
「テキスト一行で“いい感じの動画”作ろうとして、毎回ガチャになってませんか?」
- キャラの顔が毎フレーム微妙に変わる
- ロゴが溶ける or 消える
- カメラワークを細かく指定しても、まったく言うことを聞かない
正直、ここ1年くらいの AI 動画生成って、「すごいんだけど、仕事にはまだギリ使えない」領域で止まっていた気がします。
そんな中で出てきたのが、Google DeepMind の Veo 3.1。
今回のアップデートは、単なる「画質が上がりました!」「8秒1080pです!」みたいな話ではなくて、
“動画生成を、ちゃんとした制作フローに組み込めるかもしれない” 方向に一歩踏み出した
という点がポイントだと感じています。
一言で言うと:「動画版 Tailwind CSS」がやってきた

Google の言う Veo 3.1 の目玉は、「ingredients to video(素材から動画へ)」 という考え方です。
- テキスト:物語、スタイル、カメラ指示
- 画像:キャラ、世界観、ロゴ
- 動画:モーション、レイアウト、カメラワーク
- 音声:テンポ、ムード
これらをバラバラなオプションではなく、「全部まとめて制約条件として渡す」前提で設計している。
これ、めちゃくちゃフロントエンドの歴史と似てるんですよね。
- これまでの text-to-video
→ 昔の CSS みたいなもの。「margin: 10pxと書いたけどブラウザごとに挙動が違う」世界。 - Veo 3.1 の ingredient ベース
→ Tailwind みたいな utility-first CSS。レイアウト / 色 / 余白 / 状態を小さい部品に分解して組み合わせることで、結果がある程度予測可能になる世界。
「文章一発で“いい感じ”を祈る」フェーズから、
「テキスト+画像+映像+音を組み合わせて “設計する” フェーズに入った、というのが今回の本質だと思います。
Veo 3.1 の「本当に効いてくる」ポイント
表向きの宣伝は「ネイティブ音声で8秒の高品質動画!🥳」ですが、エンジニア目線で見ると、価値はそこじゃないです。
一番の革命は「一貫性」と「指示の通りやすさ」
Google 自身が強調しているのが:
- キャラ・オブジェクトの時間的な一貫性
- スタイルの固定(絵柄、色調、世界観)
- モーションの物理的な自然さ
正直、これが一番痛かったところなので、ここに全振りしてきたのは正解だと感じます。
- 同じキャラを別カットで使おうとすると顔が変わる
- ロゴを載せると途中で変形する
- 手足がにょろっと伸びる
こういうのが減ってくると、「AI でベースを作って、人間が仕上げる」という現実的なワークフローが組みやすくなるんですよね。
「素材を前提にした設計」ができるようになる
Veo 3.1 は、テキスト単体での生成もできますが、真価を発揮するのは明らかに複数素材を組み合わせたときです。
例えば:
- 画像モデルでブランドキャラを作る
- そのキャラ画像を Veo に渡して、
「このキャラが製品を紹介している 8 秒動画」を生成 - 既存の縦長動画をモーションの参照にして、
「同じカメラワーク・テンポで別バージョンを量産」 - BGM も渡して、全体の“ノリ”を寄せる
ここまでくると、もはや「動画ガチャ」ではありません。
“モーション・キャラ・世界観・音” を分離して設計できるので、パイプラインとして組む価値が出てくる。
Google vs OpenAI vs スタートアップ:これは誰のゲームになっていく?

Sora vs Veo 3.1:思想の違い
OpenAI の Sora は、どちらかというと
「世界を物理シミュレーション的に再現して、長尺リアル動画を作る」
方向に舵を切っています。
一方で Veo 3.1 は、
「クリエイターと開発者が、既存の素材を活かしながら “ディレクション” できるツール」
としての色が濃い。
- Sora:“世界そのもの” を生成するデモ
- Veo:“既にある世界観や素材を組み合わせる” ツール
ぶっちゃけ、長編映画やリアル系 CG を一発で変えるのは Sora 側だと思います。
でも、日々量産されるショート動画・広告・チュートリアル・プロモの世界では、Veo の「指示しやすさ」と「素材再利用性」の方が刺さる場面が多そうです。
一番危ないのは誰か?
