
「診療メモの要約」や「インフォームドコンセントの資料作成」、いつまでも人力で回し続けるの、そろそろ限界じゃないですか?
EHRのフリーテキストを正規表現と辞書でこね回して、「また例外パターン増えた…」と頭を抱えたこと、1度や2度じゃないはずです。
そんな中で、OpenAI・Anthropic・Google がほぼ同時にヘルスケア市場へ本格参入してきました。
「なんかすごそう」以上に、エンジニア視点では設計レベルで時代が変わるかもしれないイベントです。
一言で言うと、これは「ヘルスケアIT界の Kubernetes 登場」にかなり近い動きだと感じています。
一言でいうと:ヘルスケアITの「基盤」が差し替わる前夜

3社とも、「医療特化LLMそのもの」よりも、
- 医療ドキュメント解析
- 臨床ワークフロー支援
- 会話・音声インターフェース
- PHI/PII 対応を含むガバナンスレイヤー
を**パッケージとして売りにし始めています。
これ、Kubernetes が「コンテナを動かすツール」ではなく、
結果としてインフラ設計の標準そのものを塗り替えたのと構図がよく似ています。
- 以前:オンプレVM+スクリプトでゴリ押し
- 以後:K8s 前提でマイクロサービス設計
と同じで、
- 以前:ルールベースNLP+ワークフローエンジン
- 以後:LLM前提の医療ワークフロー
という変化が、かなり高い確率で来ます。
ざっくりニュース整理:これは「AI版・医療クラウド元年」
正直、単なる「3社が医療にも対応しました」ニュースに見えるかもしれませんが、中身はかなり違います。
OpenAI:汎用LLM+パートナー主導の医療ワークフロー
- GPT-4 クラス+カスタムGPT/ファインチューニング
- 音声(Whisper系)+TTSで問診・対話 UI
- 医療記録要約・患者説明・問診サマリ生成が主戦場
- 医療システム(EHR/EMR)との実際の統合はパートナー任せ
つまり OpenAI 自体は「超強力なエンジン」を出していて、
医療ドメイン固有の泥臭い部分(EHR連携、FHIR変換、院内権限制御)はSIer/スタートアップに丸投げという構図です。
Anthropic(Claude):安全性と長文コンテキストの“お行儀の良いエージェント”
- 長文コンテキスト+ガイドライン・論文を一括で読ませられる
- 「医師向け要約」「患者向けやさしい説明」を分けて出すなど、エージェント的利用を前提
- 憲法AI思想で安全性と制御性を全面に
ぶっちゃけ、技術インフラとしての深さは OpenAI / Google には及ばないですが、
「攻めた出力より、安全な出力が欲しい」ヘルスケア領域ではセカンドソースというより“安全側の第一候補”になり得ます。
Google:医療データ基盤+LLMのフルスタック
- Med-PaLM など医療特化研究の蓄積
- FHIR Store / Cloud Healthcare API / 画像ワークフローとネイティブ統合
- 「クラウド上の医療データ基盤」+「LLM」を一体パッケージにしてくる
これは、コミュニティの一部が指摘していた
「このレースで Google が OpenAI に勝つのは、主に垂直統合のおかげだ」
という見立てそのものです。
モデル精度だけで勝つ気はなく、クラウド・データ・ツールチェーンを丸ごと押さえる戦略に振り切っています。
なぜこれが重要か:医療NLPは“プラグイン”に落ちる

開発者目線でいうと、今回の「3社同時参入」の意味はかなりシンプルです。
ここ10年かけて積み上げた医療NLPの多くが、
「LLM API を呼ぶ薄いレイヤー」に置き換わる可能性が高い。
- 正規表現地獄で作り込んだ病名抽出
- カスタム辞書+形態素で頑張った診療録要約
- 無数の if/else で組んだコーディング支援
こういうものが「GPT/Claude/Med-PaLM に投げて post-process するだけ」で、8割方同等以上の精度が出る世界がもう見えてしまった。
ぶっちゃけ、これはBreaking Change ではないけど Architectural Breaking Changeです。
- コードが一夜にして壊れるわけではない
- ただし、新規開発でレガシーNLPを選ぶ理由がほぼなくなる
