
「朝イチで納期ギリギリの資料をClaudeに書かせようとしたら、
エラー連発で一文字も返ってこなかった」——そんな冷や汗、かきませんでしたか?
2025年7月のClaude.ai大規模障害、あれは単なる「ちょっと不便だったよね」の話ではなくて、
ぶっちゃけ「AI時代のAWS us‑east‑1大規模障害」だったと私は思っています。
一言で言うと、「AI版・初期AWSショック」

この7月のClaude障害を一言でまとめるなら、
「GenAI界の、初期AWSリージョン障害」
です。
- 完全ダウンではなく、
- タイムアウトしたり
- “Something went wrong” が増えたり
- 重めのプロンプトだけ妙に失敗したり
- だからこそ「動いてるチーム」と「完全に止まるチーム」が分かれた
正直、この「中途半端に死ぬ」のが一番タチが悪い。
インフラエンジニアなら、2010年代前半の us‑east‑1 が不安定だった頃 を思い出したはずです。
あの時も、
「クラウドって便利だけど、単一リージョンに全部乗せは自殺行為だな…」
と痛感させられましたよね。
今回のClaude障害は、それのAI版です。
なぜ騒ぐべきなのか?「おもちゃ」から「基幹SaaS」に変わった瞬間
これまでのChatGPTやClaudeの落ち方って、
「アクセス集中でちょっと重い」「たまにエラー」くらいで、
正直、“面倒だけど我慢できるレベル” でした。
でも2025年7月のClaudeは違いました。
- 高頻度で使っているチームほどエラー率が跳ね上がる
- 長文生成やコード生成など、「仕事を丸ごと置き換えていた部分」が壊れる
- Web UIだけでなく、裏側のAPIワークフローも一緒に巻き込まれる
ここで何が起きたかと言うと、
「LLMは便利なヘルパー」から「業務が乗った基幹SaaS」に昇格していたのに、
インフラとしての備えは“おもちゃ時代”のままだった
というギャップが一気に露呈した、ということです。
「プロンプト = 業務フロー」というヤバさ
さらに厄介なのが、
- ワークフローの手順書
- 社内ルールを織り込んだライティング方針
- 顧客対応のテンプレ
こういった業務ロジックのかなりの部分が、Claude向けのプロンプトに埋め込まれていたことです。
つまり、
- 業務フローの定義書
- 業務ロジックのソースコード
が「プロンプト」という形でClaudeの前提にロックインされていた。
Claudeが落ちた瞬間、その“業務実装”ごと消えるわけです。
正直、これは
「業務ロジックを1つのLambda関数に全部書いてて、そのリージョンが落ちた」
のと同じレベルの設計ミスだと思っています。
競合比較で見える「本当に怖いポイント」
OpenAIだけ使ってる人、「他人事」じゃないです
この障害を聞いたOpenAI勢から、
「うちはGPTだから大丈夫でしょ」
という空気も少し感じましたが、ぶっちゃけ全然大丈夫じゃないです。
- OpenAIも過去に容量不足・エラー多発は何度もあった
- Claudeは比較的安定イメージが強かったのに、今回大きく崩れた
- つまり、“どのベンダーでも普通に落ちる”が現実だと証明された
今回の事件で得られた教訓は、
「Claudeが危険」ではなく「単一AIベンダー前提の設計が危険」
ということです。
マルチLLM対応ツールだけが静かに得をした
この障害で一番得をしたのは、
- Claude + OpenAI + Gemini + ローカルLLM
