
エンジニアのみなさん、
「テキスト一発でそれっぽい動画は出るけど、“このキャラをこのシーンにも出して、カメラはここからこう動かして”みたいな、現実的な要件を満たす動画がどうしても作れない…」
そんなモヤモヤを感じたこと、ありませんか?
正直、ここ1年くらいの text-to-video って、「おぉすごい🤩」と最初は盛り上がるけど、いざプロダクトや案件に落とし込もうとすると
- キャラがショットごとに別人になる
- カメラワークを細かく指定できない
- 毎回プロンプト職人芸で戦わされる
…このあたりで現実に引き戻されるんですよね。
そこに出てきたのが、今回の Google DeepMind「Veo 3.1」Ingredients-to-Video アップデートです。
一言で言うと:「動画界のクエリプラン」が来た
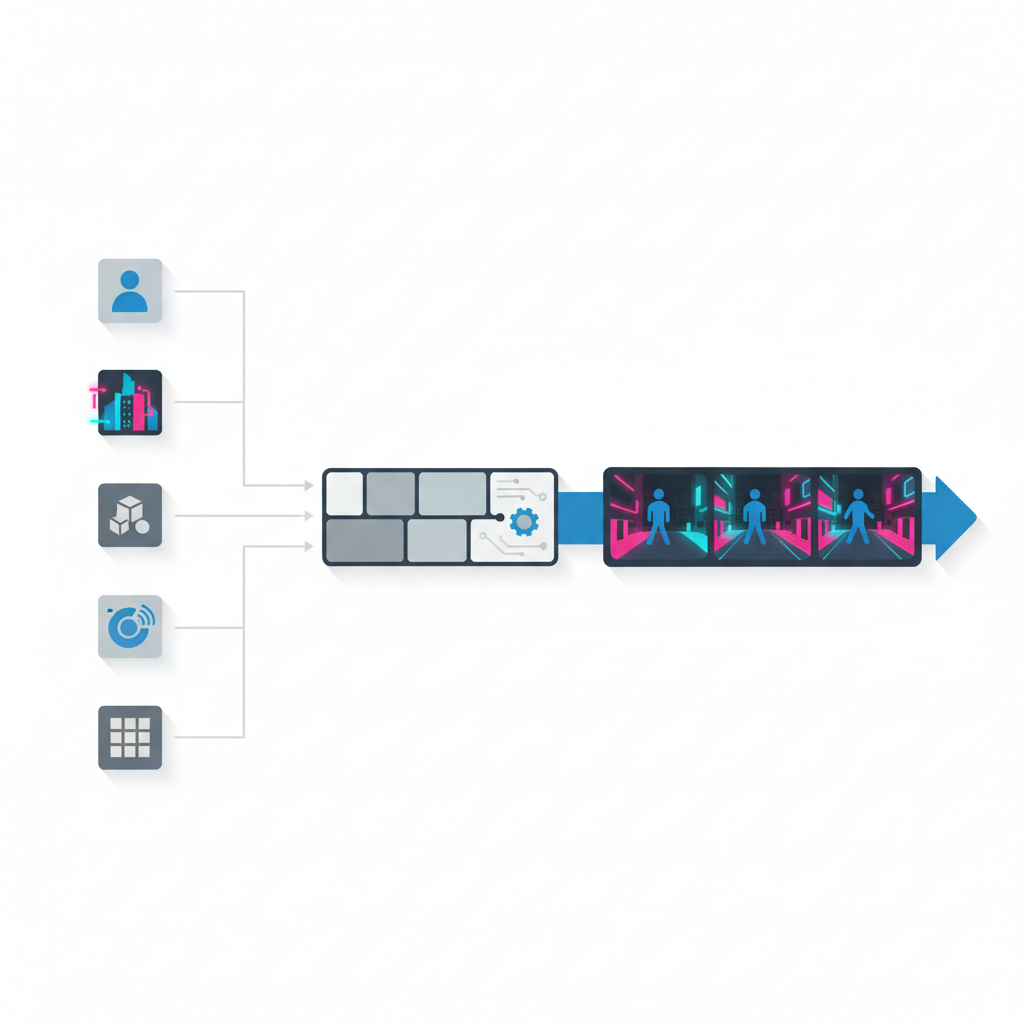
この Veo 3.1 の「ingredients-to-video」って、
一言で言うと 「動画生成版のクエリプラン」 です。
今までの text-to-video は、雑に言えばこうでした:
1本の巨大な SQL を書いて、
「うまく解釈していい感じの動画を返してね」と DB にぶん投げる世界
つまり:
SELECT * FROM video WHERE description = "赤いジャケットのキャラがネオン街を走って…"
みたいな 1クエリ完結・お祈り駆動開発。
今回の Veo 3.1 は、これを一気に stored procedure / query plan 寄りに寄せてきた感じがあります:
- キャラクター
- 環境
- オブジェクト
- カメラワーク
- ショットのつながり
これらを「ingredients(材料)」として構造化して渡すと、
マルチショットの一貫した動画シーケンスを組み立ててくれる、というコンセプト。
ざっくりイメージはこんな感じです:
{
"characters": [
{
"id": "hero",
"appearance_ref": "<画像や動画>",
"text_desc": "赤いジャケットの青年"
}
],
"environment": {
"style_ref": "<背景イメージ>",
"text_desc": "ネオンで照らされた雨の夜の路地"
},
"shots": [
{
"duration": 5,
"focus": "hero",
"action": "走る",
