
「LLMエージェントを社内で試したら、法務と情シスに一瞬で止められた」
そんな経験、ありませんか?😇
精度もコストもそこそこいい感じなのに、
・「ログはどこに残るの?」
・「誰が責任者なの?」
・「個人データ、勝手に学習させてないよね?」
と聞かれた瞬間、空気が一変するやつです。
実は今起きているAIガバナンス/法制度のアップデートって、
この「現場でAIが止まる理由」をかなり鋭く言語化し始めているんですよね。
一言で言うと:「AI版 SOX 法 時代」の入口に来ている

最近の動き(エージェントAIのガバナンス設計、保険業界のAIレポート、NIST IR 8587、東南アジアのデータ保護規制)を全部まとめて一言で言うなら:
「Jupyter で本番DBいじってた時代から、
SOX対応の基幹システム作れと言われ始めた瞬間」
にかなり似ています。
- 以前:
「とりあえずLLM呼んで便利にしようぜ」=素のPythonスクリプト感覚 - これから:
「エージェントは“業務担当者”だから、権限管理・ログ・責任分界を」=SOX/PCI-DSS対応のエンタープライズシステム
正直、ここを理解してないAIプラットフォームやスタートアップは、数年以内にエンタープライズ案件から締め出されると思っています。
今起きている「ニュース」を、あえて雑にまとめると
あまりニュース要約だけやってもつまらないので、開発者目線でざっくり雑に要約します👇
-1. モデルじゃなくて「エージェント」をガバナンスしろ
最近のガバナンス論は、
「モデルをどうチューニングするか」から
「ツール呼び出しして実際に仕事してる“エージェント”をどう管理するか」
に完全にピボットし始めています。
- エージェントは:
- APIを叩き、
- 取引を発生させ、
- 社内システムと外部SaaSをまたいで処理する
つまり、システムの“利用者兼実行者”として振る舞う存在になっている。
なので求められるのは:
- ポリシーエンジン(何を・誰が・どのデータに対して・どのツールで実行していいか)
- ガードレールレイヤー(PII露出チェック、危険なツール実行のブロック)
- フルのトレーサビリティログ(プロンプト/ツールコール/出力)
正直、「LangChainでサクッと作ったエージェントをそのまま本番に」は、
金融とか保険ではほぼ無理筋になりつつあります。
-2. 保険業界がぶつかった「AIスケールの壁」は、精度じゃなくてガバナンスだった
BCGのレポートが面白いのは、
「保険会社は PoC → 中規模までは行くけど、
そこから“全社展開”でほぼ詰んでいる」
理由が「モデル精度」ではなく、
- 差別・公正性ルール
- クレーム処理規制
- 説明可能性
- 記録・監査要件
みたいな法務・コンプライアンス側の要求に応えきれないから、という点。
開発者的には、「AUC上がりました!コスト下がりました!」と言いたいのに、
法務はこう聞いてくる👇
- なぜこのユーザーの保険料がこうなったのか、要因分解を説明できる?
- 禁止属性(人種・宗教・政治的意見 etc)を直接/間接に使ってない証拠は?
- 3年後に監査が入ったとき、当時どのモデルverでどのルールだったかすぐ出せる?
ぶっちゃけ、これを後付けで満たすのは地獄です。
-3. NIST IR 8587:責任の「線引き」をしにきた
NISTのIR 8587ドラフトは、一見「定義遊び」に見えますが、
エンジニア目線ではかなり刺さるポイントがあります。
- AIの責任主体を:
- モデル/ライブラリを作る「プロバイダ」
- 組合せてシステム化する「インテグレータ」
- 運用する「デプロイヤ/オペレータ」
- 使う「エンドユーザー」
に分解して、「誰が何のリスクに責任を持つべきか」を整理し始めている。
これが意味するのは:
これからの契約書・RFPには
「あなたはこのAIシステムにおけるどのロールで、どこまで責任を持つか」
をはっきり書かされる
ということです。
- OSSのLLMラッパー作ってるだけのつもりだったのに、
- 実は「高リスク用途のAIシステムの一部コンポーネント提供者」として
- 責任とドキュメント提供義務を背負わされる
…みたいな地雷も普通にありえます。
-4. 東南アジアのデータ保護法は、AIアーキテクチャを直撃し始めている
ベトナム・インドネシアの新しい/ドラフトのデータ保護規制は、
- 同意と目的限定(何のために集めたデータか)
- クロスボーダーデータ転送制限
- トレーニングデータとしての利用合法性
- 自動化された意思決定の透明性・異議申立
をかなり明示的に触り始めています。
雑に言うと:
「とりあえず全部のログをS3に貯めて、
いつか学習に使えたらいいな」
が法的にNGになる世界が、アジアでも到来している。
- データに「どこの国の誰の何目的の情報か」のタグをつけ、