など複数ベンダーを裏で切り替えられるオーケストレーション系ツール
です。
逆にダメージを受けたのは、
- 「うちのプロダクトはClaude専用です!」
- 「このエージェントフレームワークはClaude最適化!」
と単一LLM依存を売りにしていたプロダクトたち。
クラウド初期に「うちは完全AWS専用PaaSです!」と謳っていたベンダーが、
マルチクラウド派の登場で一気に不利になっていった歴史と、かなり重なります。
技術的にはこう見える:単一LLMはただの「単一障害点」
エンジニア視点で整理すると、今回の障害で壊れたのは主にここです:
- アーキテクチャ
- アプリや社内ツールからClaudeを直叩きしている
- LLM Gateway / Adapterレイヤーが存在しない
-
結果として、Claude = 単一SPoF(単一障害点)
-
オブザーバビリティ
- 「なんか遅い」「エラーが増えた気がする」以上のものがない
-
ヘルスチェック・エラーレートのダッシュボード・アラートがない
-
BCP(事業継続計画)
- 「Claudeが3〜24時間丸ごと死んだらどうするか?」の想定がない
- 手動運用フローもバックアップLLMも決まっていない
正直、インフラなら新人レビューで全部差し戻されるレベルの設計ですが、
「AIだから」と油断してここをすっ飛ばしていたチームが多かった印象です。
「マルチLLMにすれば安心」は、実は半分ウソ

もちろん対策として、
「LLMアダプター作って、Claudeが落ちたらGPTにフェイルオーバーすればOK!」
という話はよく出てきます。
私も基本的には賛成ですが、ぶっちゃけそんなに甘くないです。
エンジニアリングコストが普通に重い
- 共通の
generateText(request)的なAPIを自前で用意 - 各ベンダーごとのクライアント・トークン管理・レート制御
- プロバイダごとに微妙に違うパラメータ・制限の吸収
- さらにヘルスチェック・リトライ・バックオフ・メトリクス送信…
「ちょっとif文足す」どころではなく、
ちゃんとしたミニサービスを1個建てる覚悟が必要です。
プロンプトは意外とポータブルじゃない
これもよく誤解されますが、
「プロンプトはテキストだから、他のモデルにも流用できるでしょ」
というのはかなり楽観的です。
- 同じ指示でも、LLMごとに
- 出力フォーマット
- トーン
- 厳密さ
が結構違う - 日本語の自然さ、コード生成のクセ、長文の要約スタイルも差がある
結果として、
- Claude用プロンプト
- GPT用プロンプト
- ローカルLLM用簡略プロンプト
みたいにプロバイダ別バリアントを管理するハメになります。
「業務ロジックのロックイン」はほぼそのまま残る
もっと根が深いのはここです。
たとえ裏でLLMを差し替えできるようにしても、
- 業務プロセスの知識
- 例外ケースの扱い
- 社内ルールの細かい表現
がすべてプロンプトにベタ書きされているなら、
それは結局「Claude前提で書かれた業務ロジック」を他モデルに無理やり流しているだけです。
本気でロックインを避けたいなら、
- 業務フローの定義(状態遷移・ルール)をコードや設定として別管理
- LLMはあくまで
- 補完
- 要約
- 書き換え
をする“推論エンジン”に限定
という設計に寄せていく必要があります。
ここまでやって初めて、「LLMアグノスティックな業務実装」と言えます。
