
「LLMの推論コスト、もうこれ以上は削れないんじゃないか…」
そう感じたこと、ありませんか?
- ユーザーは「精度落とさずにもっと安く・もっと速く」を当然のように要求する
- 経営は「AIは重要。でもインフラ費がクラウド代を圧迫しすぎ」と渋い顔
- エンジニアは「これ以上は量子化もバッチ最適化もやりきったんだが…」と頭を抱える
そんなタイミングで、NVIDIA が出してきたのが次世代AIプラットフォーム「Rubin」です。
しかもキャッチコピーは「推論コスト 1/10」🚀
この記事は、スペック紹介ではなく、
- Rubin が「何を本当に変えに来ているのか」
- Google TPU やカスタムAIチップ勢と比べてどこがエグいのか
- 企業・開発者としてどう距離感を取るべきか
を、エンジニア目線・運用目線でかなり主観強めに整理してみます。
- 一言で言うと:Rubin は「TPU のおいしいところを、CUDA エコシステム側に持ってきた存在」
- 「本当に新しい」と感じたのは、GPUではなく「AIファクトリー前提の設計」
- なぜ Rubin が “ヤバい” のか:TPU・カスタムチップ勢との比較で見える本質
- 開発者・企業にとって、Rubin が“現実的”に意味すること
- でも、Rubin にはちゃんと “落とし穴” もある
- 小規模チーム・スタートアップにとっての Rubin:正直“すぐ”はそこまで旨味はない
- じゃあ、Rubin をプロダクションで使うか?正直、こう考えています
- 結論:Rubin は “いきなり使うもの” ではなく、“これを前提に設計を変えるもの”
一言で言うと:Rubin は「TPU のおいしいところを、CUDA エコシステム側に持ってきた存在」

Rubin をものすごく乱暴にまとめると、
「TPU v5e みたいな“推論安い専用マシン”を、
AWS/GCP/Azure/オンプレ問わず、CUDA エコシステムでやります」
という宣言に近いです。
- Blackwell 世代比で
- 推論トークンコスト 最大1/10
- MoE 学習に必要な GPU 数 1/4
- 学習も推論も含めたAIスーパコンピュータ一式として設計
- Vera CPU(Armv9.2, 88 Olympusコア)
- Rubin GPU(第3世代 Transformer Engine, NVFP4 で 50 PFLOPS)
- NVLink 6, ConnectX-9, BlueField-4, Spectrum-6 Ethernet …と6チップまとめて協調設計
- 2026年後半から AWS / GCP / Azure / OCI / CoreWeave などが採用予定
正直、これは
「Hadoop で死にものぐるいで MapReduce 書いてたら、
いきなり Snowflake / BigQuery 出てきて “同じSQLでも桁違いに安く・速く” なった」
あの瞬間にかなり近い感じがします。
コード(= モデルや API)は大きく変えず、
インフラ世代を丸ごと変えるだけで、TCO を吹き飛ばすタイプの変化です。
「本当に新しい」と感じたのは、GPUではなく「AIファクトリー前提の設計」
Rubin の記事や公式ブログを読むと、スペック以上に目立つのが
「AI ファクトリー」「AI スーパーファクトリー」
というワードの多さです。
6チップまとめて “1台のAIスーパーコンピュータ” として設計