"camera": "ワイドのエスタブリッシング"
},
{
"duration": 4,
"focus": "hero",
"action": "振り返るクローズアップ",
"camera": "ズームイン"
}
]
}
※これはあくまで概念イメージですが、方向性としてはこんなノリ。
正直、これは「モデルの精度がちょっと良くなりました」というレベルではなくて、
「抽象レイヤーが一段上がった」という意味でのアップデートです。
「何がスゴいのか」を冷静に分解すると
キャラとスタイルの“マルチショット一貫性”
Veo 3.1 の売りポイントのひとつが、
複数ショットにまたがるキャラクター・スタイルの一貫性です。
- 顔
- 髪型 / 服装
- 体型 / 動きのクセ
- 画風 / 色調
これらを、ショットごとにバラけさせずに維持してくれる、という方向にかなり振ってきている。
これ、実務で動画触っている人なら分かると思いますが、
「1本の短い動画が自然に見えるか」よりも
「複数シーンをつないだときに破綻しないか」 の方が圧倒的に重要なんですよね。
広告、プロモーション、YouTube コンテンツ、社内説明動画…
どれも 「あるキャラ / ある世界観が、繰り返し登場する」 のが普通なので、
- シーン1:痩せた青年
- シーン2:ちょっと太った中年
- シーン3:なぜかアニメ調の別人
みたいな状態だと、「ネタ動画」以上の使い道はなくなってしまう。
Veo 3.1 はここをちゃんと 「仕様として扱う方向に倒した」 のがポイントで、
単に「精度が上がりました」ではなく、動画制作の前提をモデル側がやっと理解してきた感じがあります。
カメラワークを「パラメータ」として扱い始めた
もうひとつ重要なのが、カメラの制御です。
- パン / ドリー / ズーム
- エスタブリッシング / ミディアム / クローズアップ
- トラッキングショット など
これを「プロンプトで頑張ってニュアンスを伝える」のではなく、
構造化された条件として渡せる方向に進んでいる。
これは、ゲームエンジンが単なるスプライト描画から
シーングラフを持つようになった時期を思い出します。
- 以前:
draw(sprite, x, y)の積み上げ - 以後:
Scene{ Camera, Nodes, Lights, … }を組み立ててレンダリング
動画もようやく 「ただの生成」から「シーン構築」 に寄ってきたな、という印象です。
競合と比べて、どこが「刺さる」のか?

