
「RAGを足せば何とかなる」と思っていたLLMアプリ、気づいたらコードが地獄のように絡み合っていませんか?
プロンプトの周りにRAG、メモリ、ツール呼び出し、ユーザ状態、ポリシーチェック…全部ごちゃ混ぜ。
「どこを直せばこのバグが直るのか誰も説明できない」――2024年のLLMアプリあるあるだと思います。
そんな中で公開されたのが、Zennの連載「Context Management 2025」シリーズ。
正直、これを「ただのRAGチュートリアル」だと思ってスルーすると、数年後に後悔するタイプのやつです。
一言でいうと:LLM界の「認証基盤をIDPに切り出そう」ムーブ
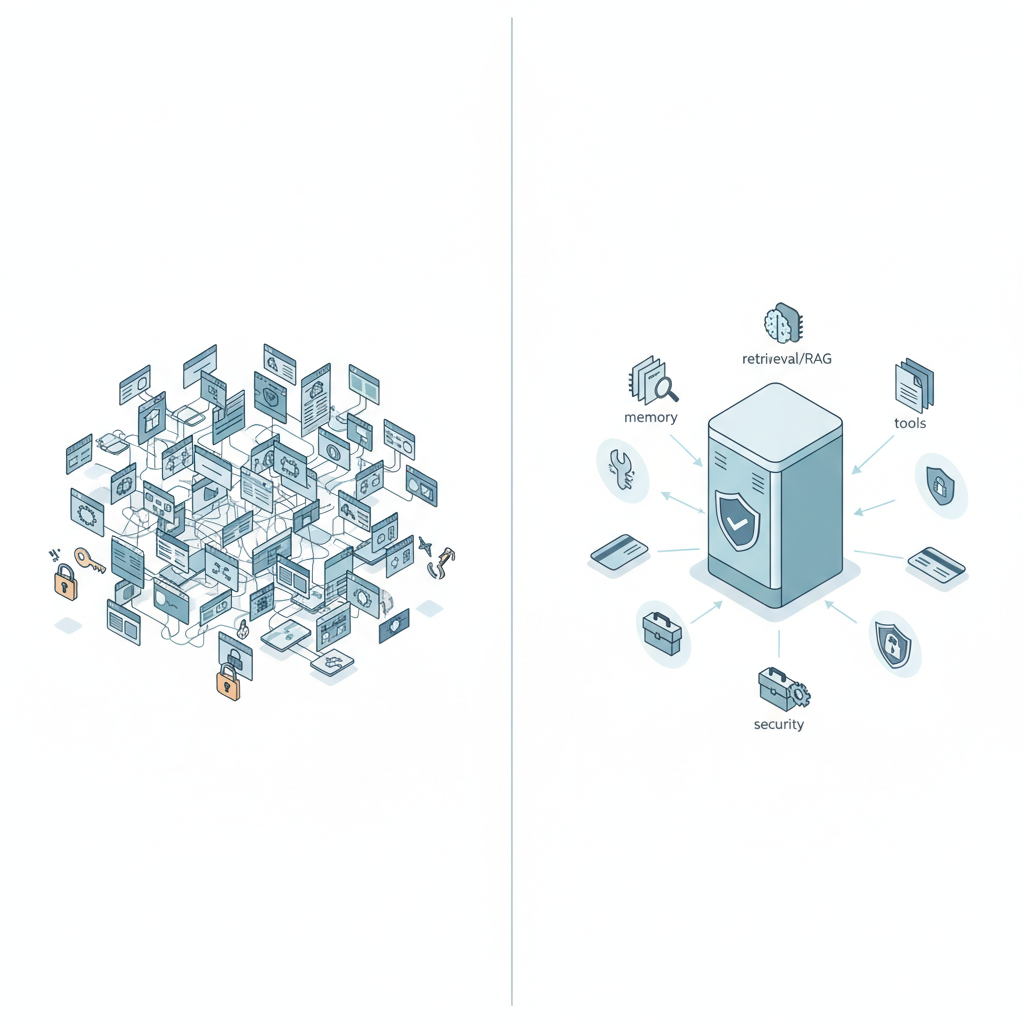
この連載がやっていることを乱暴に一言でまとめると、
「コンテキスト管理を、アプリ内の小細工から、組織横断の共通基盤に格上げしよう」
という提案です。
歴史的な比喩でいうと、まさにこれ👇
- かつて:
- 各Webアプリがログイン/セッション/認可を自前実装
- 「パスワードはSHA1でハッシュしとけば安全っしょ」みたいな時代
- その後:
- OAuth2 / OpenID Connect / IDPの登場
- 「認証はID基盤に投げる。アプリはトークンを信じるだけ」という世界へ
今回の「Context Management 2025」は、
この「ID基盤ムーブ」を RAG・メモリ・ツール・セキュリティを含めた“コンテキスト全般”に持ち込もうとしている、というのが本質だと感じました。
何がそんなに新しいのか:ただのRAG分離じゃないポイント
「コンテキストを別レイヤーに切る」と聞くと、
「ああ、RAGまわりをマイクロサービス化する話ね」
くらいに聞こえるかもしれませんが、この連載はそこに留まっていません。
「Context Orchestrator」という明確な中核コンポーネント
連載では、アプリとLLMのあいだに Context Orchestrator をドンと置いています。
- Context Source
- DB / Vector Store / Logs / CRM など
- Context Processor
- 要約 / フィルタリング / ランキング / 正規化
- Context Store
- セッション、ユーザ長期メモリ、ポリシー
- Context Policy / Guardrail
- 権限、PII制御、コンプライアンス
- Context Provider
- アプリやエージェントが叩くための統一API
これらを全部まとめて制御するのが Orchestrator。
ぶっちゃけ「LLM用の“コンテキスト版APIゲートウェイ”」といった方がイメージしやすいです。
「RAG = コンテキスト」という雑な理解をぶった切る
