
「また新しいLLM出たけど、
・数学だけは微妙
・コードは動くけどテスト通らない
・長い仕様を投げると途中から話がズレる
…そんな経験、ありませんか?」
正直、ここ1〜2年のLLMアップデートって「スコアは伸びてるけど、実務のつらみはあまり減ってないよね?」というモヤモヤがありました。
そこに出てきたのが、DeepSeekが公開した「高度AIモデルの新しい訓練手法」です。
一言でいうと、
GPUを盛るゲームから、「どう育てるかの設計勝負」にステージを変えにきた
そんな動きだと感じています。
一言でいうと、これは「React Hooks が出たとき」と同じ匂いがする

ニュースを超ざっくり言うと:
- DeepSeekが、
- 事前学習 → SFT → RLHF/RLAIF → カリキュラム的なタスク特化
を一体として設計した「訓練パイプライン」の思想をかなり詳しく公開 - 特に、
- 推論・数学・コードに“かなり”振ったデータ設計とスケジューリング
- 巨大クラスタ前提じゃないコスト効率重視の訓練戦略
を明示 - しかも、中国発ベンダーとしてはかなり異例なレベルで「訓練ノウハウ」を開示
これ、React Hooks がクラスベースの「書き方」から、
「状態と副作用をどう設計するか」という“考え方”を公開したときに近いです。
- どれだけGPUを積んだか、ではなく
- 「能力をどう段階的に育てたか」という“設計パターン”を晒してきた
ここが今回の一番面白いポイントだと感じています。🚀
DeepSeek は何を「新しく」したのか:中身をざっくり分解
技術的な話は記事にも書いてありますが、実務者目線で要点だけ抜くと:
訓練を「一連のカリキュラム」としてちゃんと設計した
- フェーズ1:事前学習(一般知識+言語感覚)
- フェーズ2:SFT(指示追従・礼儀・フォーマット)
- フェーズ3:RLHF/RLAIF(実用的な回答への“好み調整”)
- フェーズ4:数学・コード・長期推論に特化したカリキュラム学習
ポイントは、「あとから数学用のデータちょっと足しました」ではなく、
最初から「数学・推論・コードに強い汎用LLM」をゴールに据えて、
データ配分と難易度スケジュールを設計している
という点。
たとえば:
- 数学:四則演算 → 記号変換 → 論証・証明
- コード:バグ修正 → リファクタリング → 新規実装 → マルチファイル対応
- 推論:Chain-of-Thought を明示的に学習させる一部タスク
これを長期的なカリキュラムとして組んでいるのがミソです。
「推論・数学・コード」に全振りしたデータ設計
最近の多くのモデルは「とりあえず何でもできるチャットボット」を目指しつつ、数学やコードは「そこそこ強い」止まりになりがちです。
DeepSeekはそこを逆に振っていて、
- 一般チャット性能は十分レベルを確保しつつ
- 推論・数学・コードのためにトークンの配分と難易度カーブをかなり意識している
つまり、
「何でもできるけど器用貧乏」から
「実務で使える“理系アシスタント”」に寄せている
という設計思想が読み取れます。
コスト効率とスケール戦略をちゃんと語った
正直ここが、スタートアップ/SIer目線で一番重要だと思っています。
- 「巨大クラスタ持ってません」でも、
どのフェーズで - どの品質のデータに
- どれくらいGPUを突っ込むべきか
- をかなり具体的に語っている
AI界隈って、すぐ「○万GPUで○ヶ月回しました」みたいな武勇伝になりがちですが、
DeepSeekはそこを「どう節約しながら性能を出すか」に寄せている。
資本ゲームから、エンジニアリングゲームへのシフトを本気で狙っている感じがします。🤔
なぜ重要か:これは「2nd tier ベンダー殺し」になる

OpenAI, Anthropic, Google みたいなトップ層は、正直この一発で揺らぐことはないでしょう。
でも、一番ダメージを食らうのはここです:
中規模LLMスタートアップ/中国内外の2nd tier モデルベンダー
今までこのゾーンのベンダーがよく言っていたのは:
- 「うちは独自の訓練ノウハウがあります」
- 「プロプラだけど、そこが我々の秘密ソースです」
というストーリー。
そこに対してDeepSeekは、
「じゃあ、うちは訓練戦略ほぼ思想レベルまで晒すけど、
その上で性能もコスト効率も勝ちに行くね」
と宣戦布告したようなものです。
結果どうなるかというと:
- 研究者 / OSSコミュニティ:
- DeepSeek流のパイプラインを“デフォルト設計パターン”として参照し始める
- 企業の技術選定:
- 「自称ノウハウ」より、「ちゃんと訓練哲学を透明化している DeepSeek系」を信頼しがちになる
つまり、“なんとなくやってます”なブラックボックスLLMの価値がどんどん目減りする。
競合と比べてどこが違うのか
OpenAI / Anthropic / Google との比較
- 共通点
- 多段階パイプライン(Pre-train → SFT → RLHF → Task-specific)
- 数学・コード・長文推論を重視
- 違い
- 彼らは詳細なカリキュラム戦略までは滅多に表に出さない
- モデルサイズ・データ詳細はだいたいブラックボックス
DeepSeekはここに対して:
「どうやって推論能力を伸ばしたか」を、思想レベルでかなり具体的に開示
しているわけです。
正直、この「思想まで開示」は北米大手勢があまり得意じゃない領域で、
研究コミュニティやOSS開発者からは相当好意的に受け止められると思います。
Claude 系との違い(Anthropic vs DeepSeek)
ざっくりまとめると:
- Anthropic
- ターゲット:北米・欧州のエンタープライズ
- 強み:安全性・ガバナンス・コンプライアンス
- 戦略:超巨大モデル+Safetyアーキテクチャ
- DeepSeek
- ターゲット:中国・アジア+グローバル開発者
- 強み:訓練手法の開示+コスト効率
- 戦略:限られた計算資源での性能最大化
開発者視点だと、
「GPT-4 / Claude は高いし中身ブラックボックスすぎる」
という不満に対する“第3の選択肢”
として、DeepSeek流の「訓練思想までオープンな高性能モデル」はかなり魅力的です。
ただし、懸念もデカい:「ベンチマーク番長」リスク

コミュニティの反応を見ていて、一番よく出てくる声がこれです:
公開ベンチでは確かに強いんだけど、
自社のプライベートベンチにかけると、
「あれ?案外イマイチじゃない?」ってなるケースが多い
つまり、
- MATH / HumanEval / 各種公開ベンチでは強い
- でも
- 自社コードベース
- 特定ドメイン(金融・医療・製造 etc.)の数理問題
では、必ずしも勝てない
という報告が出始めている。
正直、
「ベンチマークに最適化されたモデルじゃないの?」という懸念は消えていません。
これ、開発者としてはめちゃくちゃ重要で、
結局、公開スコアだけ見て「DeepSeek最強!」と一本化するのは危険で、
自分たちのワークロードでA/Bテストしないと話にならない
という当たり前の結論に落ち着きます。
実務的に効いてくる「隠れた落とし穴」
パイプラインが豪華になるほど、運用が地獄になる
今回のDeepSeekのパイプライン、読む分にはワクワクするんですが、
自前で真似しようとするとこうなります:
- フェーズごとのデータセット構築
- 難易度コントロールされた数学・コード問題の用意
- RLHF/RLAIF の評価システム(AIジャッジ+人間ラベラー)
- ログ・メトリクスの設計と分析
GPUよりも先に、人と運用がボトルネックになります。
ぶっちゃけ、中小企業や研究室が
「よし、うちもDeepSeek流パイプラインを全部再現しよう!」
と言い出したら、それはかなり危険な香りがします。