- 「学習に使っていい/ダメ」「国外に出していい/ダメ」をポリシーベースで制御し、
- 削除依頼が来たら、そのデータを学習済みモデルからどう扱うかの方針まで決める
これを、最初からアーキテクチャに織り込んでないと詰むフェーズに入っています。
何が「本当に新しい」のか:モデルから「システム&エージェント」へ
ここまでの話を一段抽象化すると、新しさは2つです。
- ガバナンスの対象が「モデル単体 → エージェント+業務システム全体」になった
- 法律がアーキテクチャに口を出し始めた
-1. エージェントは「社員」だと思って設計しろ、という話
正直、「LLM = ちょっと賢いオートコンプリート」くらいのノリで見ていた頃と、
今のエージェントシステムの実態はまるで違います。
- 経費精算を登録する
- 保険金支払いを確定する
- 顧客にメールを送る
- 倉庫の在庫を操作する
これ、どれも「一社員がミスったら割とヤバい」動きですよね。
エージェントはこれを24時間365日、高速で、かつトレーサビリティが薄い形でやろうとする。
であれば、本来やるべきなのは:
- エージェントに「職務権限」を割り当てる(役職とACL)
- 高額取引は必ず人間の承認フローを通す
- すべてのアクションを人間が後からレビューできるように残す
つまり、「社員 + RPA + サービスアカウント」を足して3で割ったような存在として扱うこと。
この設計思想を持たずに「LangChainでエージェント作りました!」とやるのは、
ぶっちゃけ本番では使えないオモチャのまま終わる未来しか見えません。
-2. 法制度が「設計制約」になってきたという現実
昔は「法務チェック」はリリース直前の形式的儀式、みたいなノリもありましたが、
AIに関しては完全に順序が逆転してきています。
- データ目的限定 → データベース設計のやり方が変わる
- 訓練データからの削除権 → モデルアーキ選定が変わる(検索拡張型か、埋め込み保持期間か)
- 説明可能性要件 → 推論APIインタフェースそのものが変わる(理由コード、特徴量寄与)
つまり:
「アーキテクトが法務のアウトラインを理解していないと、
そもそも設計が成り立たない」
という、割としんどい世界線に入っています。
競合する「2つの世界観」:バニラエージェント vs ガバナンスファースト
ここが一番大事なポイントだと思っています。
-1. バニラ系エージェントフレームワークの限界
いわゆる「LangChainライク」なバニラフレームワークは、正直こういう思想です:
- ゴール:開発者が早く試せること
- 特徴:
- ツールチェーンの組み立てが簡単
- LLM切り替えが柔軟
- とりあえず動くものがすぐできる
でも、ガバナンスの観点で見ると:
- ログ形式がバラバラで監査しづらい
- 誰がどのエージェントに何をさせていいのか、権限モデルがない
- データの国・種別・目的によるルーティングができない
- NIST IR 8587的な「ロール」(プロバイダ/インテグレータ/オペレータ)を前提とした責任設計がない
要するに、
「プロトタイピングには最高だけど、
保険・金融・公共分野の本番にはそのまま持っていけない」
世界観です。
-2. ガバナンスファーストのAIプラットフォームが勝ちに来ている
対して、最近出てきている/これから伸びると見ているのが、
「最初から法務・コンプライアンス・監査部門を顧客に見据えたAIプラットフォーム」
です。
特徴としては:
- ポリシーエンジンが最初から中核にある
- 「このユーザー+この国のデータ+この用途では、このツールは使えない」みたいなルールを宣言的に記述
- すべてのエージェント/ツールコールが共通フォーマットでログ化され、監査向け検索ができる
- データに「PII/センシティブ/国/目的」などのタグを付けてルーティング
- NIST IR 8587のロールに沿ったドキュメント・責任分界を最初から用意
デメリットは当然あって:
- セットアップも運用も重い
- ベンダーロックインのリスク高め
- パフォーマンス的にも、ポリシーチェックやログ書き込みのオーバーヘッドが乗る
でも、保険・金融・公共・医療あたりのエンタープライズ案件では、
「早く動く」より「後から怒られない」方が圧倒的に価値が高い
ので、結果としてこっちが主流になると見ています。
Google CloudやAzure、各種SaaSベンダーも、
この「ガバナンスファースト」路線にかなり舵を切りつつあるのが実情です。
「AI保険」という発想が示す、本当の論点

BCGが言及していた「AI保険」(AI事故をカバーする保険商品)は、
単なるビジネストレンド以上に、重要な問いを投げています。
どこまでを「保険でカバーするリスク」とみなし、
どこからを「設計・組織上のコントロールで潰さなきゃいけないリスク」とみなすか?