シリーズで一番いいなと思ったのは、コンテキストを5つ以上の独立した次元に分解している点です。
- 会話コンテキスト(turn / session / user)
- 知識コンテキスト(ドキュメント / コード / FAQ …)
- 実行コンテキスト(ツール呼び出し履歴、ワークフロー状態)
- セキュリティコンテキスト(ロール、権限制御、データ境界)
- 環境コンテキスト(デバイス、チャネル、feature flags…)
多くの現場で「RAGうまくいかないんだよね」と言ってるとき、
実際には「知識コンテキストしか見ていない」のに、
会話ログやセキュリティ、実行履歴を完全に無視してるケースがほとんどなんですよね。
この連載はそこをちゃんと言語化して、
「Context Management = 複数種類の文脈を統合制御するレイヤーだ」
と定義し直している。
これは概念としてかなり大きな一歩だと感じました。
エージェントに「何でもやらせる病」からの脱却
最近のLLMエージェントは、
「ツールも叩くし、RAGもするし、メモリも持つし、ポリシーも守る」
みたいな なんでも屋モンスター になりがちです。
この連載はそこに明確にNoを突きつけていて、
- エージェント:意思決定・計画・NLI(自然言語インタフェース)
- Context Layer:
- コンテキスト収集・正規化・フィルタリング
- 永続化・再利用・ポリシー適用
という役割分担を徹底するパターンを提案しています。
正直ここは激しく同意で、
「エージェントに責務を盛りすぎて、誰も触りたくないクラスになった」
という現場をいくつも見てきた身としては、ようやく出てきた正気の提案という感じがします 🤔
これは誰と戦うアーキテクチャなのか:LangChainとの距離感

連載中でもほのめかされていますが、
この思想はかなりはっきり 「アプリ内完結フレームワーク」へのアンチテーゼ になっています。
LangChainとの比較
共通点はあって、
- LLM入力をただのテキスト結合から抽象化しようとしている
- コンテキスト収集・前処理・ポリシー適用に関心がある
という意味では同じ文脈です。
が、決定的に違うのはここ。
- LangChain:
- 開発者がアプリコードの中でRAG・メモリ・エージェントを組み上げるライブラリ
- 基本的に 各アプリプロセス内に埋め込まれる
- Context Management 2025:
- Context Layerを アーキテクチャ上の独立レイヤー/サービス として設計
- 複数アプリ・複数エージェントから 共通で呼ばれる「社内コンテキスト基盤」 を想定
つまり、発想が根本的に違います。
- LangChainマインド:
→ 「このアプリでどうRAGとエージェントを組むか?」 - Context Managementマインド:
→ 「この組織でどうコンテキスト基盤を提供し、全アプリに再利用させるか?」
Googleと比較するなら、
LangChainは「アプリ開発者向けのGASスクリプト集」だとすると、
Context Management 2025は「社内向けのFirebase/Cloud Functions基盤」を設計しようとしている、みたいな距離感に近いです。
大企業 vs スタートアップ での向き・不向き
- 大規模組織:
- 正直、この連載で描かれている世界観にかなりフィットします。
- 各事業部がバラバラにRAG・メモリ・ログ処理・ポリシーを実装している現状から、
- 「Context Platform Team」を立てて
- 各プロダクトはそのAPIを叩くだけ
-
という構造にするのは、将来のガバナンスや監査を考えると合理的です。
-
小規模スタートアップ:
- ぶっちゃけ、今このアーキテクチャをフルで採用するとオーバーエンジニアリング だと思います。
- 3人チームでPoC回してるのに、Context Orchestratorのマイクロサービス分割とかやり始めたら本末転倒。
- LangChainなりLlamaIndexなりをアプリ内で素直に使う方がはるかに現実的です。
「これ、結局どのくらい痛いBreaking Changeなの?」という話
連載でも触れられていますが、これはライブラリ更新ではなく アーキテクチャ提案 です。
なので「既存コードが突然動かなくなる」タイプのBreakingではありません。
が、実質的にはかなり重いアーキ変更になります。
- いま:
- アプリごとにRAG実装・メモリ・ログ・ポリシーがバラバラに内蔵
- これから:
- それらを全部Context Layerに引き剥がして
- アプリ側からは
getContext(requestContext)みたいなAPIで呼ぶだけにする
となると、
- メモリやRAGの実装を分離・再設計
- API境界の引き直し
- ログ/監査/セキュリティのパイプライン整理
…と、中規模以上のリファクタリング はほぼ確定です。
正直、一度炎上しているプロジェクトにこの話を持ち込むと、
「今それどころじゃない」と即座に跳ねられるレベルの重さはあります 😅
実務者視点での「これはいい」と「これはキツい」

「これはいい」ポイント
- 責務分離でコードが読みやすくなる
- 「プロンプト生成まわりに何でも詰め込んだ結果、誰も触れない関数」が減る。
-
プロンプトまわりはあくまでUI層の一部、
コンテキスト収集・加工は別レイヤー、という整理は現場的にも嬉しい。 -
チーム分割がしやすくなる
- 「AI基盤チーム」と「アプリ開発チーム」を分けやすい。
-
Context Layerを改善すれば、複数アプリの品質が一気に底上げされる。
-
ポリシー変更・A/Bテストが中央集権でできる