クラウド登場時に「オンプレ Hadoop クラスタをまだ新規で組みますか?」と問われたのと同じ構図です🤔
Google vs OpenAI vs Anthropic:誰の肩に乗るべきか
Google:医療機関を“クラウドごと”吸い込む戦略
強み:
- すでに GCP の Healthcare API / FHIR Store を使っている病院なら、
そこへ LLM レイヤーを「足すだけ」で設計が完結する。 - 画像・構造化データ・テキストをクラウド上で統合的に扱えるのは圧倒的に楽。
- 垂直統合ゆえに、コスト構造でも OpenAI より有利になる可能性が高い。
弱み:
- マルチクラウド前提の組織から見ると、“GCPロックイン”感が強い。
- 開発者エコシステム(チュートリアル、コミュニティ、サンプルコード)の厚みは OpenAI に一歩劣る。
ヘルスケアの世界は「データを持ってる側が強い」ので、
既にGCP上に医療データを置いている組織ほど、Googleに引き寄せられやすい構図です。
OpenAI(+Azure):LLMエンジンとしての“事実上の標準”
強み:
- 汎用LLMとしての実績・情報量・コミュニティの厚み。
- Azure OpenAI Service 経由で、Microsoft 365 / EHR 連携(特に北米)がやりやすい。
- 医療以外の用途(コールセンター、事務、教育など)も含めた全社統合AI基盤として採用しやすい。
弱み:
- FHIR / 医療画像 などのドメイン特化インフラは自前で持たず、完全にパートナー任せ。
- コミュニティでも指摘されているように、
キャッシュバーンとビジネスモデルへの懸念がつきまとう。 - 「2026年の AI バブル崩壊の象徴にならないか?」という不安は正直わかる。
エンジニアとしては超使いやすい一方で、
経営層からは「3年後の単価や条件がどうなっているか読みにくい」という声が出るタイプのプラットフォームです。
Anthropic(Claude):“セカンドソース”に見えて実は医療と相性がいい
強み:
- 長文を自然に扱えるコンテキスト長
- 安全性・倫理・制御性を重視する設計思想(憲法AI)
- 日本語含め、自然で読みやすい文章を出しやすい
弱み:
- 医療データ基盤やクラウド統合という文脈では、Google / Microsoft には敵わない。
- 「Claude前提の医療SaaSエコシステム」はまだ発展途上。
ただ、医療では「ときどきすごいが、たまに危ない出力」より「平均しておとなしい出力」のほうが歓迎される場面が多い。
その意味で、“危険なところは Claude に投げる”設計は十分あり得ます。
なぜコミュニティが冷めているのか:ユニバーサルヘルスケアとのギャップ

海外の開発者コミュニティを眺めていると、
「その金で普通にユニバーサルヘルスケア作った方が安くない?」
「OpenAI のキャッシュバーン、これ絶対どこかでツケが回るだろ」
という冷めた声もかなり目立ちます。
正直、自分もここは同感で、次の3つの懸念があります。
- 医療アクセスの本丸は“保険・制度”であって“AI”ではない問題
- LLMで診療記録を要約しても、
保険未加入の人の医療アクセスは一歩も進まない。 -
技術で「効率化」しつつ、
制度の議論を後回しにする口実になっていないか?という懸念は拭えません。 -
バブル崩壊時のリスクを医療現場が被る可能性
- 巨額の投資マネーで「AIヘルスケアSaaS」が乱立 → 数年後に統廃合。
-
最悪の場合、「院内の重要ワークフローの一部が、消えたスタートアップのAPIに依存していた」みたいなことになりかねない。
-
営利企業による“医療インフラ支配”の危うさ
- EHR、画像、決済、AIアシスタントまで、
すべて巨大テックのプラットフォーム上に乗る未来。 - 医療データ主権がどこに行くのか、本気で議論しないと取り返しがつかない。
AIエンジニアとしてはワクワクする一方で、
ヘルスケアという公共性の高い領域にGAFA+AIスタートアップがここまで深く入り込んで良いのか、
冷静に一歩引いて考える必要があります。
The Gotcha:技術より「プロセス」と「コスト」がボトルネック
実は一番キツいのは「法規制プロセス」
モデルの精度がどれだけ上がっても、
- 誰が最終責任を持つのか(常に医師?一部はAI?)