ここで冷静に、他と比較してみます。
- OpenAI Sora
- Runway / Pika / Luma Dream Machine
- 中国・海外勢の Kling など
コミュニティの声やリーク比較を見ていると、
画質・物理挙動・音声/リップシンクの“生のクオリティ”だけで言えば、
「Seedance / Kling の方が上じゃない?」
「Veo 3.1 のリップシンクはまだ微妙」
という意見が目立つのも事実です。
じゃあ、Veo 3.1 は微妙なのか?というと…
正直、「画質だけで選ぶモデル」ではないと思っています。
Veo 3.1 が本当に怖いのは、以下の3点です:
- 「構造化動画生成」に一番早く振り切った
- ingredients-to-video という発想で、「ストーリーボードをそのまま API に落とし込める」方向に行っている
-
これは、UI/ツール側から見て圧倒的に扱いやすい
-
Google エコシステムへの直結
- YouTube / Gemini / Google Cloud / Ads などとの連携ポテンシャル
-
すでに「Gemini アプリから 8秒動画をネイティブ音声付きで生成」みたいな世界観が出てきている
-
コンプライアンス / ガバナンス要件を最初から組み込みに来ている
- SynthID による電子透かし(全フレーム埋め込み)
- レギュレーション対応を意識した設計
なので、「一番キレイなデモ動画を出すモデル」ではなくて、
「企業が長期的にワークフローを乗せやすいスタック」を狙っているように見えます。
正直ここが微妙:コミュニティがモヤっとしているポイント
とはいえ、課題もかなりハッキリしています。
品質勝負だと “トップ” には見えない
コミュニティの反応をざっくりまとめると:
- 「1080p + ネイティブ音声はいいけど、それだけで乗り換えるほどじゃない」
- 「Seedance 1.5 Pro / Kling 2.6 の方が音声とリップシンクで上」
- 「DALL·E もまだ“普通に使えるし”、Veo に行く決定打がない」
つまり、
- 画質:いい
- 音声:まあまあ
- 一貫性:良くなった
- でも「これがベスト」とまでは言いづらい
という微妙な立ち位置。
開発者としては、品質が最強じゃないモデルにロックインするのは怖いので、
「様子見」が増えるのは自然です。
強制ウォーターマーク (SynthID) 問題
もう一つ地味に大きいのが SynthID による電子透かしです。
- 有料ユーザーの生成物にも、全フレームにウォーターマークを埋め込む
- 検出ツール (SynthID Detector) で「AI生成かどうか」を判定可能
これ、自分は「規制・コンプラ的には確かに正しい」とも思う一方で、ぶっちゃけ…
「お金払ってるのに、全部“AI コンテンツです”ってタグを貼られるのか…?」
というモヤモヤは理解できます 🤔
- クリエイター視点:
- 「AI だから価値が低い」と見られがちな文脈で、このタグは足かせになりうる
- 企業視点:
- 一方で、「AI 生成と分かること」がレギュレーション対応上のメリットにもなる
つまり、プロダクトサイドとコンプラサイドの利害が綺麗に分かれるポイントなんですよね。
パワーが上がった分、「使いこなし難易度」も爆上がり
ingredients-to-video のコンセプトそのものは素晴らしいのですが、
実際に プロダクトとして組み込む側のことを考えると、こんな課題が見えてきます:
- ユーザーに「キャラ / シーン / カメラ / ショット」をどう入力させるか?
- それをどんなスキーマで管理するか?(JSON? 自前 DSL?)
- 一部ショットだけ差し替えたいとき、どうやって再生成フローを回すか?
