
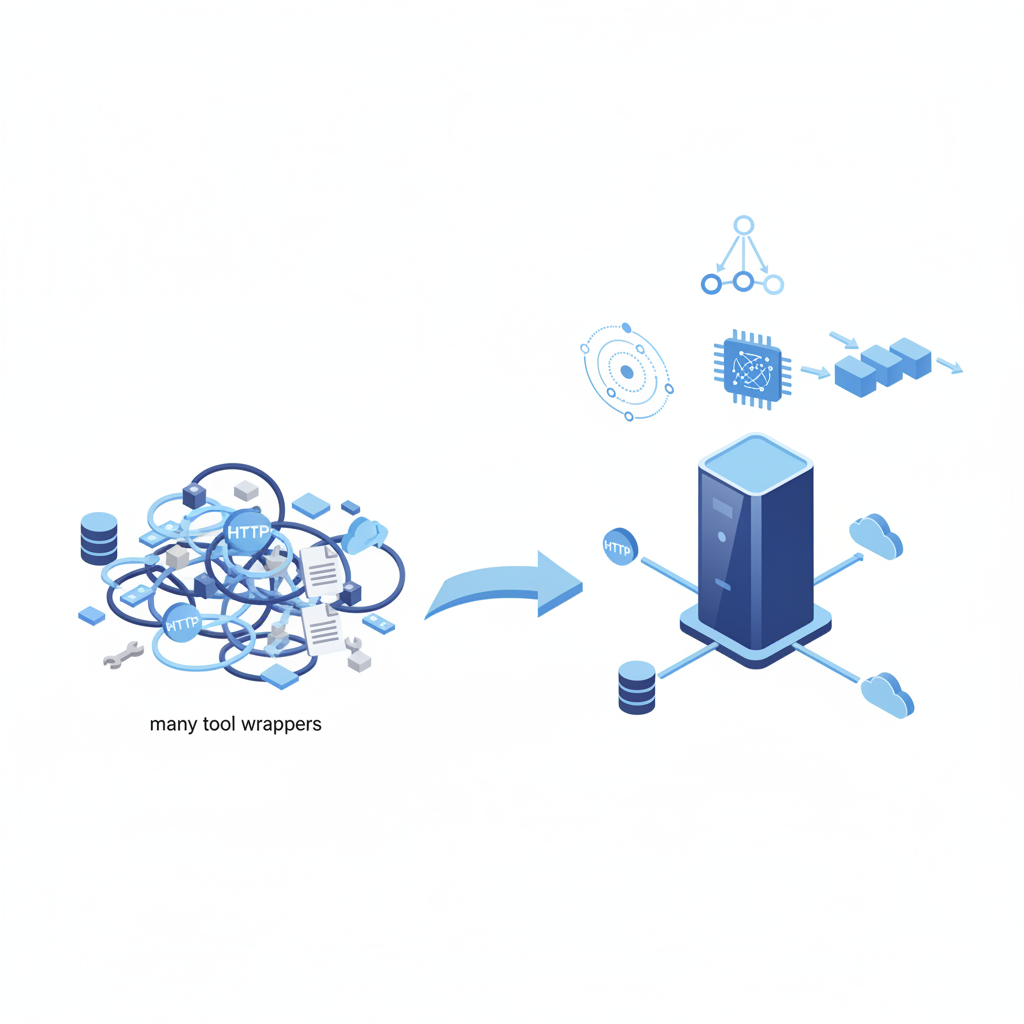
「またベンダー固有のツール定義書いてるの、自分だけ?」
LLM連携コードを書いていて、こんなツラみありませんか?