Rubin は単なる「新GPU」ではありません。
- Vera CPU
- Rubin GPU
- NVLink 6 Switch
- ConnectX-9 SuperNIC
- BlueField-4 DPU
- Spectrum-6 Ethernet Switch
を extreme codesign(極限の共同設計) で束ねて、
「ラック全体を1つの巨大GPUとして見せる」(Vera Rubin NVL72)
ところまで踏み込んでいます。
ぶっちゃけ、ここまで来ると
- 「GPUクラスタを組む」というより
- 「ラック単位の AI アプライアンスを買う」
に近い世界観です。
推論コスト最適化が“主役”に繰り上がった
過去の NVIDIA は、どちらかというと
- 「学習性能ベンチ(TFLOPS)」
- 「モデル規模いくつまで回せるか」
を前面に出していました。
Rubin は明確に 推論コスト をトップメッセージに持ってきています。
- 「Blackwell 比で推論トークンコスト 最大 1/10」
- 「MoE 学習に必要な GPU 数 1/4」
正直、このメッセージの出し方はかなり象徴的で、
「LLMブームは PoC フェーズを終えて、
これからは“どれだけ安く・大量に回せるか”の世界に入る」
という NVIDIA 自身の認識表明だと思っています。
なぜ Rubin が “ヤバい” のか:TPU・カスタムチップ勢との比較で見える本質

Rubin vs Google TPU:差別化ポイントがほぼ潰れた
Google TPU(特に v5e/v5p)の強みは、
- GCP上でのエンドツーエンド最適化
- 推論コストと電力効率の良さ
- PaLM / Gemini など Google社内ワークロードとの親和性
でした。
Rubin が出してきたのは、ほぼそのままの方向性です。
- 推論コスト 1/10
- MoE モデル学習の GPU 数 1/4
- 長大コンテキスト・マルチモーダル・エージェント推論を前提にした設計
- これを AWS / GCP / Azure / OCI / 独立系クラウド / オンプレ で共通に提供
つまり:
TPU の “安い推論” を
「GCP 専用」ではなく「マルチクラウド+オンプレ」でやります
という構図になりつつあります。
エコシステムの厚みが違いすぎる
- Rubin(= NVIDIA 側)
- CUDA, PyTorch, TensorFlow, JAX, ONNX Runtime…
- Triton Inference Server, TensorRT, NeMo, NIM…
- DGX / HGX / 各社サーバー / あらゆるクラウド
- TPU 側
- 基本的に GCP 限定
- XLA / TPU 向け最適化パスが必要
- マルチクラウドやオンプレ対応ほぼなし
正直、TPU を “セカンドソース” として使うモチベーションはあれど、
メインストリームとして TPU を選び続ける理由はかなり揺らいできたと感じます。
Google はよほど攻めた価格・PPA(Performance per $ / per Watt)を出さない限り、
「Rubin + マルチクラウド連合」に飲み込まれるリスクがリアルにあると思っています。
カスタムAIチップ勢にはかなり厳しい現実
- AWS Trainium / Inferentia
- Cerebras
- Groq
- AMD Instinct など
これらの多くは
