
「論文書きたいのに、手元にあるのは型落ちGPU 1枚だけ…。
学会発表してるのは、だいたいA100を何十枚も並べたラボばっかり。」
そんなモヤモヤ、感じたことありませんか?
LLMブーム以降、「GPU貧民」はエンジニア・学生の共通語になりました。
でも最近、「GPU貧民がLLM研究で大手に勝つための戦略」という記事を読んで、正直ちょっと考え方が変わりました。
あれって単なる励まし記事じゃなくて、「もうゲームのルールが変わってるよ?」という宣戦布告なんですよね。
- 一言でいうと:「ブラウザは諦めて、React を作れ」という話
- なぜ「GPU貧民戦略」が重要か:もうスケール勝負は終わっている
- 戦場1: 「データと評価」を握ったやつが、本当の意味でゲームを支配する
- 戦場2: ポストトレーニングと特化モデル ― 7Bで殴れ
- 戦場3: システム設計・エージェント・RAG ― 「一発回答」から「仕事をこなす」へ
- 戦場4: 開発者ツール・インフラ ― 「GPU貧民のための PyTorch / pytest」を作れ
- なぜこれは「大手の戦い方」と真っ向からぶつかるのか
- ただ、懸念点もあります…🤔
- じゃあ、プロダクションでどうする?正直「部分的に全力で乗る」が現実的
- まとめ:GPU貧民が握るべきものは「モデル」ではなく「ルール」と「現場」
一言でいうと:「ブラウザは諦めて、React を作れ」という話

この戦略を一言で説明すると、
「GPT-5 を作る側には回れない。
でも、GPT-5 をどう使うかを決める側にはなれる。」
という話です。
アナロジーで言うと、
LLM界の「React / jQuery / PyTorchを作る側になれ」という提案です。
- ブラウザエンジン(Chrome, Safari, Firefox) = GPT-5級の基盤モデル
- その上のフレームワーク(React, Vue, Angular) = エージェント、RAG、評価基盤、ツール群
20年前、個人開発者が「自作ブラウザ作ってIEに勝つ!」なんて言い出したら、ちょっとヤバい人扱いでしたよね。
でも jQuery を作った人は、世界中のWebを実質的に支配したわけです。
LLMも、もう同じフェーズに入りつつある。
正直、「まだ自前で巨大基盤モデルをプリトレしようとしてる小さな研究室・スタートアップ」は、IE時代に自作ブラウザ作ってた人たちに見えます…。
なぜ「GPU貧民戦略」が重要か:もうスケール勝負は終わっている
正直に言うと、個人や小さなチームが「スケール勝負」で勝てる余地は、ほぼゼロです。
- A100/ H100クラスを何百枚も並べる
- 数十~数百Bパラメータを、何兆トークンでプリトレ
- その上でRLHFを大規模に回す
これ、資本ゲームなんですよね。
学生の財布とクレカ上限で殴り合う領域じゃない。
にもかかわらず、いまだに
- 「オレたちも 13B をゼロからプリトレ!」
- 「LLaMA 相当の日本語モデルを自前で!」
みたいなチャレンジを見かけます。
ぶっちゃけ言うと、「頑張ってるのは分かるけど、戦略としては完全に負け筋」です。
2026年くらいまでを見据えると、
- 強い基盤モデルは API か OSS で「ほぼコモディティ化」する
- GPU単価は多少下がっても、学生にとっては依然として高い
- プリトレは大手しか踏み込めない“別ゲー”になっていく
と考えるのが現実的です。
じゃあ GPU貧民は何を武器に戦うか?