- AI出力をいつ・誰がレビューするか
- そのレビュー履歴をどう監査証跡として残すか
- 誤診リスクが顕在化したときの責任分界
ここをクリアしない限り、「医師の意思決定そのもの」に食い込むのは正直かなり難しいです。
結果として、
- PoC:チャットボット+要約ツール → 3ヶ月でそれっぽいものが動く
- 本番:医療安全委員会+法務+コンプラ+ベンダー調整で平気で1〜2年飛ぶ
という、「技術が許すスピードの1/10」くらいのスローペースになりがちです。
ベンダーロックインと“地味に重い”コスト構造
PoC のときは
- 開発者数名
- 院内の一部部署だけでトライアル
- APIコストも月数万円
で、「意外と安いじゃん」となりがちですが、
本格導入すると話は一気に変わります。
- 全病院スタッフが毎日AIを叩く
- 1件あたりのトークン量も、問診〜検査〜説明資料までフルセット
となると、
- 月間数千万〜数億トークンは普通に飛ぶ
- モデルの単価改定がそのままランニングコスト直撃
さらに、プロンプトやワークフローの設計が特定ベンダー仕様に最適化されるので、
- 別ベンダーに乗り換えようとしたときに、
- 出力スタイル
- セーフティフィルタ
- API仕様
- これらの差異を吸収する「抽象化レイヤー」がないと、ほぼ作り直しに近い状態になります。
ぶっちゃけ、最初からマルチベンダー想定のラッパーを書いておかないと詰むやつです。
データガバナンス設計の“運用コスト地獄”
技術的にはできても、組織としてやりきれるか?という問題がかなり大きいです。
- PHI/PII マスキングの自動パイプライン
- ロールベースアクセス制御(医師/看護師/事務/外部委託…)
- 監査ログ(誰がどの患者データをどのモデルに投げたか)の保持・検索性
- 患者同意(コンセントマネジメント)との紐付け
これらをちゃんと設計し、監査に耐える形で運用し続ける必要があります。
結果として、
PoCは大成功 → ガバナンス設計で1年停滞 → 現場のモメンタムが消える
みたいなパターンは、かなりの確率で出てきそうです。
じゃあエンジニアとしてどう動くべきか?
正直、「プロダクションでフル依存するか?」という問いに対しては、まだ様子見というのが本音です。
ただし、「様子見=何もしない」だと完全に出遅れます。
自分が医療系プロダクトの技術責任者なら、今すぐやるのはこの3つです。
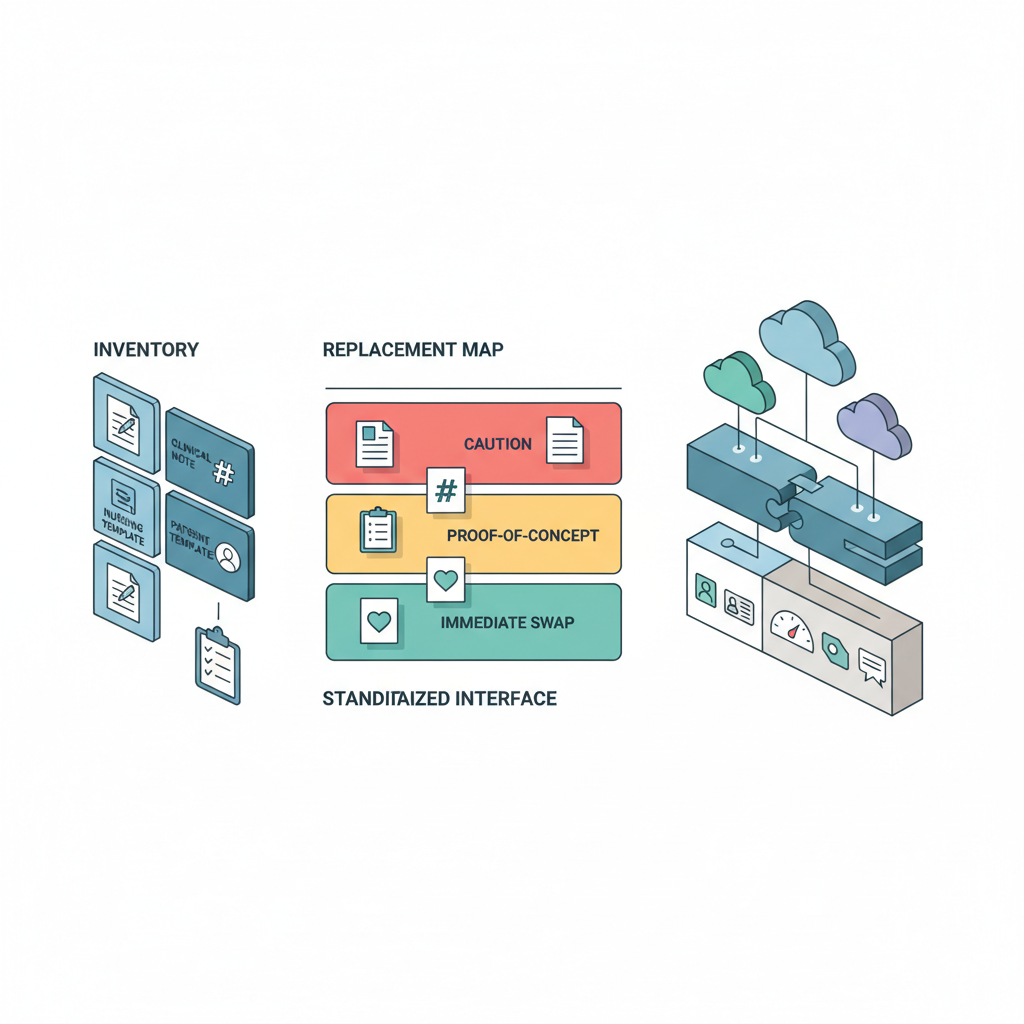
既存ワークフローの棚卸しと “LLM置き換えマップ” 作成
- 現在のテキスト処理/NLPフローを洗い出す
- 診療記録要約
- コーディング支援(ICD等)
- 看護記録のテンプレ展開
