフラ・障害対応・UI 追従・法務リスクまで含める
-
検索まわりのコードに抽象レイヤーを必ず挟む
ISerpClient/SearchProviderパターンで API 依存を隔離-
レスポンスは内部スキーマに正規化してから扱う
-
プライマリ+セカンダリ SERP プロバイダ前提で設計する
-
小さくてもいいので、2 社目を常に叩けるようにしておく
-
無料枠と ToS をセットで読む習慣をつける
-
「商用 NG」「再販売 NG」「AI トレーニング NG」などを確認
-
LLM / エージェントの設計ドキュメントに「検索プロバイダ選定理由」を残す
- 将来の乗り換え・監査の時に効いてくる
結論:このガイドは「価格表」ではなく「アーキテクチャの踏み絵」
まとめると、この Qiita の
「2026年版 最安値Web検索・SERP API完全ガイド」
は、
単に「どこが一番安いか」を教えてくれる記事ではなく、
「2026 年以降も自前スクレイピング中心でいくのか?
それとも SERP as a Service に舵を切るのか?」
を、開発者と組織に突きつける静かな踏み絵だと感じました。
- 仕様レベルでは breaking change はない
- でもアーキテクチャレベルでは、
オンプレ → クラウド級のパラダイムシフトが進行中
プロダクションで使うか?
正直、「全面移行」はまだ様子見ですが、
新規開発と LLM まわりは、もはや SERP API 前提で設計します。
そしてその時に、
この「最安値ガイド」は戦術的な価格表としてだけでなく、
戦略的な設計チェックリストとして、かなり役に立つはずです。🚀


コメント