ここで出てくるのが、この記事が整理していた4つの戦場です。
戦場1: 「データと評価」を握ったやつが、本当の意味でゲームを支配する

正直、ここが一番「大手に刺さるポイント」だと思っています。
基盤モデルの研究は、
- モデルを作る人(GPU勝負)
- モデルを評価する人(データ・ベンチマーク勝負)
の2種類のプレイヤーに分かれています。
で、後者はGPU貧民でもガチで勝てる。
なぜ評価・ベンチマークが強い武器になるか
- 大手ラボは、「あなたの作ったベンチマーク」でSOTAを取りに来る
- 学会や業界で「このタスクはこのベンチで測るよね」が定着すると、
- そのベンチの設計者=ルールメイカーになる
- 論文・プロダクトが増えれば増えるほど、
- 「引用数」と「名前」が勝手に積み上がっていく
MMLU しかり、MT-Bench しかり。
ああいうのを作った人たちは、モデルを1トークンもプリトレしてなくても、
LLM界隈で名前が消えないポジションを確保してます。
GPU貧民でもできること
- ニッチ領域のベンチマーク
- 例: 日本の税務相談、特許実務、製造業の設備トラブルなど
- マルチステップ推論や安全性みたいな「ちゃんと測れてない領域」の評価
- GPT-4 クラスを使ったシミュレーション的評価(合成データ・敵対例生成)
「モデルは大手が作る。でもゲームのルールはこっちが決める」
このポジションを取りに行くのは、GPU1枚でも十分に現実的です。
戦場2: ポストトレーニングと特化モデル ― 7Bで殴れ
次の戦場は、「プリトレではなくポストトレーニングに全振りする」ことです。
- LoRA / QLoRA
- 4bit / 8bit 量子化
- 7B〜13Bクラスの OSS モデル
この辺を組み合わせれば、手元の 8〜24GB VRAM でもかなり色々できます。
ここで勝つためのマインドセット
正直、「ちょっと日本語を足しました」「ちょっと社内データでSFTしました」くらいだと埋もれます。
GPU貧民が狙うべきは、
- 「この領域なら 7B 特化モデルが GPT-4 をコスパでボコる」
- 「推論コストは 1/10、精度はほぼ同等 or 専門領域では上」
というニッチだけど圧倒的に便利なモデルです。
例を挙げると:
- B2B SaaS 特化のサポートボット用モデル
- 特定プログラミング言語/フレームワーク特化のコード補完
- 特定企業のナレッジベースに最適化された回答モデル
こういうのは
- トークン分布がかなり偏っている
- 一般モデルより少し「専門家的に」振る舞ってほしい
といった要求が多いので、7Bクラスでも十分戦えます。
「GPT-4 でよくない?」と言われないためには、
- レイテンシ、コスト、プライバシー
- 運用のしやすさ(オンプレ / VPC内など)
ここでビジネス的な差別化を出せるかが勝負ですね。
戦場3: システム設計・エージェント・RAG ― 「一発回答」から「仕事をこなす」へ
正直、ここが一番「エンジニアとして楽しい」領域でもあります。
基盤モデルが強くなるほど、
単体のモデル性能差より、
システムとしてどう組むかの差のほうが効いてくる
ようになってきています。
典型的な勝ちパターン
- RAG(Retrieval-Augmented Generation)
- 「知識はDBに、推論はLLMに」
- ツール呼び出し
- コード実行、外部API、データベース操作
- マルチエージェント
- プランナー、実行者、レビュアーを分ける設計
ここで重要なのは、
「強い1モデル」より
「賢いオーケストレーション」
です。
GPU貧民にとって美味しいのは、
- 推論はAPI(GPT-4/Claude/Gemini等)に外注
- 自前では
- ベクトルDB