- 患者向け説明文生成
- 「LLM API 呼び出し+薄い後処理」で代替できる部分を色分け
ここで「赤(今LLM使うとヤバい)」「黄(PoC候補)」「緑(即置き換え候補)」くらいに分けておくと、
社内での合意形成がしやすくなります。
最初から「LLM抽象化レイヤー」を設計に入れる
Provider = OpenAI | Anthropic | Googleみたいなプラガブルなアダプタ層を作る- 共通インターフェース:
- 入力:構造化ペイロード(患者情報ID抜き、テンプレ付きなど)
- 出力:共通フォーマット(severity, codes, free_text, explanation 等)
- プロンプト/出力後処理はアダプタ側に寄せて、アプリ本体から切り離す
これをやっておけば、
- 途中で「やっぱり Google に寄せよう」「一部機能は Claude に切り替えよう」という判断をしても、
- 上位レイヤーのコード変更を最小限に抑えられます。
自組織の「データ境界」と「責任範囲」を言語化する
3社比較を始める前に、実は先にやるべきなのはここだと思っています。
- どこまでをオンプレ/自クラウドに閉じるか
- どの粒度までを外部LLMに渡してよいか(匿名化レベル)
- AIが関与した情報に対して、誰が最終責任を負うか
- 医師・看護師・事務それぞれに、どういう使用ガイドラインを課すか
ここが曖昧なまま PoC を始めると、
「PoCは成功したけど、法務とコンプラがストップをかけて本番に進まない」パターンまっしぐらです。
結論:これは「新しいAPI」ではなく「世代交代の号砲」
OpenAI・Anthropic・Google のヘルスケア同時参入は、
単なる API リリースではなく、医療ITアーキテクチャ全体の世代交代の号砲に近いと感じています。
- 技術的には:
既存の医療NLP実装の多くが「LLMを叩くプラグイン」にリファクタされるフェーズに入る。 - ビジネス的には:
ヘルスケアが「AIバブル」の本丸となり、ユニバーサルヘルスケアとの価値観衝突が加速する。 - アーキテクチャ的には:
Kubernetes がインフラの常識を変えたように、
LLM前提設計が医療ワークフローの常識を変えうる。
プロダクションでいきなりフル依存するのは、正直まだ怖いです。
ただし、
- LLM抽象化レイヤーを用意しつつ
- 「置き換え余地」を冷静に棚卸しし
- データ境界と責任範囲を先に決める
この3つを今から始めておかないと、数年後には
「あのときから準備しておけば、今こんなに焦らずに済んだのに…」
と、Kubernetes 初期をスルーしたときと同じ後悔をもう一度することになると思います。


コメント