- OpenAI用に function calling 書いたのに、Anthropic用にまた書き直し
- SDKごとにツールの宣言フォーマットが微妙に違う
- ツール定義をプロンプトに詰め込みすぎて「コンテキストが全部スキーマ」問題になる
- ベンダーを差し替えるたびに、アプリじゃなく“接着コード”ばかりメンテしている
正直、ここ1年くらいの「エージェント開発」は、このベンダー別の接着コード地獄との戦いだったと思います。
そんな中で出てきたのが、OpenAI・Anthropic・Googleが足並みをそろえ始めた
MCP (Model Context Protocol) と A2A (Agent-to-Agent) です。
一言でいうと、
MCP / A2A = 「エージェント時代の TCP/IP + gRPC をまとめてやろうとしているやつ」
です。
でも今回はニュース解説ではなく、「これ、現場から見てどうなの?」という話をします。
一言でいうと「Docker前夜に戻った感じ」がする

個人的には、今のMCP / A2Aのムーブは、
Docker登場前夜のコンテナ標準化の空気感にかなり近いと感じています。
- Docker 前 → 各社自前のデプロイスクリプト・イメージフォーマット
- Docker 後 → 「とりあえず Docker image で出しておけば、どこでも動く」
と同じように、
- いままで →
- OpenAI function calling
- Anthropic tools API
- Google function calling
それぞれにツール定義&接着コードを書く - これから →
- 「ツールや社内APIは MCP サーバーとして出しておけば、Claude でも GPT でも Gemini でも使える」
という世界に寄せにきている。
そして A2A は、
「エージェント同士が HTTP / SSE / JSON-RPC でしゃべるための共通プロトコル」
で、
「エージェント同士のHTTP / gRPC」 を決めに来ている感じです。
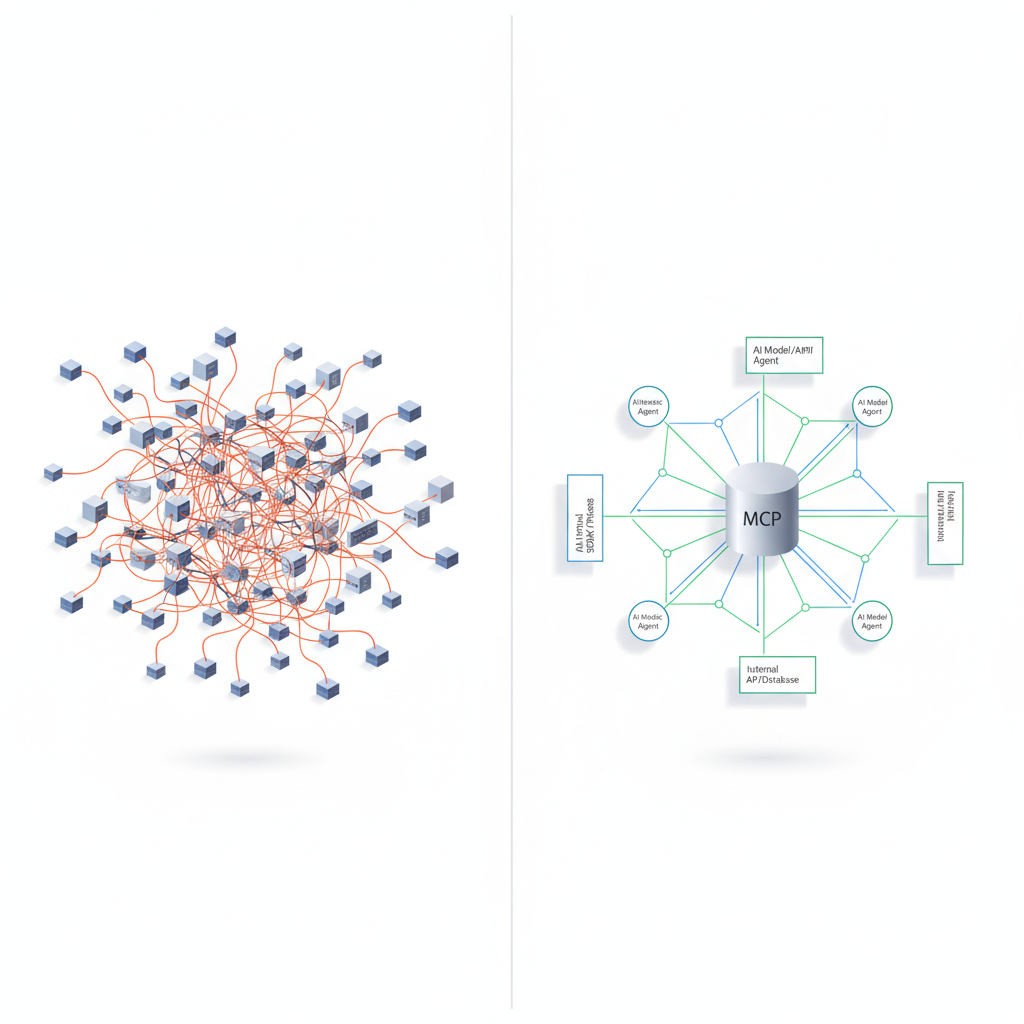
MCP / A2Aの「本当にヤバい」ポイントはここ
MCPは「LLM用の標準RPC+リソースプロトコル」になりうる
MCPの本質はかなりシンプルです:
- LLMから見て
- ツール呼び出し
- DB / API へのアクセス
- ファイル・リソースの取得
を全部「MCPサーバー」という1つの入口に統一する
ここが効いているのは:
- ベンダー中立
同じMCPサーバーを Claude からも GPT からも Gemini からも叩ける - 型付き
toolsの引数・レスポンススキーマが宣言される(事実上のschema-first設計) - トランスポート抽象
stdio / WebSocket / HTTP SSE の上に乗るアプリプロトコル
つまり、
「HTTPサーバーを1個立てておけば、どの言語からも叩けるよ」
のエージェント版が MCP です。
A2Aは「エージェント同士を公式に“外注”させる線路」
A2Aは、
エージェント(≒ LLM + ツール群 + MCPクライアント)が
- 他のエージェントを
- 標準フォーマットのメッセージで呼び出す
ための仕様です。
ポイントは:
- エージェントは 「Agent Card」 というメタデータ(できること・エンドポイントなど)を公開
- クライアント側エージェントはそれを見て
- どういうタスクを投げるべきか
- どの認証方式で呼ぶべきか
を判断できる
つまり、
「ChatGPTエージェントが、A2A越しに“会計エージェント”や“翻訳エージェント”に仕事を投げる」
みたいな構図をプロトコルとして標準化しようとしている。
ぶっちゃけ、Googleがここまでちゃんとプロトコルとして切り出したのは評価しています。
「Tool Searchで85%トークン削減」は地味にゲームチェンジ

正直、MCPの技術仕様よりもインパクトが分かりやすいのが、
Claude Code の MCP Tool Search の話です。
- IDEに大量のMCPツールを入れていると、
- その定義(説明・引数・スキーマ)を全部プロンプトに突っ込む羽目になる
- 結果、
- 「コンテキストの大半がツール定義」という本末転倒な状態に…🤯
これに対して Tool Search は:
- 「今回の会話・目的に関係しそうなツールだけ」
- MCPサーバー側からオンデマンドで探索して展開
というアプローチを取り、
検証記事ではトークン使用量 85%削減という数字が出ている。
ここ、地味だけどかなり本質的です。
エージェントが扱う「ツール数」は今後ほぼ確実に増え続ける
→ 何も考えずに全部コンテキストに入れる設計はスケールしない
MCP + Tool Search は、
- 「ツール定義は外に出す」
- 「必要なときだけ引っ張る」
という情報アーキテクチャ側の解決策を提示している。
これは「LLMの賢さ」ではなく、「周辺設計のうまさ」で勝負している良い例だと思います。
すでに「実在の業務」がMCP化され始めている
絵に描いた餅ではなく、ちゃんと現実側が動き始めているのも重要です。
国交省データプラットフォーム MCP サーバー
- 国交省の地理・交通・建設関連統計などを
- MCPサーバーとして公開し
- 建設会社が ChatGPT / Claude / 社内エージェントから叩けるPoC
ここで効いているポイントは2つ:
- 認証・認可がMCPサーバー側に集約される
→ LLM側は「MCPツール呼ぶだけ」でセキュアに官公庁データへアクセス - ベンダー非依存でPoCが回せる
→ 「社内はClaude派だけど、パートナーはGPT派」みたいな状況でも同じバックエンドを使える
正直、「業界別MCPサーバー」が増え始めたら、
その瞬間からMCPは事実上のインフラになります。
「失敗から学ぶ」MCPサーバー v1.6
v1.6のMCPサーバーでは、
- LLMのゴミ出力・誤用パターンを MCPレイヤーで検知
- そのメタデータを蓄積
- 将来のガードレール/ガイドとして活用
という、「MCPサーバー自体が自己改善基盤になる」実装が出てきている。
これ、やってることは
「API Gateway + Observability + Guardrail」 を
MCPレイヤーに押し込んだようなもの
で、
「LLM寄りのAPM (Application Performance Monitoring)」が
自然と MCPサーバー側に集約されていく流れに見えます。
じゃあLangChain勢 / 既存フレームワークはどうなるのか?