- 小さい補助モデル(分類・リランキング)
- エージェントのロジック
- だけを持つ構成が取りやすいこと。
つまり、「一番高いところ」は大手に任せつつ、
ユースケースに最適化された“現場のフレームワーク”を握りにいくイメージです。
Webで言うと、
- Chrome や Safari の上に
- Next.js や Remix、Rails がある
あのレイヤーを取りに行く、という話です。
戦場4: 開発者ツール・インフラ ― 「GPU貧民のための PyTorch / pytest」を作れ
最後の戦場が、「ツールとインフラ」です。
ここ、意外と軽視されがちなんですが、
正直、一番継続的な価値が積み上がるレイヤーでもあります。
どんなツールにチャンスがあるか
- 「シングルGPU / メモリ8GB前提」で最適化された実験管理ツール
- ローカルでも回せる評価ハーネス
- 安価なクラウドGPUを前提にした MLOps 的ワークフロー
- 低リソースでの RLHF / DPO / ORPO みたいなポストトレーニング環境
今のLLMツール群って、ぶっちゃけ
- 「A100がないと話にならない」
- 「クラスタ前提で設計されている」
ものがまだ多いです。
ここを「GPU貧民フレンドリー」に作り直すだけで、かなり支持を集められます。
歴史的に見ても、
- pytest
- scikit-learn
- Hugging Face Transformers
みたいな「いい感じの抽象化を提供したツール」は、作者の名前を長期にわたって残しています。
LLMでも同じことが起きます。
なぜこれは「大手の戦い方」と真っ向からぶつかるのか
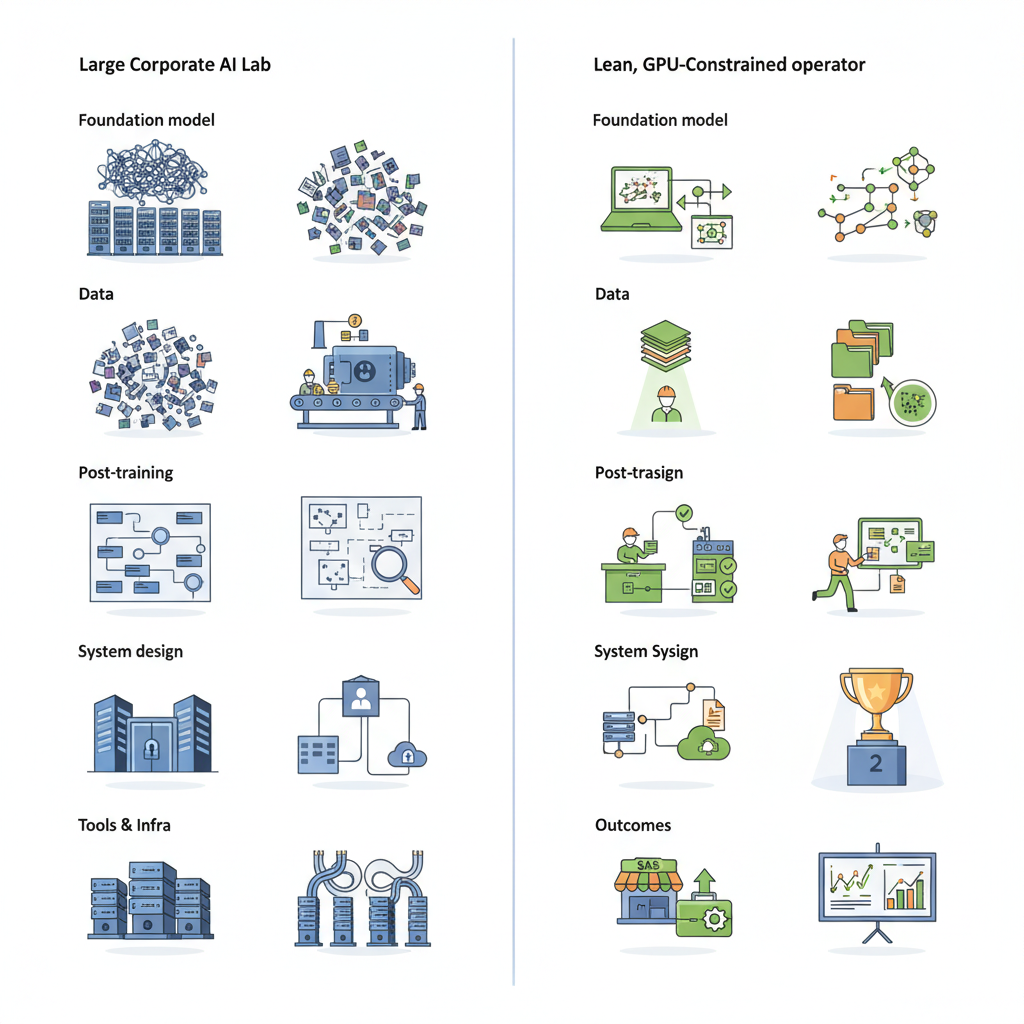
この記事の面白いところは、「大手の戦略」との対比がハッキリしている点です。
ざっくり表にするとこんな感じ:
| 領域 | 大手ラボのゲーム | GPU貧民のゲーム |
|---|---|---|
| 基盤モデル | プリトレのスケール勝負 | 既存モデルをどう賢く使うか |
| データ | 巨大・多様・雑多なコーパス | 狭く深い専門データ、評価用データ |
| ポストトレーニング | 大規模RLHF、人間ラベルに巨額投資 | 小規模SFT, DPO, 合成データ活用 |
| システム設計 | “ベストプラクティス”はまだ模索中 | ユースケース特化のRAG・エージェント設計 |
| ツール・インフラ | 自社クラスター前提の内製ツール | ローカル/安価クラウド前提のOSSツール |
| 成果の見せ方 | 「MMLUでSOTA」「ベンチXでY点」 | 「この業務で◯%効率化」「この領域でSaaS化」 |
要するに、
大手が取りこぼしている「現場の最適化レイヤー」
そこを全部取りに行こう、という話
なんですよね。
ただ、懸念点もあります…🤔
ここまでベタ褒めしてきましたが、正直なところ懸念もいくつかあります。
懸念1: API依存・ベンダーロックイン
この戦略って、
- 強いクローズドモデル(GPT-4 等)を
- データ生成
- 評価
- プロトタイピング
にガンガン使う前提になっています。
つまり、
- 料金改定
- 利用規約変更
- モデル仕様のサイレント変更
の影響をモロに受けるポジションになる、ということです。
「合成データを GPT-4 で10億トークン生成しました!」とか、学生がやったら普通に破産しますし、
プロダクトでもコスト構造がAPIベンダーに握られるのは、それなりに怖い。
このリスクを減らすには、
- OSSモデルで代替可能な部分はできるだけ代替
- 評価基盤はベンダー依存を薄く設計
- 「API前提」の部分と「ローカルで閉じる部分」を明確に分ける
といった設計センスが必要になってきます。