- モデルの自然な誤差 → 保険である程度カバーしてもよい
- 差別的な設計や明らかなコンプラ違反 → 本来は保険で免責されてはいけない
ここを適当にやると、
- 「保険入ってるから、とりあえずリリースしようぜ」
というモラルハザードが普通に起きます。
正直、AI保険だけあって設計ガバナンスがないプロダクトは、
「セキュリティ保険に入ってるからパスワード平文保存でOK」くらい危険な発想です。
Gotcha:正直、ガバナンスはコストと複雑性の塊です
ここまでガバナンス礼賛っぽく書きましたが、現場エンジニアとしての本音もあります。
-1. ちゃんとやると、クソ重い
- ポリシーエンジンの設計・実装
- データ分類・タグ付けの整備
- 全LLMコールの標準化ログ
- リージョン/法域ごとの設定
これ、システム本体と同じくらいの工数がかかることもザラです。
しかも、多くの企業では:
- プロダクト側:早く出したい
- 法務側:リスクを最小化したい
- 経営側:コストも抑えたい
という構造的コンフリクトがあるので、
ガバナンス実装チームは常に板挟みになります。
-2. 規制はバラバラ&変わり続ける
- NIST IR 8587はUS中心だし、まだドラフト
- EUはAI Actで別のフレームを作ろうとしている
- 東南アジアは国ごとにローカル色強め
- 日本は「ガイドライン」ベースでふわっとしているが、徐々に実効性を増しつつある
つまり、
「一枚岩のコンプライアンス対応」なんて幻想で、
実際にはリージョン別・用途別にポリシーを差し替え可能な設計が必須
になってきます。
-3. 「ガバナンスやってます感」だけの箱だけが増殖するリスク
一番まずいのは、
- 立派なポリシードキュメント
- それっぽいダッシュボード
- ログはあるけど誰も見てない
という、「箱だけガバナンス」状態です。
- エージェントの役割定義が曖昧
- トレーニングデータの実態が把握されていない
- 人間のレビューは、忙しすぎてほぼスルー
この状態だと、「やってます」と言い張れるだけで、実態のリスクは減っていない。
それどころか、「安心だと思い込んで余計に攻める」分だけ、リスクは増えます。
じゃあ、開発チームは何からやればいいのか?
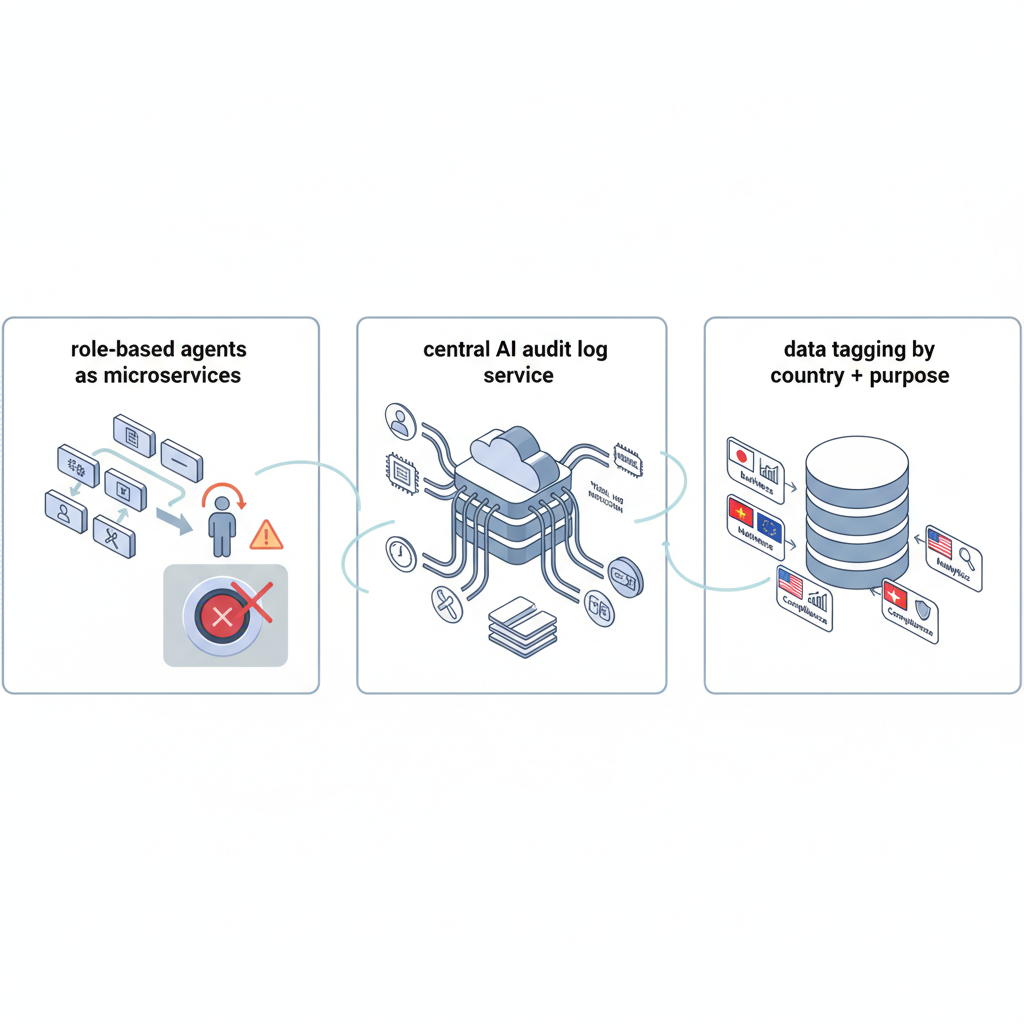
「全部やる」のは現実的じゃないので、個人的におすすめするミニマムセットはこれです👇
-1. エージェントを「黒魔術なLLM呼び出し」から「明示的な“役割持ちサービス”」にする
- すべてのエージェントに:
- 名前
- 役割(何の業務をするのか)
- 許可されたツールとデータスコープ
- 高リスク操作には必ず人間承認フローを挟む
- 「設定で即停止できる」Kill Switchを用意する
→ これはガチでマイクロサービス設計とほぼ同じ発想でできます。
-2. 共通のAI監査ログサービスを作る(雑でもいいので一箇所に集める)
- 記録すべき最低限:
- 誰が(ユーザーID/サービスアカウント)
- どのエージェントを
- いつ
- どのモデルバージョンで
- どのツールをどう呼んだか
- 主要な入出力のサマリ(PIIはマスキング)
ログ形式を最初から統一しておくだけで、
後からコンプライアンス/監査チームと話すときのストレスが段違いに減ります。
-3. データに「国+目的」のタグをつけるところから始める
いきなり完璧なDMBOKやらを目指すと死ぬので、まずは:
- country: JP / VN / ID / EU / US / other
- purpose: ops / analytics / training
- pii: yes/no
くらいの雑なタグから始めて、
LLM/エージェント経由のデータアクセスでこのタグを見て挙動を変えられるようにする。
これは東南アジア規制だけじゃなく、
そのうち本格化するであろう日本や他国のAI規制にも備える「保険」になります。
-4. 自社の「AIサプライチェーンにおけるロール」を一度言語化する
NIST IR 8587を完全に読み込まなくてもいいので、
- うちは:
- モデル自体を提供するのか?
- それを組み合わせたソリューションを提供するのか?
- 顧客の環境で運用まで責任を持つのか?
を一枚の図にするだけで、
今後の契約・責任境界・ドキュメント整備の方向性が見えてきます。
結論:プロダクションでガチ運用するか?正直「用途と業界次第で分かれる」
最後に、タイトルっぽいまとめをするならこんな感じです。
-
スタートアップ/非規制業界/社内効率化用途
→ 正直、今はまだ「バニラなエージェントフレームワーク+最低限のログ」でガンガン試していいフェーズ。- ただし、「将来ガバナンスをどう生やすか」の想像力だけは今のうちに持っておくべきです。
-
保険・金融・公共・医療・クロスボーダーB2B
→ ガバナンスファースト設計なしのエージェント運用は、かなり危険水域に入りつつある。- プロダクション投入を真面目に考えるなら、
- ポリシーエンジン
- 共通監査ログ
- データタグ付け
- ロール分担のドキュメント
は「MVPの一部」として最初から入れるべき。
正直に言えば、
「規制やガバナンスはイノベーションの足かせだ」という気持ちはエンジニアとしてめちゃくちゃ分かります。
でも、SOXやPCI-DSSの時代を思い出すと、
- あの時きちんと「ログ」「権限」「変更管理」を飲み込んだチームやベンダーだけが、
その後10年以上、大きな案件を取り続けた
という現実もあります。
AIも同じで、
「とりあえず動くエージェント」を作るチームから、
「責任を持って運用できるエージェントシステム」を作るチームへ
早めにマインドセットを切り替えた人たちが、
数年後の「ちゃんとしたAI案件」を総取りしていくはずです。
プロダクションでガンガン使うか?
高リスク業界なら、ガバナンス設計が追いつくまで “様子見という名の設計期間” に充てるべき、というのが今の自分の結論です。


コメント