正直、「とりあえずテキストボックス1個置いて試せる」フェーズは完全に終了しています。
これからの video-gen は:
- プロンプトエンジニアリング
→ シーン・スキーマ設計 / オーケストレーション設計
に仕事の重心が移っていくので、
気軽に「とりあえず触ってみよ〜」とはなりにくい。
じゃあ、エンジニアとしてどう向き合うべきか?
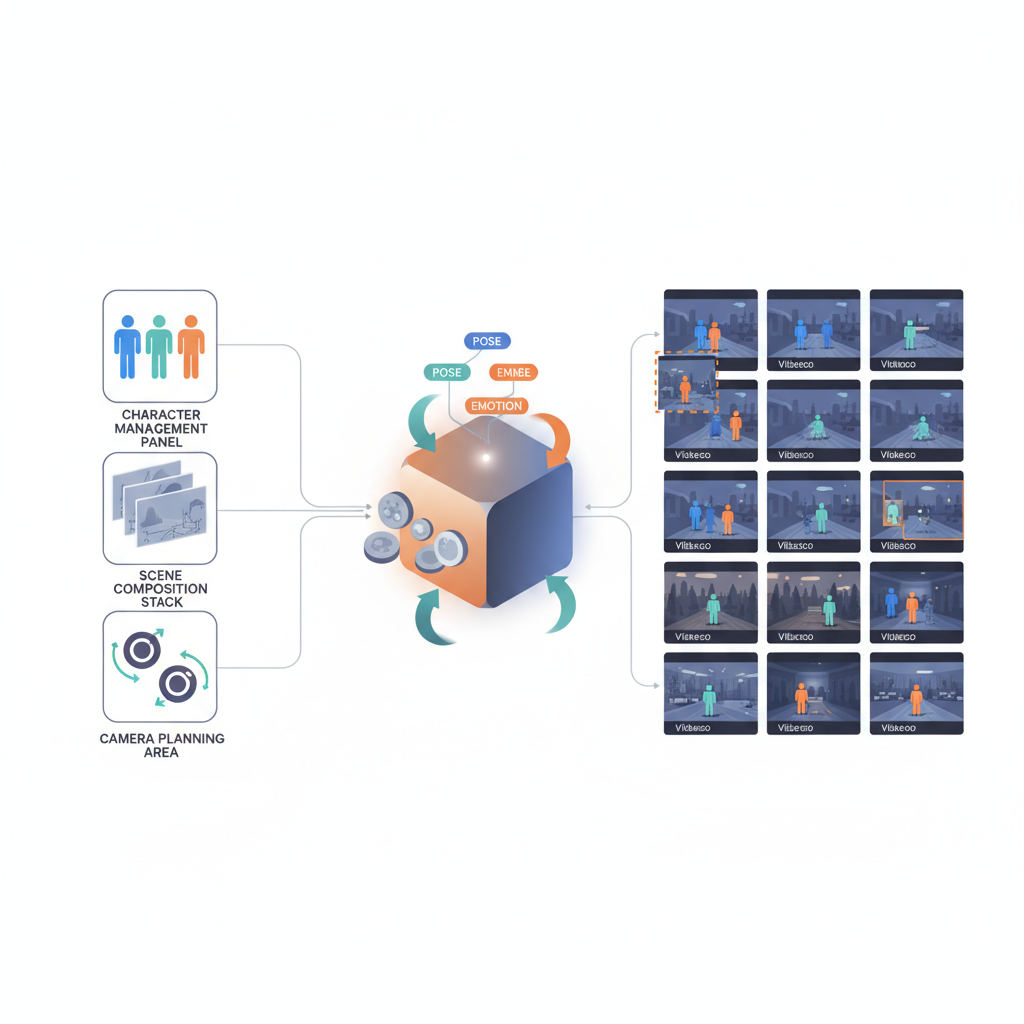
「ただの text-to-video」として見ると、たぶんガッカリする
Veo 3.1 を「他のモデルよりちょっと良い text-to-video API」と見てしまうと、
- 画質勝負:トップクラスと比べると地味
- 音声勝負:Seedance / Kling に軍配という声が多い
- 価格 / レイテンシ:まだ未知数だが、劇的に安いとは思えない
…となって、採用判断としては弱いです。
「動画オーサリングエンジン」として見ると評価が変わる
自分がエンジニアとして一番気になっているのは、ここです。
- 自前プロダクト内に
- キャラクター管理
- シーン構成
- カメラプラン
を持つ - それを Veo 3.1 の ingredients スキーマにマップする
- 差分生成や部分差し替えを、ワークフローとして組む
このレイヤーまで踏み込むつもりがあるなら、
Veo 3.1 はかなり“筋のいいバックエンド”になりうると思っています。
特に:
- ブランドキャラクターを固定して、キャンペーン動画を量産したい
- プロダクト紹介動画を、パラメトリックにバリエーション生成したい
- 教材・マニュアル動画を、テキスト更新に合わせて自動再生成したい
こういう 「量と一貫性」が重要なドメインとは、非常に相性がいい。
ベンダーロックインをどう設計するかが肝
ただし、その瞬間に Veo 固有の世界観にどっぷりハマるリスクも同時に発生します。
- Veo 3.1 を前提にしたシーンスキーマ
- Veo 特有の挙動に合わせた UI / UX
- Veo 前提のパイプライン(解像度、長さ、レイテンシ前提)
これらをガチガチに組み込んでしまうと、
後から「やっぱり Sora / Runway / Seedance に乗り換えよう」となったときに地獄を見る未来が見えます。
個人的なおすすめは:
- 自前で中間スキーマを定義する