正直、一番キツいのは 単体の AI 動画スタートアップ だと思います。
- Runway
- Pika
- Luma 系
- Avatar 系のサービス(Synthesia / HeyGen など)
これらが持っていた優位性って、
- 画像/動画/音を組み合わせる UI やワークフロー
- そこそこの一貫性と編集機能
- クリエイター向けの UX
だったはずですが、それを Google が「モデル側の標準機能」として飲み込んでくる 流れです。
さらにやばいのは、Google が持っている配布先:
- YouTube Studio(ショート、配信、広告)
- Google Ads(動画広告の自動生成・A/B テスト)
- Workspace(Slides → 動画、Docs → ストーリーボード → 動画)
「ツール単体」vs「ツール+配信プラットフォーム」の戦いになるので、
小規模ツールだけで戦うのはだんだん不利になっていくと思います。
でも…懸念もかなりある
ここからは、あえて冷や水をかけます。
正直、Veo 3.1 を見ていて「これはキツいな」と感じるポイントも多いです。
コストとレイテンシ:動画は結局 “重い”
動画生成は、いかにモデルが賢くなっても、物理的に重いです。
- 複数素材(テキスト+画像+動画+音声)を全部エンコード
- 1080p で 8 秒生成
- 一貫性を保ちながらデコード
これを API 経由で回すと考えると、
- 1 リクエストあたりのコストは、画像とテキストの比じゃない
- レイテンシも長い(試行錯誤のスピードが落ちる)
プランも、
- Veo 3.1 Fast → Google AI Pro プラン
- Veo 3.1 Full → Google AI Ultra プラン
と、それなりに覚悟が要るラインナップ。
「とりあえず side project で遊ぶか〜」というノリで動画を量産できる価格帯では、おそらくないです。
「制御できる」は「ミスしやすくなる」でもある
マルチ素材で制御できるようになると、同時に
「制御をミスる余地」も爆増します。
- テキストでは「ゆっくりした感動的な雰囲気」と書いているのに
- 渡した音源は BPM 速めの EDM
- 参照動画は手持ちカメラでやたら忙しい構図
こうなると、モデルはどの制約を優先するべきか分からない。
結果、「全部そこそこ、それぞれ中途半端」みたいな動画が平然と出てくることになります。
ちゃんと運用するなら、
- 素材のガイドライン
- プロンプトのテンプレート化
- モーション用リファレンスのパターン設計
- 失敗時のリトライ・補正フロー
まで含めたパイプライン設計が必須。
つまり、「生成 AI で楽になるはずが、設計の難易度はむしろ上がる」可能性があります。
がっつりクローズド & Google ロックイン
Veo 3.1 は完全にクローズドなホストモデルです。
- 重い推論を自前で回せない
- オンプレ / ローカル展開の選択肢はなし
- 価格もポリシーも Google 次第
ぶっちゃけ、
「Veo を中核にしたプロダクトを作る」 = 「Google の事業戦略に人生を預ける」
ということでもあります。
Google は巨大ですが、プロダクトの方針転換も早い。
Cloud 周りや AI プロダクトの歴史を見ていると、「これ、本当に 3 年後も同じ仕様で存在する?」という不安はどうしても残ります。
- Safety ポリシーが変わって、急に作れないジャンルが増える
- 価格改定でコストモデルが崩壊する
- API の仕様変更でワークフローごと修正が必要になる
特に、「このサービスの売りは Veo の動画です!」みたいな構成にするのはリスク高めだと感じます。
Safety と表現の限界
Google の公式ページでも、
- レッドチーミング
- 厳しめのポリシー
