「AIでコード書いてみたけど、結局あとで自分で全部直してるんだよな……」
「プロンプト頑張ってるのに、チーム開発の生産性はあまり変わってない気がする…」
そんなモヤモヤ、ありませんか?
Copilot や ChatGPT は確かに強力です。でも、現場レベルで見るとまだまだ「うまくハマってない」チームが多い。
理由は単純で、ツールの話しかしていないのに、プロセスを変えずに済まそうとしているからです。
この記事で扱う「AI補助開発における三段階方法論」は、そこにかなりちゃんと踏み込んでいる。
一言で言うと、
「AI補助開発のウォーターフォール+アジャイル・ハイブリッド版」
です。
しかも単なる概念じゃなくて、実務にそのまま載せられるレベルで段階が切られている。
一言で言うと、これは「AI界の TDD + Docker 的転換」
この三段階方法論を最初に読んだときに感じたのは、
- TDD が「テストを書く」こと以上に「設計の仕方」を変えたとき
- Docker が「コンテナ技術」から「デプロイ標準プロセス」に昇格したとき
あの感覚にかなり近い、ということです。
多くの「AI活用記事」は、
- このプロンプトが効く
- この拡張機能が便利
のレイヤーで止まります。
この方法論は違っていて、
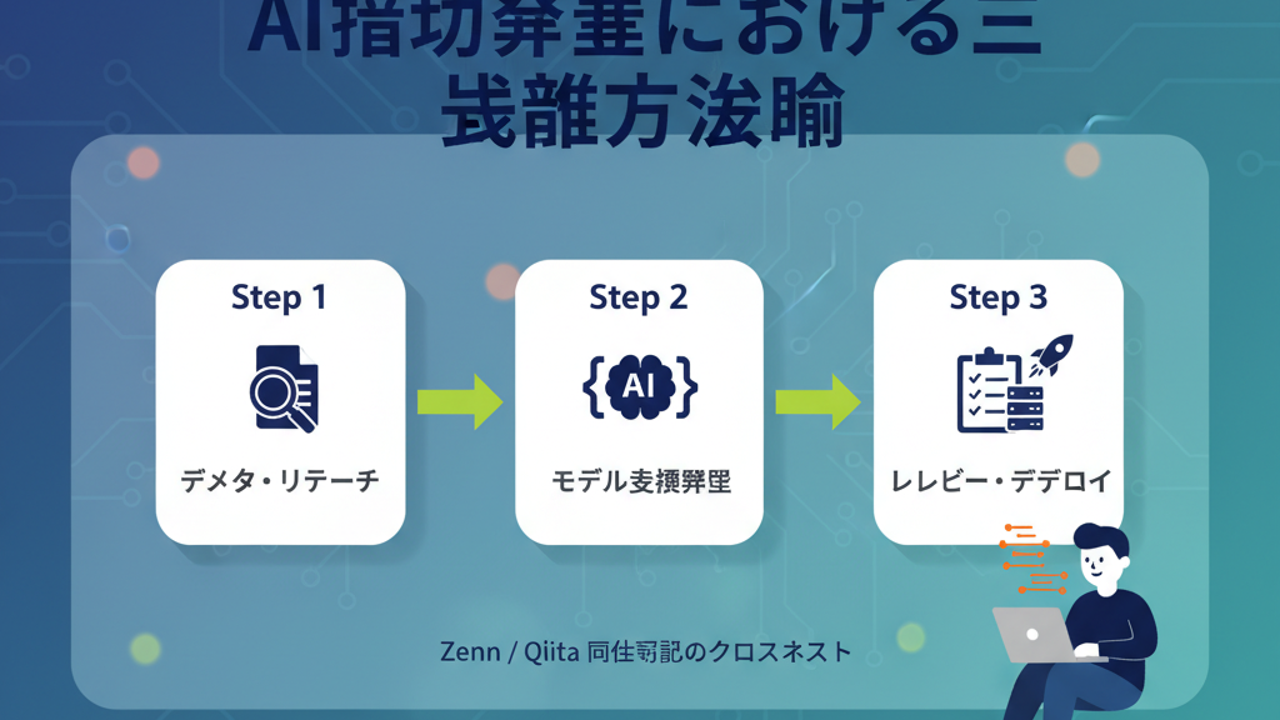
要件 → 設計&実装 → 検証
を「AIを前提にした三段階プロセス」に再編成している
のがポイントです。
ぶっちゃけ、ここまで「プロセス側」をちゃんと設計している話はまだ少ない。
LangChain だ、MCP だ、と「コード上のAIパイプライン」にみんな目を輝かせている中で、
「いやいや、その前に “人間の開発プロセスのパイプライン” を整理しないとダメでしょ?」
と言っているわけですね。
三段階方法論の中身を、あえて雑に要約すると
多少用語は揺れていますが、本質的にはこの3つです:
- 要件・仕様整理フェーズ(構想・分解)
-
「こういうの作りたいんだよね」を AI にぶん投げて、
- 用語定義
- 前提条件
- ユースケース
- インターフェイス案
などを対話型で一緒に分解していくフェーズ
-
設計・コード生成フェーズ(ドラフト実装)
- 整理された仕様を元に、
- API 設計
- データモデル
- スケルトンコード
を AI に書かせる
-
ただし「全部丸投げ」ではなく、モジュール/機能単位で小刻みに生成 → 人間がレビュー
-
検証・改善フェーズ(レビュー・リファクタリング)
- 生成されたコードに対して、
- テストケース・テストコード生成
- コードレビューコメント
- リファクタ案