Project/Character/Scene/Shot/Cameraなど- それを Veo / 他社モデルのパラメータにマッピングするアダプタ層を用意
- モデルごとの差異は「アダプタ」で吸収し、
上位レイヤーはベンダー非依存の設計にする
これをやっておけば、少なくとも 「完全ロックイン」だけは避けられるはずです。
プロダクション投入するか?ぶっちゃけ、まだ様子見です
最後に、エンジニアとしての率直な結論です。
✅ 今すぐ試した方がいいケース
- 自社プロダクトで「キャラ固定のマルチショット動画」をやりたい
- 既に Google Cloud / Gemini をガッツリ使っていて、
その延長線上で動画生成を組み込みたい - コンプラ・法務から
- 「AI 生成と分かる形での透かし必須」
と言われていて、SynthID がむしろ安心材料になる
こういう環境なら、積極的に PoC する価値は高いと思います。
⚠ まだ様子見した方がいいケース
- とにかく 画質 / 物理挙動 / リップシンクが最優先
- 既に別モデルでワークフローが回っていて、
それを壊してまで乗り換える理由がない - エコシステム的に Google より OpenAI / Microsoft / 他クラウドに寄せたい
このあたりのケースでは、
「Veo 3.1 だからこそできること」がもう少しはっきり見えるまで待つのも全然アリです。
まとめ:Veo 3.1 は「地味だが、方向性としてはかなりデカい一歩」

- これは 「テキスト一発でいい感じ動画」からの卒業宣言 に近い
- 動画を “構造物”として扱うための第一歩 を、Google が大真面目に踏み出したアップデート
- 品質面ではライバルと互角〜やや劣後という評価も多い一方で、
エコシステムとガバナンスを含めた“総合戦略”としてはかなり強い
正直、自分は 「プロダクション全面移行」まではまだ様子見ですが、
- モデルの戦い
→ オーサリングスタック / ワークフローの戦い
にフェーズが変わりつつある、その象徴として
Veo 3.1 はしっかりウォッチしておくべき存在だと思っています。
これから動画系のプロダクトを作る人は、
「プロンプト設計」だけでなく 「シーンスキーマ設計」 をどうするか、
そろそろ本気で考え始めた方がいいフェーズに入ってきましたね 🚀


コメント