「AIに頼りすぎた組織」が丸裸になった
今回一番エグかったのは、技術より組織面です。
- カスタマーサポート:
AIエージェント前提で人数をギリギリまで絞っていたチームは、問い合わせに追いつけなくなる - コンテンツ制作:
社内ライターを削減し、AIライティング前提の納期で回していたメディアは、原稿が止まる - エンジニアリング:
AIコーディング支援に依存していた若手が急に手が止まる
要するに、
「AI前提で最適化しすぎたオペレーション」が、
Claude一つコケたくらいで簡単に崩壊する
ことが露わになりました。
クラウド時代に
- オンプレ運用スキルを全部捨てる
- 自前バックアップも一切しない
みたいな極端な移行をしていたら危険だったのと同様で、
「AI抜きで最低限回せる運用力」もBCPの一部として扱う必要があります。
それでもClaudeをプロダクションで使うか?正直こう考えている
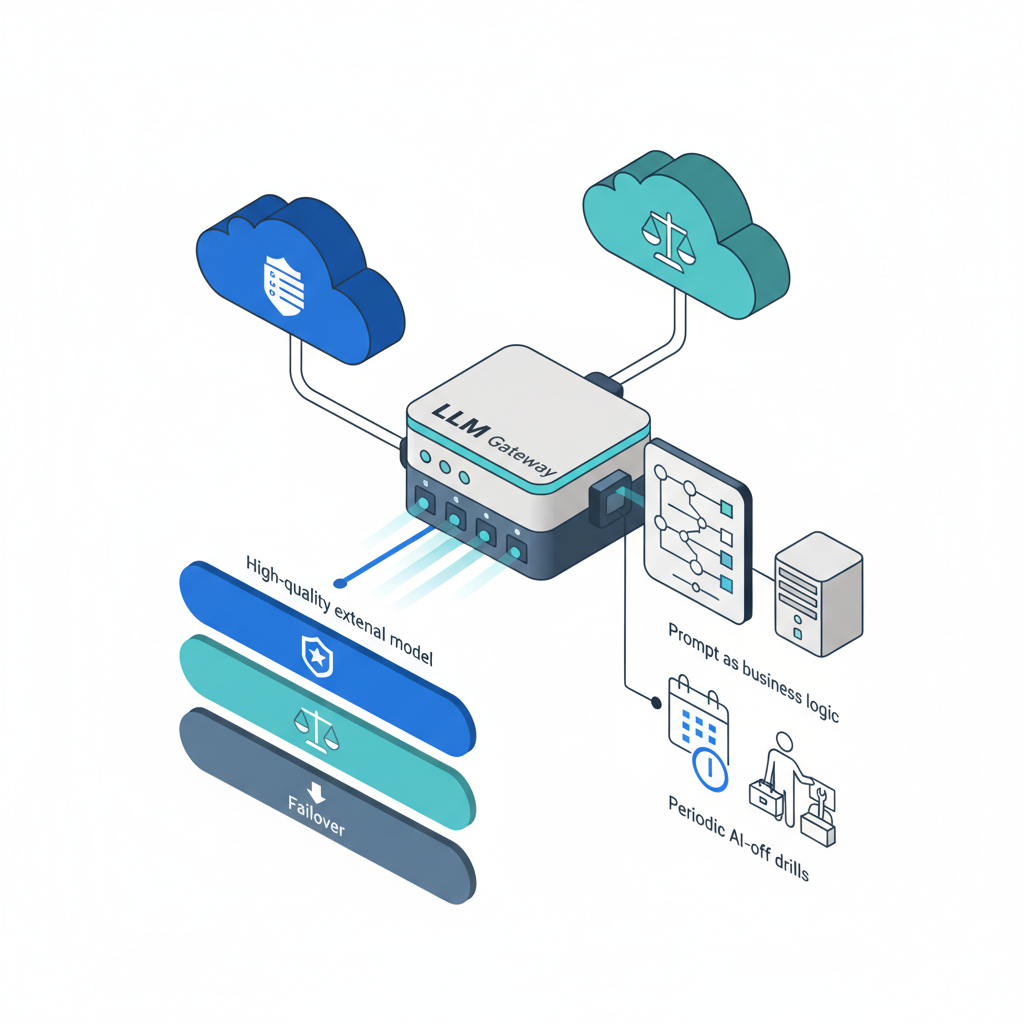
では今回の障害を踏まえて、
「Claudeをプロダクションで使うべきか?」という話。
私の結論はかなりシンプルで、
「使う。ただし“単一大脳”としてではなく、“プラグイン可能な部品”として」
です。
私がやるなら、最低限これだけはやる
- LLM Gatewayの自前実装
- アプリから直接Claudeを叩かない
-
自前の
LLMサービスを挟んで、そこからClaude / GPT / ローカルに振り分け -
Tier別の劣化運転プラン
- Tier 2: 通常時 → Claudeメイン(品質優先)
- Tier 1: 障害時 → GPT or Geminiにフェイルオーバー(品質そこそこ)
-
Tier 0: それすら死んだ場合 → 手動+既存ツールに切替(速度犠牲)
-
プロンプトを“業務ロジック”として扱う
- Git管理 & レビュー
- モデル別バリアントを明示
-
「この業務ルールは仕様書にも書く」を徹底
-
定期的な「AIなし運用」の訓練
- 年に1〜2回くらい、あえてAIをオフにして業務してみる
- 「どこが人力でカバーできないか」を洗い出す
ここまでやって初めて、
Claude障害級のイベントが来ても「まあしんどいけど、死にはしない」
と言えるラインだと思います。
まとめ:今回の障害を「ただのトラブル」で終わらせないために
今回の7月Claude障害は、
- Anthropicの信頼性問題
ではなく、 - 私たちのアーキテクチャ設計と組織運用の甘さ問題
として受け止めた方が健全です。
正直、今のGenAIブームの勢いを見ると、
- プロンプトに業務ロジックを全部押し込む
- 単一LLM前提で人員配置を最適化する
みたいな設計は、かなり危険な匂いがします 🤔
クラウド初期に「可用性設計」を学んだように、
いま私たちは「AI可用性設計」を本気で学ぶフェーズに入っただけです。
ぶっちゃけ、Claudeを切るかどうかよりも先に、
「Claudeがまた落ちても、会社が止まらない設計になっているか?」
を自問した方がいい。
プロダクションで使うか?
私の答えは、
「使う。ただし、Claudeが“落ちる前提”でアーキテクチャと組織を作り直してから」
です。
この障害を“GenAI版・us‑east‑1ショック”としてちゃんと消化できるかどうかが、
数年後に「あのときAIに振り回されてた会社」と
「AIを前提にしても倒れない会社」を分けるポイントになるはずです。


コメント