- バグ修正案
を AI に書かせる
- AI は「レビュアの一人」、最終責任は人間
この「3分割」のおかげで、かなりクリアになるものが2つあります。
- AIが得意な場所:要件分解・雛形生成・パターン提示
- AIが危うい場所:最終仕様決定・セキュリティ設計・本番リリース判断
多くの現場で混ざってしまっているこれらの境界線を、
「フェーズ単位」で強制的に引き直しているのがミソです。
これ、何がそんなに新しいのか?
正直、やっていること自体は「全部新しい発明」というわけではありません。
- 要件を対話で詰める
- AI にコードを書かせる
- AI にレビューさせる
どれもすでにやっている人はやっている。
新しいのは、次の2点です。
「AIを3つの役割を持つ補助エージェント」として明示的にモデル化している
多くのチームはまだ、
- 「とりあえず Copilot 入れました」
- 「ChatGPT に ‘◯◯のコード書いて’ って投げてます」
レベルで止まっています。
つまり、AI がどのフェーズでどんな責任を持つのかを設計していない。
この三段階方法論は、
- 要件整理を手伝う AI
- 設計&実装のドラフトを書く AI
- レビューとテストをサポートする AI
という3つの人格に役割分担している。
ここまで意図的に「役割設計」しているのは、かなり実務寄りです。
「プロンプトや運用ルールもフェーズごとに変えるべき」と言い切っている
正直、これをちゃんと分けているチームはまだ少ない印象です。
- 要件フェーズ:
- 「前提条件を漏れなく洗い出せ」
- 「非機能要件と制約を一覧にせよ」
- 実装フェーズ:
- 「ここの責務をもつクラスだけ実装して」
- 「I/F を先に宣言してから中身を書いて」
- 検証フェーズ:
- 「この仕様に対する境界値テストを全部出して」
- 「設計上のアンチパターンがないかレビューして」
といったように、フェーズ別のプロンプト戦略を前提にしている。
ここが「ただの How to プロンプト集」との決定的な違いです。
なぜこれは「フレームワークより先に学ぶべき」話なのか
個人的に一番共感したのは、
LangChain や MCP みたいな「LLM連携フレームワーク」より先に、
AI補助開発の三段階プロセスをちゃんと設計する方が筋がいい
というスタンスです。
LangChain などとの位置づけの違い
ざっくり比較するとこうなります:
| 観点 | 三段階方法論 | LangChain / MCP など |
|---|---|---|
| フォーカス | 人間の開発プロセス (要件〜検証) | アプリ内部の LLM 呼び出しパイプライン |