懸念2: 「みんな同じことをやりすぎ問題」
正直、ここまで話した戦略って、
- RAG
- エージェント
- ベンチマーク
- 特化モデル
- ローコストツール
どれも「誰でも思いつく」レベルにはバズっています。
つまり、
参入障壁は低いけど、差別化はめちゃくちゃ難しい
という地獄の市場になりがちです。
実際、GitHubには
- 「Yet another RAG framework」
- 「Yet another agent toolkit」
が溢れています。
その中で抜け出すには、
- ちゃんとニッチを切る
- 「この業界で使える」まで落とし込む
- 単なるライブラリじゃなく「ワークフロー」を押さえる
くらいのことをやらないと、ただのスター100個のレポジトリで終わります。
懸念3: 「GPUいらない」わけでは全然ない
もうひとつ現実的な話をすると、
- LoRAでも実験回せば普通にそれなりのGPU時間は食う
- 評価用に大量に推論を回すと、それはそれでお金が飛ぶ
- ハイパラ探索も雑にはできない
ので、
「お金はかからないよ!」という話では決してない
という点は強調しておきたいです。
大規模プリトレほど狂ってはないけど、
- 学生なら
- クラウドクレカ枠をどう切るか
- 共同研究でGPUをシェアしてもらえるか
- スタートアップなら
- APIコストと自前推論の境界線をどう引くか
をかなりシビアに管理する必要があります。
じゃあ、プロダクションでどうする?正直「部分的に全力で乗る」が現実的
ここまで読んで、
- 「よし、明日からプリトレ全部やめてRAGとベンチだけやるぞ!」
とはさすがに言いません。
現実的な結論としては、
プリトレは大手に丸投げして、
ポストトレーニング・システム設計・評価の3点セットに全振りする
というスタンスが一番筋がいいと感じています。
特にプロダクション目線で言うと:
- 新規プロジェクトで
- 自前基盤モデルのプリトレから入る → ほぼ全案件で却下すべき
- OSS or APIベースでPoC → うまくいったら特化モデルやツール開発に投資
- 研究として
- 「うちのモデル、MMLUで+0.7点!」系の論文 → 相当な工夫がない限りうまみ薄
- 「このベンチで××の行動が×%改善し、実業務だと◯時間削減」系の研究 → 実装者としても評価されやすい
という棲み分けが現実的だと思います。
まとめ:GPU貧民が握るべきものは「モデル」ではなく「ルール」と「現場」
最後に、この記事を読んで個人的に刺さったメッセージを整理すると:
- プリトレは諦めろ
→ そこはもう資本ゲーム。学生やインディーズが行く場所じゃない。 - 評価とデータを握れ
→ ルールを決める側に回れる。GPUいらずで長期的な影響力が出せる。 - 7Bを極めろ
→ LoRA / QLoRAで“狭く深い”特化モデルを作るのは、現実的でビジネスにも直結する。 - システムを設計しろ
→ 単一モデルの精度より、「ツールとRAGとエージェントをどう組むか」で差がつく時代。 - GPU貧民向けのツールを作れ
→ そこが次のPyTorch / pytestポジション。現場で一生使われるレイヤー。
正直、「GPU貧民」というワードには少し自虐が入っていますが、
戦略としてはめちゃくちゃ合理的です。
ブラウザ戦争の勝者は、必ずしもブラウザベンダーじゃありませんでした。
React / Vue / jQuery を作った人たちこそ、Webアプリの作り方を決めた側です。
LLMでも同じことが起こります。
GPT-5 を作れなくても、「GPT-5 時代の当たり前の使い方」を定義することはできる。
GPU 1枚しかないなら、
その1枚は「次のReactを作るため」に燃やしたほうがいい。
正直、そういう時代だと思います。


コメント