「NVIDIA より推論TCOが安い専用チップです」
を売りにしていたわけですが、
Rubin で “NVIDIA だけで推論TCO 10x 改善” をやられると、
- 「NVIDIA より安い」は相対的にかなり難しくなる
- エコシステムの薄さを価格だけで補うのは相当しんどい
という状況になります。
しかも NVIDIA は Groq の推論技術まで取り込み始めている。
これは「専用推論チップ勢の出口戦略は NVIDIA に吸収されること」と暗に言っているのに近いです。
開発者・企業にとって、Rubin が“現実的”に意味すること
「同じコードで、インフラ変えるだけ」で性能/コストが跳ねる時代に入る
Rubin の一番ヤバいところは、
Breaking change ほぼ無しで、TCO だけ壊してくる
点です。
- CUDA 互換は維持される見込み
- TensorRT / Triton も Rubin 最適化版になるだけ
- 既存モデルそのまま or 軽微な再最適化で動くはず
つまり、アプリ開発者側から見れば、
- 「裏の GPU が H100 → Blackwell → Rubin に差し替わる」
- 自分はほぼ API(REST / gRPC / SDK)を叩き続けるだけ
という世界がかなり現実的になってきます。
痛みはインフラ側だけに集中し、
アプリケーション側は「勝手に速く・安くなった」ように見える。
これは Snowflake / BigQuery がやったことと非常によく似ています。
ビジネス側:価格戦略を組み替えないと“もったいない”
推論コストが 2〜10倍レベルで下がると、
ビジネス側には以下の選択肢が生まれます。
- 今と同じ価格で モデル品質 or コンテキスト長を爆上げ する
- モデル品質を維持したまま 価格を下げてシェアを取りに行く
- 利幅をそのまま 粗利改善 に振る
正直「全部ちょっとずつ」やるのが現実的ですが、
Rubin 世代を前提にした競合が出てくると、
「Rubin前提の原価構造で値付けするプレイヤー」 vs 「旧世代GPU前提のプレイヤー」
で、かなり露骨な価格差 がバレ始めます。
LLM API / SaaS を提供している側は、
「Rubin 時代の原価を前提にしたプライシング設計」を、今からシミュレーションしておいた方がいいです。
でも、Rubin にはちゃんと “落とし穴” もある
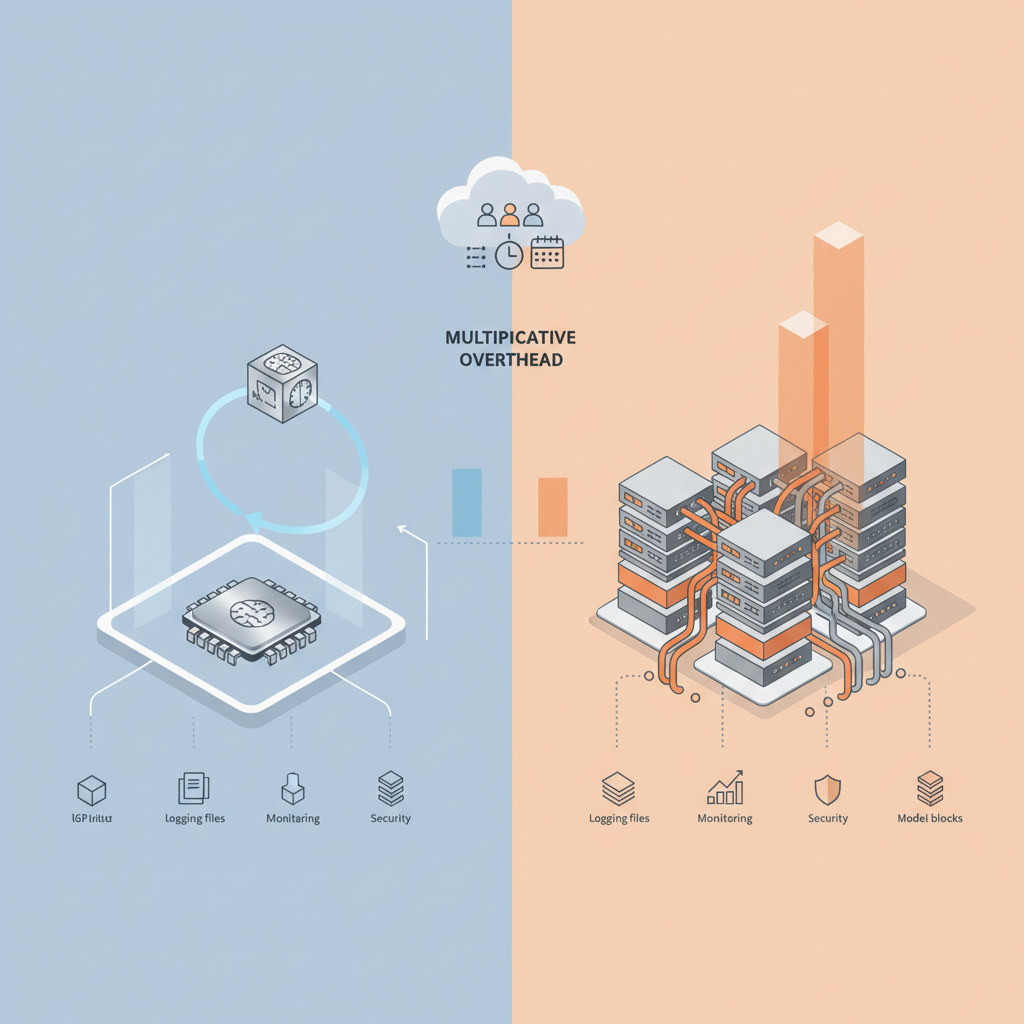
「1/10 コスト」はベンチマーク上の話で、実世界は 2〜5倍に落ちる覚悟を
正直、「1/10」という数字はかなり条件付きだと思っています。
- 特定のLLM構成(大規模 Transformer)
- 特定の精度設定(FP8 / NVFP4 / INT8 など低精度利用前提)
- TensorRT / Triton でガチガチにチューニングしたケース
- NVLink 6 前提の NVL72 クラスタ
リアルなエンタープライズ環境では、
- マイクロサービス構成
- ネットワークホップやら、ログ、監視、セキュリティエージェントも全部載せ
- モデルも一種類じゃない
みたいな“現実的なノイズ”が乗るので、
体感 2〜5倍程度に落ち着く シナリオが多いのではと見ています。
「1/10」を鵜呑みにして CFO に約束すると後悔します…😇
社内説明用には「2〜3倍は現実ライン、最大で10倍もあり得る」くらいのトーンが無難です。