| 抽象レベル | 高い(メソドロジー) | 中〜低(コードレベル構成) |
| ベンダーロックイン | ほぼなし(モデル非依存) | あり(そのフレームワーク API 前提) |
| 価値の中心 | 役割分担・開発サイクルの再設計 | LLM 機能の再利用・統合 |
つまり、
- LangChain を入れたからと言って、
チームの要件定義やレビューの仕方が自動的に良くなるわけではない - 一方で、三段階方法論は LangChain の採用・非採用に関係なく効く
という構造です。
正直、ここ1〜2年で「AIプロダクト作りたいから、まず LangChain 覚えます」という話を何度も聞きましたが、
個人的にはかなり違和感があります。
いや、その前に要件〜実装〜検証のどこに AI を噛ませるかを決めないと、
どんなフレームワークを選んでも「なんとなく便利」止まりですよね?
という話です。
チームにどう効くか:ジュニア/シニア/PO それぞれの視点
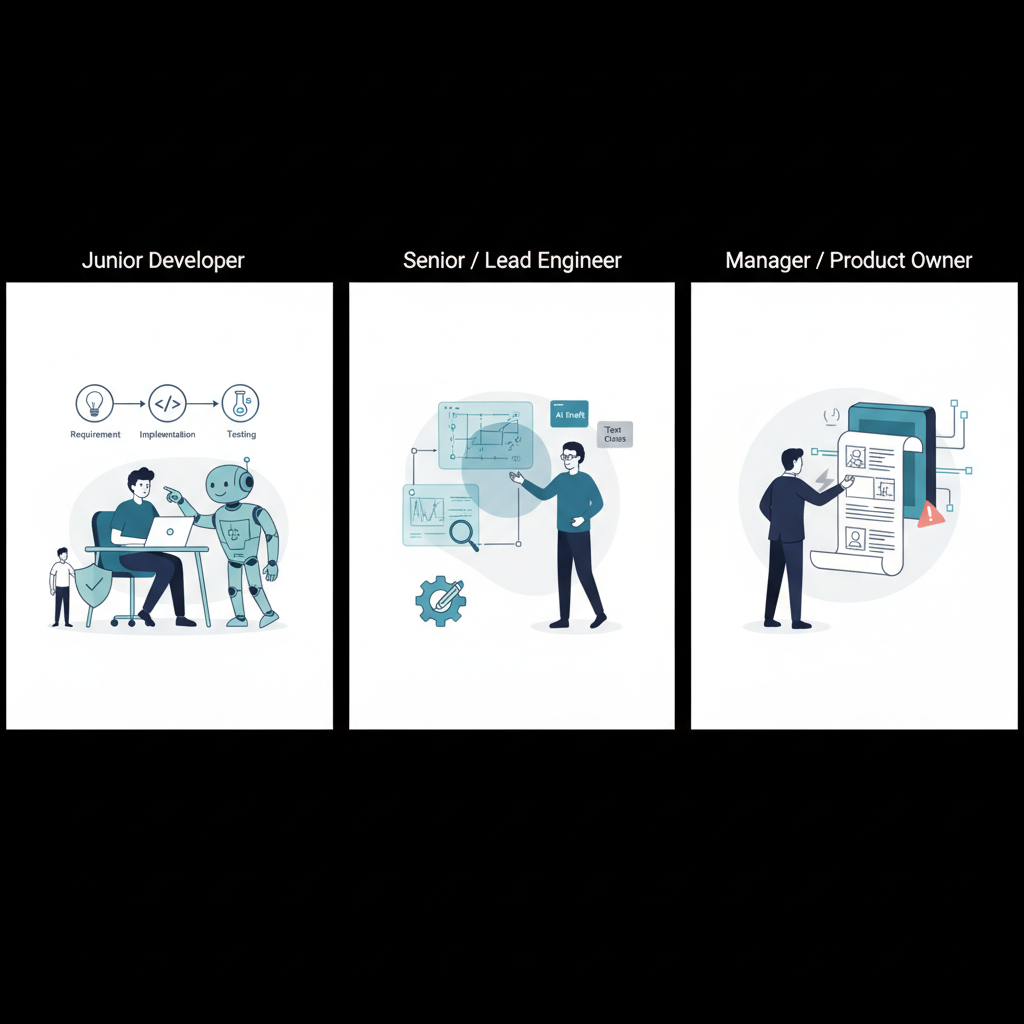
この方法論の良いところは、「誰にどう効くか」がわりとイメージしやすいところです。
ジュニア開発者
- メリット
- 要件〜実装〜テストまで、AI とペアプロしながら一気通貫で学べる
- 自分一人では書けないテストケースや設計の引き出しを、AI経由で体験できる
- 懸念
- 「AIが書いたから正しい」と思ってしまうリスク
→ 三段階方法論は「最終責任は常に人間」と明確にしている点が重要
シニア / リードエンジニア
- メリット
- 自分が全部手を動かさなくても、
AI が書いた仕様ドラフト・設計案・テスト案をレビューする形で関われる - コードの細部を見るよりも、設計レベルの妥当性チェックに集中できる
- 懸念
- 「AI の使い方を設計する」という新しい仕事が増える
→ プロンプトテンプレとフェーズ運用ルールの設計コストは、確実に増えます
マネージャ / プロダクトオーナー
- メリット
- 粗い要件から AI に仕様書ドラフトを起こさせられるので、
上流のドキュメント生成が一気に軽くなる - かなり大きい懸念
- 間違った前提で、AI が一貫性だけは立派な仕様書を仕立て上げてしまうリスク
→ 「間違っているのに綺麗にまとまっているドキュメント」が一番タチが悪い
ただし、現実的な「落とし穴」もかなりある 🤔
ここまで割と褒めてきましたが、
実務に落とすときにはガッツリ見ておくべき懸念も多いです。
トークンコスト:ちゃんと試算しないと死ぬ
三段階すべてに AI を深く関与させると、当然ながら
- 要件フェーズ:
長文要件 + 何往復もの QA - 実装フェーズ:
スケルトンコード + 修正版 + コメント - 検証フェーズ:
コード一式 + テストコード + 実行ログ
と、トークン消費が爆増します。
従量課金モデルの API をそのまま適用すると、
- プロジェクト単位のコスト見積もりがふわふわになる
- 途中から「コスト怖いから AI 呼び出しをケチる」状態になり、
結局方法論が形骸化する
という未来が見えます。
意見としては:
プロダクション案件に適用するなら、
- フェーズごとの AI 利用ガイドライン
- 月のトークン上限と監視
をセットで決めないと危ない
と思っています。
プロセス設計コスト:導入初期は割と「重い」
この方法論をチームに入れるには、
それなりに“インフラ”が要ります。
- フェーズ別のプロンプトテンプレ
- チャット履歴や生成物の保存・共有ルール
- 「どこからどこまでは AI に投げてOKか」というチーム規約
正直、これを何も決めずに「とりあえず三段階でやろう」はほぼ失敗します。
ここを重く見て「うちはまだ早い」と判断するのも全然アリだと思っています。
モデル依存:理屈はモデル非依存、現実はそうでもない
方法論としてはモデル非依存ですが、
- 長コンテキスト
- コードの一貫性チェック
- 複雑な仕様の要約&照合
あたりをちゃんとやろうとすると、
結局 GPT-4 クラス or 同等性能のモデルに寄らざるを得ません。
つまり実務上は、
- 特定ベンダーの料金・規約・API 安定性への依存
- 社外 LLM を使えない業種 (金融/公共系など) との相性問題
は依然として残ります。
ここは「三段階方法論をどうローカル LLM に落とすか」という別問題になります。
組織面:きれいな三段階を回せる会社はまだ少ない
理想形は、
- プロダクトオーナー
- 開発者
- QA
が同じ AI チャット空間とドキュメント空間を共有している状態です。
でも現実は、
- セキュリティポリシー上、要件やコードを外部 LLM に出せない
- 部署ごとにツールがバラバラ(PM は Excel、開発は GitHub、QA は Redmine…)
ということの方が多い。
正直、この方法論をフルスタックで適用できる組織は、まだ少数派だと思います。
なので、現実的には
まずは「第2フェーズ(コード生成)だけ」から入って、
徐々に1・3フェーズに広げていく
くらいの段階的導入が現実解でしょう。
「AIウォーターフォールを一瞬で終わらせてから、アジャイルで回す」という発想

この三段階方法論を一番うまく表しているアナロジーは、
「現代版のウォーターフォール+アジャイルのハイブリッド」