- コンテキスト構成を「バージョン」として管理し、
- あるアプリだけContext v3.2を試す、みたいな運用が可能。
-
「ある日突然、全社のRAG挙動が変わった」みたいな事故を避けられる。
-
Observability設計がしやすい
- コンテキスト決定過程をログに残す前提の設計になっているので、
- 「なんでこの回答になったの?」を後追いで説明しやすい。
「これはキツい…」と思う懸念点
複雑性爆上がり問題
正直、このアーキテクチャをそのままPoCに持ち込むと、
コードの9割が基盤・パイプライン、1割がビジネスロジック
になりかねません。
- Context Source/Processor/Store/Orchestrator/Policy…
- 同期/非同期、オンライン/バッチの両対応
- オブザーバビリティ、セキュリティ、コンプライアンス…
と、非機能要件の設計コストが一気に上がる。
「とりあえずGPT+VectorDBで業務改善できるか試したい」というフェーズなら、
ここまで作り込むのは正直やりすぎです。
「内製ロックイン」の危険
ここはあまり語られていませんが、かなり本質的な懸念です。
- 真面目にContext Layerを作り込むほど、
- 「社内専用のContext API / スキーマ」に依存したアプリが増える
- 数年後:
- もしクラウドベンダーが「Managed Context Platform」みたいなものを出してきたとき、
- そこへの乗り換えコストが爆死する可能性
ID基盤の歴史でいうと、
- 2000年代前半に各社自前で認証基盤を作り込んだ結果、
- その後のIDaaSやクラウドIDPへの移行にみんな血を吐いていた、
…というあの歴史を繰り返すリスクがあります。
モデル進化とのギャップ
2025〜2026年にかけて、
- コンテキスト長の爆増
- モデル側のオンザフライRAG/内蔵インデックス機能
が進んでいくと、
いま人間が頑張って設計しているContext Layerの一部は、
モデルに内蔵された機能とガチで競合 して、要らなくなる可能性があります。
特に、
- 高度な要約
- 再ランキング
- マルチソースのマージ
みたいなところは、モデルに丸投げした方が強くなる未来も十分あり得る。
なので、Context Layerは
「永遠に必要な不変レイヤー」
ではなく、
「数年後には役割が変わるかもしれない“暫定的な分離レイヤー”」
くらいに捉えて、疎結合な設計 を意識しておかないと痛い目を見ると思います。
技術より組織がボトルネックになる
連載を読むとすごくきれいに整理されていますが、
実際にやると必ずぶつかるのが組織の問題です。
- どのデータをどの事業部まで共有してよいか
- PIIをどの粒度でマスクするか
- LLMが参照してよいログ/メモリの範囲
- 監査証跡の保持期間・開示範囲