- SynthID 透かしの全フレーム埋め込み
など、安全性にかなり振っているのが分かります。
企業向けにはありがたい反面、クリエイターサイドからすると、
- ややダークな世界観
- 軽いバイオレンス
- 微妙なコスチューム
- 風刺・政治ネタ
こういったものが丸ごと NG or グレーゾーンになりやすい。
コミュニティでも「安全フィルタが過剰で、普通のファンタジーすらブロックされる」という声は既に出ています。
「攻めた表現」や「ギリギリのジョーク」が求められる現場では、Veo 一択にはなりづらいと思います。
それでも「仕事での使い道」は確実に増える

ここまで懸念を並べたうえで、それでもなお、
「Veo 3.1 は、AI 動画を“おもちゃ”から“道具”に変える方向へ進めた」
という点は高く評価しています。
実務でハマりそうなところ
- YouTube ショート / 教育系チャンネル
- 物理・歴史・語学などのミニ解説を 8 秒〜数ショットで構成
- キャラや世界観を固定して、毎日更新する
- 広告・LP 用のバリエーション生成
- 1 本のベース動画 → 各国言語や別キャラ差し替えを自動生成
- 同じモーションでテイスト違いだけ差し替え
- ゲーム・アニメのプリビズ
- アクションシーンのカメラワークやライティングを、AI でざっと検証
- キャラ立ち絵からショートの演技カットを量産して方向性を詰める
こういう「短尺・大量・試行錯誤前提」の用途では、
Veo 3.1 の「一貫性」「制御性」「素材再利用性」はかなり効いてきます。
じゃあ、プロダクションで本気採用する? → 正直、まだ様子見です 🤔
エンジニアとして冷静にまとめると、今の自分のスタンスはこんな感じです。
- PoC・R&D・社内検証
→ 積極的に使ってみる価値あり。- 既存素材をどう組み合わせられるか
- どこまで一貫性が保てるか
- どの程度プロンプトをテンプレート化できるか
- 本番プロダクトの中核機能として採用
→ まだ慎重派。- コスト構造が見えない
- Google の長期運用方針が読みにくい
- Safety・ポリシー変更リスクが高い
個人的には、
- 本番に入れるなら「複数動画モデルを差し替え可能なアーキテクチャ」にしておく
- Veo 固有の機能(音声込み or 特定のガイド制御)に依存しすぎない
- 画像モデル+動画モデルの組み合わせを前提に、将来別のモデルにも差し替えられるように設計する
くらいが現実的な落としどころかな、と思っています。
最後に:Veo 3.1 が変えたもの、変えていないもの
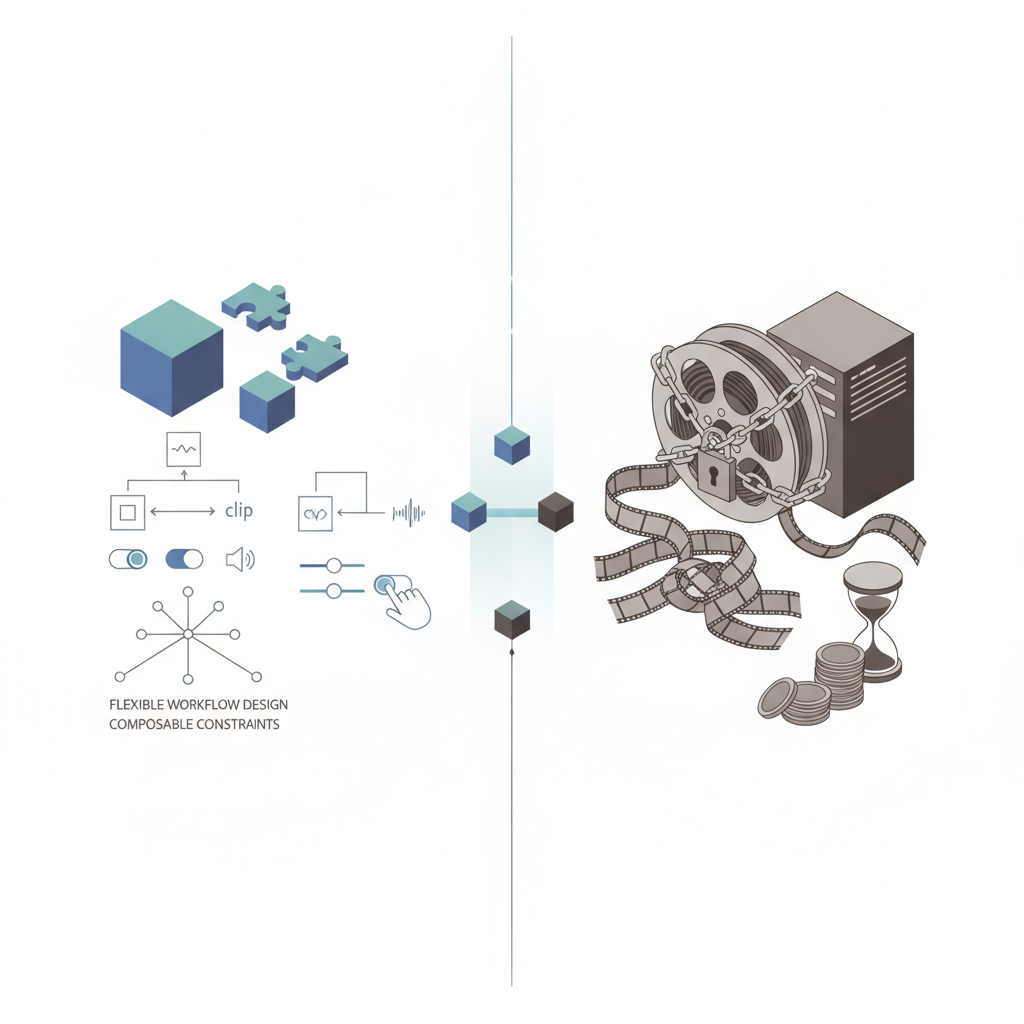
- 変えたもの
- 「動画生成 = お祈りガチャ」から、「素材と制約を設計する仕事」へ
- 「デモ映え」から、「ワークフロー設計」のフェーズへ
-
スタートアップが握っていた「編集・制御 UI」の優位性
-
まだ変えていないもの
- 動画1本あたりのコストとレイテンシの重さ
- ベンダーロックインの構造
- 長尺・高度に構成された映像制作の根本ワークフロー
ぶっちゃけ、Veo 3.1 一発で映像業界が全てひっくり返る、なんてことはないと思います。
でも、
「動画生成モデルに Tailwind 的な “構造と制御” の考え方が入ってきた」
という意味では、かなり大きな一歩です。
開発者としては、「Veo 3.1 を触る」こと自体よりも、
- どう素材を分解し、
- どう制約を組み合わせ、
- どう別モデルにスイッチ可能な設計にするか
を考える方が、長期的には効いてくるはずです。
というわけで、自分はしばらく 「R&D と個人プロジェクトではガンガン試す、プロダクションは慎重に」 というスタンスでいきます。
みなさんは、どのラインから「本番投入してもいい」と判断しますか?


コメント