だと感じました。
- 第1フェーズ:
AI にウォーターフォール的な「全体像の仕様ドラフト」を一気に書かせる - 第2・3フェーズ:
その上で、アジャイル的に「小さい単位」でコード&テストサイクルを回す
ここが面白いのは、
- ちゃんとやると重いウォーターフォール上流工程を
AI で一気に“安くラフに”やってしまう - その結果として、アジャイルで回す下流工程の負荷がかなり下がる
という構造になっている点です。
歴史的に見ると、
「ウォーターフォール vs アジャイル」はしばしば宗教戦争っぽく語られてきましたが、
AI を前提にすると
- ラフなウォーターフォール上流を AI が超高速でやる
- その上でアジャイルを回す
という折衷案が現実的な最適解になりつつある気がします。
プロダクションで今すぐフル導入するか?個人的な結論
正直に言うと、
「次の新規プロジェクトで、いきなり三段階フルセット」はあまりオススメしない
です。
理由はシンプルで、
- トークンコスト
- プロセス設計コスト
- 組織的なツール/ルールのギャップ
が一気に噴き出す可能性が高いから。
一方で、
「チームとして AI をどうプロセスに組み込むか」を考えるベースフレームとしては、かなり有望
とも思っています。
自分が現場リードだったら、こう使います:
- まずは 第2フェーズ(モジュール単位のコード生成+人間レビュー) だけ三段階を意識して導入
- うまく回りはじめたら、
第3フェーズ(テストケース生成・レビュー支援) を追加 - 最後に、要件定義/仕様書作成プロセスで
AI をどこまで使うか(第1フェーズ)を設計していく
つまり、下流 → 上流の順に段階的に取り込むイメージです。
まとめ:フレームワークより先に「三段階」をチームで話した方がいい

この三段階方法論の価値を一言でまとめるなら、
「AIを使う/使わない」の話ではなく、
「AIを前提に開発プロセスをどう組み替えるか」のフレームをくれた
ことだと思います。
LangChain や MCP も面白いし、大事なピースではあります。
でもその前に、
- 要件
- 実装
- 検証
のどこに AI を噛ませて、
どこは人間が握り続けるのか。
この「三段階」の線引きをチームで一度ちゃんと議論してみる価値は、かなり高い。
プロダクションでフル活用するのは、正直まだ様子見。
でも、
- 次のスプリント計画
- 次の新規プロジェクトのキックオフ
のタイミングで、
「うちのチームの AI 補助開発、三段階で言うとどこまでやる?」
という会話をしてみる――
そのきっかけとして、この方法論はかなり良い「たたき台」だと感じています。


コメント