供給制約とクラウド料金:ユーザーに降りてくるまで時間差がある
過去の A100 / H100 を見れば分かりますが、
- 初期は供給不足 + プレミア価格
- 「TCO すごく良いです」と言いつつ、クラウドの時間単価は高止まり
- スポット枠も少ない
という状況がまず数年は続きます。
Rubin もすでにフル生産とはいえ、
2026後半〜2027年くらいまでは
- 「大手クラウド + ハイエンド客向け」
- 「一般開発者が気軽に触れるレンタル枠は少ない/高い」
という形が濃厚です。
つまり、
アーキテクチャとしては“超安い”
でも、クラウド料金として安くなるのはもう少し後
というタイムラグは覚悟した方がいいです。
NVIDIA ロックインはさらに深くなる
Rubin が本当に推論TCOを吹き飛ばしてくるなら、
多くの企業はこう判断します。
- 「コスパ良すぎるし、一旦全部 NVIDIA でいいや」
- 「CUDA / TensorRT / Triton / NeMo / NIM にフルコミット」
結果として、
- GPU ベンダーを変えるコストが爆増
- TPU / AMD / 自社チップへの“逃げ道”が年々細くなる
という構図が確定していきます。
正直、インフラ屋としてはかなり怖いポイントで、
「今は Rubin 一択でいい。でも将来 “第二の選択肢” を持てるような抽象レイヤーは維持しておく」
くらいのバランス感覚が必要だと感じています。
マルチ世代GPU運用の地獄
多くの現場は、こんな感じの構成になっていきます。
- 一部:A100 / RTX 世代(古いバッチ処理・研究用)
- 一部:H100 / L40S(現行本番)
- 一部:Blackwell / GB200(次期本番)
- そして新規:Rubin(長コンテキスト推論・エージェント系)
これ、運用側から見ると普通に地獄で、
- ドライバ / CUDA / cuDNN / TensorRT のバージョン整合性
- コンテナイメージの分岐・メンテ
- モデルの TensorRT プロファイルを世代別に管理 などなど
「TCO 下げたのに、SRE コストが増えました」
みたいな悲しいオチになりかねません。
正直、Rubin を本格採用するなら、
- どのワークロードをどの世代に集約するか
- 旧世代はいつ、どこまで縮退させるか
まで含めた「GPU 世代統廃合計画」をちゃんと描かないと、
運用チームが死にます。
小規模チーム・スタートアップにとっての Rubin:正直“すぐ”はそこまで旨味はない
Rubin の真価は、
- 高QPSのLLM API
- 24/7 常時稼働のエージェント
- 数十万〜数百万トークンの長文コンテキスト推論
みたいな“常に火を焚きっぱなし”のワークロードで輝きます。
一方で、
- PoC レベルのトラフィック
- 社内BOTや限定的なユースケース
- 夜間はほぼ止まってるような利用
であれば、
- 旧世代 GPU(A100 / H100)のスポットインスタンス
- ミドルクラス GPU + 小さめモデル
の方が、トータルで安い場合も普通にあり得ます。
「Rubin だから常に最安」ではなく、
自分たちの QPS / 稼働率 / モデル構成 を冷静に見て、
どの世代GPUが一番“原価に合うか”を選ぶ
という視点は、かなり重要です。
じゃあ、Rubin をプロダクションで使うか?正直、こう考えています

エンジニアとして、今のスタンスを正直に書くと:
短期(〜1年):Blackwell までを前提に設計、Rubin は設計思想にだけ組み込む
- まずは H100 / Blackwell 世代で
- CUDA / TensorRT / Triton に追従しやすい構成
- モデルサービングを「インフラ層と疎結合」な形で組む
- vLLM / KServe / Ray Serve / ONNX Runtime など
- GPU 世代差をある程度吸収してくれる抽象レイヤーを活用
Rubin をガチ導入するのはまだ先なので、
「GPU 世代の差分を後から吸収できる設計」を先に固めたいフェーズです。
中期(1〜3年):Rubin 実機でのベンチを取って、TCO をちゃんと測る
Rubin がクラウドに降りてきたら、真っ先にやりたいのはここです。
- 代表的ワークロードで Hopper/Blackwell vs Rubin を測る
- LLM (チャット)
- RAG(長文 + ベクター検索込み)
- マルチモーダル
- エージェント(マルチターン)
- 1トークンあたり / 1リクエストあたりの
- レイテンシ
- コスト(インフラ+運用)
を TCO ベースで比較する。
そこで
- 「2〜3倍程度なら柔らかく移行」
- 「5倍以上違うなら、新規サービスは Rubin 前提に振り切る」
くらいの判断をするだろうな、と思っています。
長期(3年以上):NVIDIA 一極依存をどこまで許容するか、経営レベルの判断になる
Rubin 以降も、NVIDIA は
- Blackwell → Blackwell Ultra → Rubin → 次世代…
と ほぼ年次サイクル でインフラごとアップデートしてくる前提を明示しました。
これはつまり、
「インフラの世代交代を前提にした AI アーキテクチャを組め」
というメッセージでもあります。
個人的には、
- 本命:NVIDIA(Rubin系列)
- 対抗:TPU / AMD / 一部自社チップ
- ただし、アプリケーションはどのGPUでも動く抽象レイヤーで作る
という形で、
「NVIDIA に乗るけど、いつでも“浮気”できるようにはしておく」
くらいが、技術的にもビジネス的にも一番健全だと思っています。
結論:Rubin は “いきなり使うもの” ではなく、“これを前提に設計を変えるもの”
Rubin の発表をどう捉えるかを、一言でまとめると:
プロダクションですぐ使うか?
正直まだ様子見。ただし、設計と投資計画にはもう織り込むべき。
だと考えています。
- すぐに触れる人:超大規模クラウド / LLM ベンダー / 一部大企業のAI部門
- 1〜2年後に触れる人:一般的なエンタープライズ / MLプラットフォームチーム
- そのさらに後:中小・スタートアップ・個人開発者
でも、世代が降りてくるのを待つだけの立場だとしても、
- 「推論コストが 5〜10倍下がる前提」で、
- どんな新しい UX / サービスが可能になるか
- 価格戦略をどう組み替えるか
- 「GPU 世代差を吸収できるアーキテクチャ」に今から寄せておくか
を考えておくかどうかで、
2〜3年後の機動力にかなり差が出ると思っています。
Rubin は“魔法の黒い箱”ではなく、
「AI インフラが CPU のような年次更新サイクルに乗る」
その未来を、かなりリアルにしてしまった存在
という意味で、エンジニアも経営も、
無視はできない“前提条件”になったと感じています。


コメント