このあたりは 技術じゃなくて政治の世界 です。
「技術的にはできます」は、ガバナンス会議では何の説得力も持たないことが多い。
ここをどう進めるかは、連載の範囲をはみ出す話ではあるものの、
実務者としては一番ハードル高いポイントになるだろうなと感じました。
じゃあ、プロダクションで今これを採用するか?
ぶっちゃけトーンで言うと、こんな感じです。
-
大規模組織で、すでにLLMアプリが乱立している会社
→ 「いますぐ全社アーキテクチャの議論のテーブルに乗せるべきテーマ」- ただし、一気に全面採用ではなく、
- 1〜2プロダクトで 「Context Platform v0」 を検証する形が現実的。
-
小規模〜中規模で、これからLLM本格導入を考えている会社
→ 「Conceptとして頭に入れておき、
増え始めたタイミングで“共通コンテキスト基盤”への移行を計画する」くらいがちょうどいい。 -
PoCフェーズ・ハッカソンレベルのプロジェクト
→ 正直、今はまだ様子見でいいと思います。- このアーキテクチャを真面目にやると、それだけでプロジェクトが終わります。
個人的な結論:「プロンプト職人芸」から「プラットフォーム設計」への転換点として読むべき
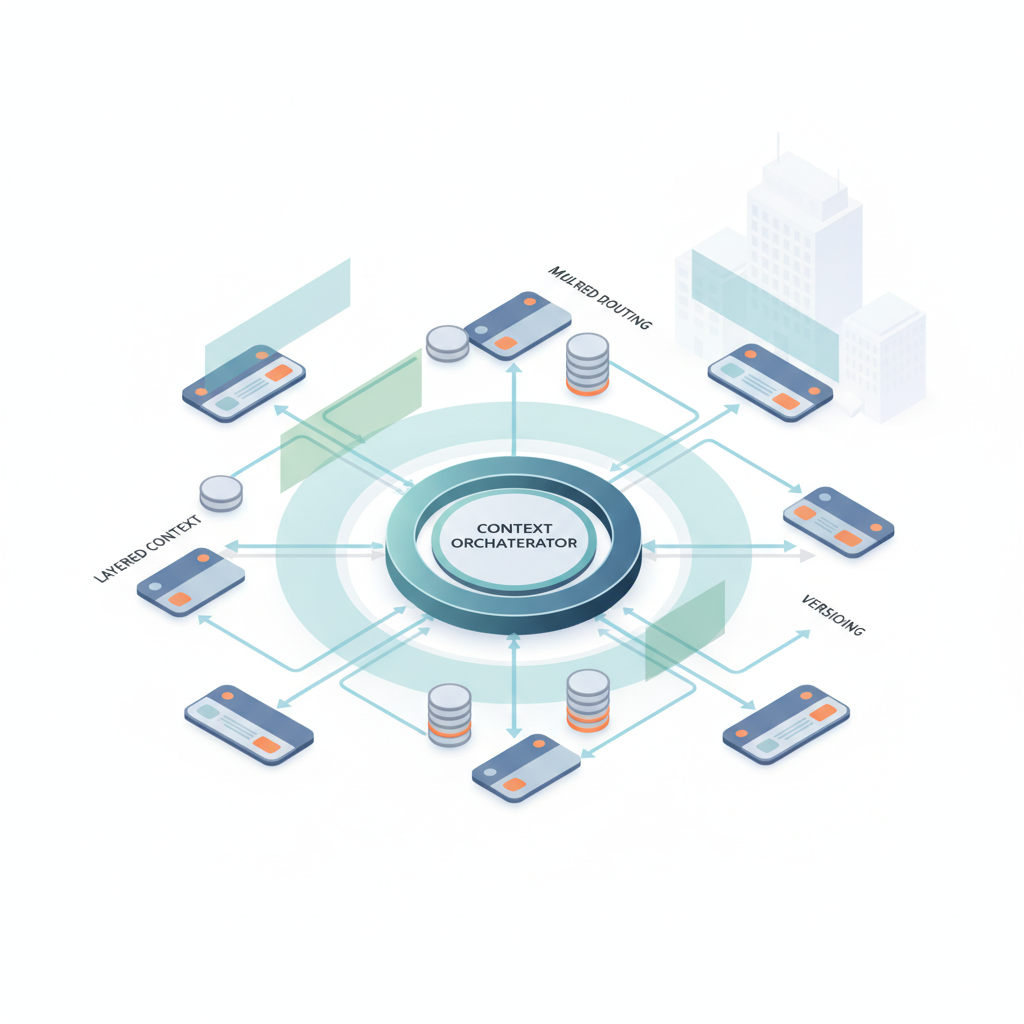
この「Context Management 2025」連載を、
単なる「RAGのベストプラクティス集」として読むと、たぶん物足りなく感じます。
本質的には、
LLMアプリ開発を、「個々のアプリの職人芸」から
「組織横断のプラットフォーム設計」に引き上げるための思想ドキュメント
として読むとしっくりきます。
- Context Orchestratorを中心としたレイヤー分離
- マルチディメンション・コンテキストの明文化
- Layered Context / Context Routing / Versioning といった運用寄りパターン
- 統合実装例によるエンドツーエンドのリファレンス
これらは、2025年以降に
- 「社内で10個以上のLLMアプリを本番運用している組織」
にとって、ほぼ避けて通れない論点になるはずです。
正直、
「いますぐ全部取り入れろ」とはとても言えない くらい重い話でもあります。
ただ、
「こういうレイヤー分離を前提に設計すべきなんだ」という“物差し” をくれた、という意味で、この連載はかなり重要なマイルストーンだと感じました。
少なくとも、次にLLMアプリの設計レビューをするときに、
- 「このロジック、本来はContext Layer側の責務じゃない?」
と一度立ち止まって考えるきっかけにはなるはずです。
その意味で、「今すぐ全面採用はしないけど、アーキテクト全員が読んでおくべき連載」というのが、現時点での私の率直な評価です 🚀


コメント