現実的には、
- まずは DeepSeek の公開モデルをそのまま使う
- 必要に応じて、自社タスクに近い部分だけ少量のSFTを足す
くらいが限度でしょう。
「オープン」とはいえ、完全に再現できるわけではない
今回公開されているのは、主に:
- 設計思想
- フェーズ構成
- どの段階で何を重視したか
であって、
- 生データ
- フルの訓練スクリプト
- 全バリエーションのモデル重み
がガッツリOSSになっているわけではありません。
結果として、
「思想はオープンだけど、性能を再現するのは実質無理」
→ だから結局 DeepSeek モデルそのものを使うのが一番早い
という、ソフトなベンダーロックインの形になりやすい。
モデルの「思考スタイル」に依存した設計になる危険
DeepSeekのように、推論過程(Chain-of-Thought)までしっかり学習させたモデルは、
- 特定の思考分解パターン
- 特定の出力スタイル
を強く持ちがちです。
そこに合わせてアプリ側が、
- 特定のプロンプトテンプレート
- 「このモデルはこう推論してくるはず」という前提のロジック
を組み込んでしまうと、
後から GPT / Claude / 他モデルに乗り換える時、
思った以上に移植コストが高くなる
という未来がかなりリアルに見えます。
じゃあ、開発者としてどう向き合うべきか
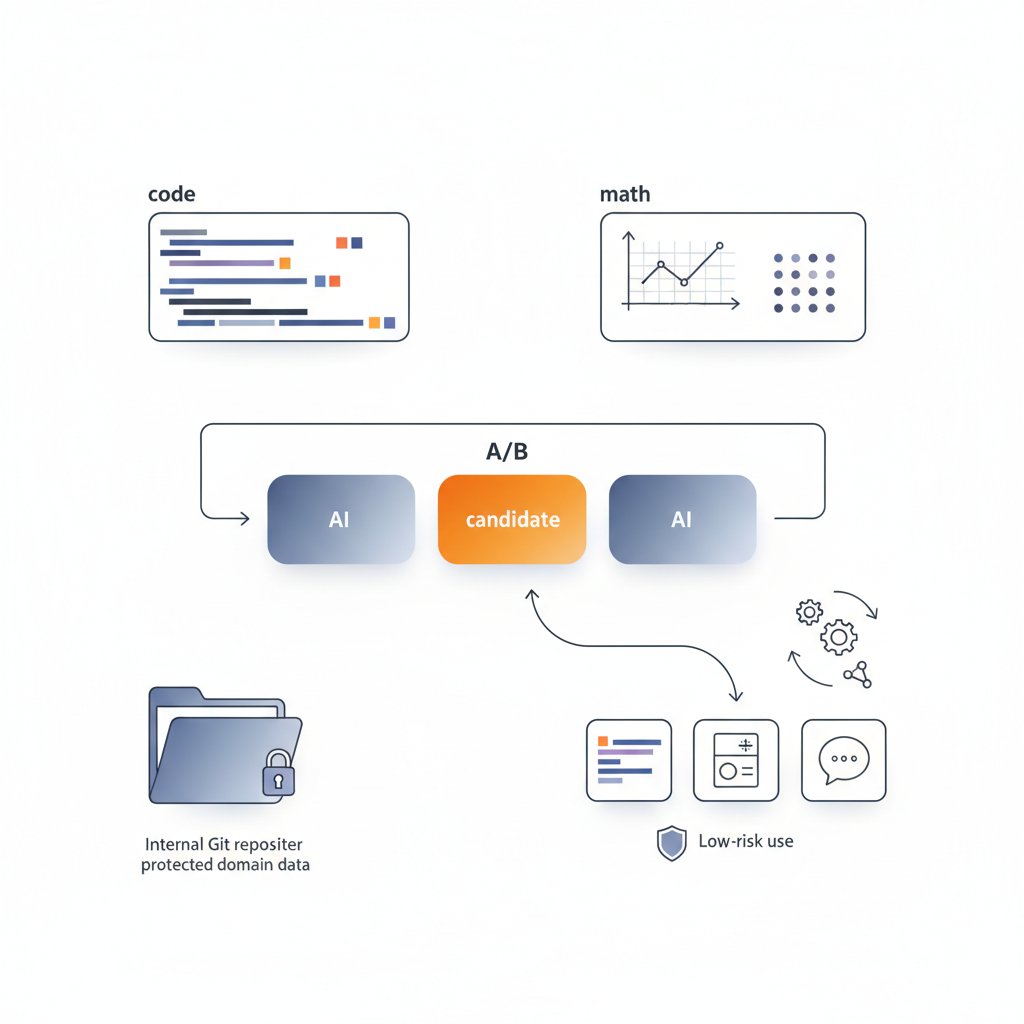
「で、プロダクションで使うの?」という話ですが、正直に言うと:
いきなり本命一本採用は、まだ様子見
ただし、“第二軸としての採用候補”には強く入れておくべき
というのが今の結論です。
現実的な付き合い方(個人的おすすめ)
- まずはA/Bテスト用の候補として並べる
- 既存の GPT-4 / Claude / Gemini に加えて
-
DeepSeekモデルを「もう一人の候補者」としてテストに入れる
-
自社タスクでの差分をちゃんと測る
- 数学・コード・長文仕様整理など
-
「公開ベンチじゃなく、うちのGitリポジトリとドメイン知識」で比較する
-
良さそうなら、“局所採用”から始める
- 例えば:
- コード生成系ツールだけ DeepSeek に寄せる
- 数学系アシスタントだけ DeepSeek にする
-
いきなり全社チャットボットを切り替えるのではなく、
リスクの低い領域から導入する -
パイプライン思想は、自前LLMのチューニングにもパクる
- 全部真似する必要はなく、
- 「難易度カーブを意識したカリキュラム」
- 「推論過程を明示的に学習させる一部タスク」
- だけでも、自前モデルやLoRAチューニングに取り入れる価値はあります。
最後に:これは「GPU資本ゲームの終わりの始まり」かもしれない
DeepSeekがやっていることを一言でまとめると、
「金とGPUの暴力がなくても、
設計とカリキュラムでちゃんと戦える」
というメッセージを、思想ごと公開してきた、ということだと思います。
もちろん、
- ベンチマーク番長疑惑
- ロックインの芽
- 運用の複雑化
といった懸念も山ほどあります。
それでも、
- ただ「新しい巨大モデル出ました」ではなく
- 「こうやって育てました」という“育て方”を共有した
という意味で、今回のDeepSeekの動きは、
LLM界のパラダイムをじわっと変える一手になる可能性があります。
プロダクションでフル採用するには、まだ検証が足りない。
でも、「どうせまたスコアだけのモデルでしょ」とスルーするには、あまりにももったいない。
個人的には、
- 次にLLMを選定するときは
- モデルの性能だけでなく
- 「どういう訓練思想で作られているか」も評価軸に入れるべき
だと強く感じています。
DeepSeekの今回の公開は、そのきっかけとしてはかなり良い材料です。
あとは、我々がそれをちゃんと問いにする側に回れるかどうかですね。


コメント