ここが一番気になるところだと思います。
LangChain vs MCP:役割がかぶっているところ・かぶっていないところ
LangChain が得意としてきたのは:
- DB / HTTP / ファイル / SaaS などへのラッパー
- それらを束ねるチェーン / エージェント / ワークフロー
MCP がやろうとしているのは:
- ツールやリソースをサーバーサイドに集約
- その定義・呼び出しプロトコルを標準化
ぶっちゃけると、
「LangChainのAPIラッパーとしての存在意義」は、MCPが広まるほど減っていく
と思っています。
一方で、まだ役割が被っていない領域もある:
- DAGベースのワークフロー構築
- 評価・テレメトリ・トレーシングの統合
- ローカルLLM・特殊モデルとの統合
- MCPサーバーを前提とした“上位オーケストレーション”
つまり、LangChain勢は
「ツールラッパーの山」から
「MCPサーバーを使ったエージェント・パイプラインの設計・運用」へ
ポジションを一段上げられるかが生存ラインになるはずです。
「でも、これまた新しい抽象レイヤー増やしてない?」という懸念
ここまで褒めモードで来ましたが、
正直、懸念もそこそこあります。
懸念1:インフラ構成は確実に複雑になる
従来:
- LLM SDK → 社内API / DB を直叩き
今後:
- LLM(Claude/GPT/Gemini)
→ MCPクライアント
→ MCPサーバー
→ 社内API / DB - さらにマルチエージェント化すると
→ A2Aルーター / リモートエージェントが増える
結果として:
- コンポーネント数は増える
- ネットワークホップも増える
- 監視・ログ・セキュリティも一段面倒になる
特にインタラクティブUXが要求されるプロダクトでは、
「エージェント → MCP → 別エージェント → 別MCP」
みたいな多段ルーティングが本当に許容できるのか、
レイテンシ含めた設計はかなりシビアになります。
懸念2:「オープン標準だけど、実質メガベンダーロックイン」問題
MCP / A2A自体はオープンをうたっているものの、
- 実質的な主導権は
- OpenAI
- Anthropic
- Google
の3社(+A2AにはMicrosoftも参戦気配)
になりつつあります。
ここでよくあるパターンは、
- 最初は中立的な仕様
- 各社の新機能・新モデルに最適化した拡張が増える
- 「オプション扱いの拡張」が事実上の必須機能になっていく
- 気づいたらその拡張に最適化したベンダーから離れにくくなる
というやつです。
つまり、
「形式上はオープン、実質はGAFA的コンソーシアム仕様」
になりかねない。
さらに企業側が独自拡張をMCPに足し始めると、
- 標準MCP
- 社内拡張MCP
の2系統が生まれ、
「またアダプタ地獄じゃん…」という未来も全然ありえます。
懸念3:組織側のスキルギャップ
MCP / A2A は、
- schema-first / contract-first な設計
- プロトコル / バージョニング / 認証設計
が前提になります。
PoCを乱立してきたチームほど、
「とりあえずSDKから直接叩いたほうが早いでしょ」
という誘惑に勝てるかどうかが怪しい。
正直、「最初からMCP前提で組める新規プロジェクト」と
「すでにLangChain + カスタムツールでガチガチに組んでしまった既存プロジェクト」では
導入の心理的ハードルがかなり違うはずです。
とはいえ、「バックエンド=MCPサーバー」という設計はもう無視できない
いろいろ懸念はあるものの、
設計トレンドとしてはもう一つの方向性が見えたと思っています。
バックエンド = MCPサーバー
フロント = 好きなLLM / エージェント
という構図です。
これは開発ライフサイクル的にいうと:
- 以前:
- LLMごとにツール定義を書き
- SDKごとに接着コードを書き
- ベンダー変更のたびに一部書き換え
- これから:
- 社内APIやドメインデータを MCPサーバーに集約
- LLM側は「MCPクライアントとしてしゃべれるか」だけ気にすればよい
になる。
正直、この設計のほうが
- マルチベンダー構成
- 社内・社外エージェントの混在
- 将来のモデル差し替え
に対して圧倒的に強いです。
じゃあプロダクションで今すぐ使うか?という話
ここが一番聞きたいところだと思うので、
かなり正直に書きます。
結論:フルコミットはまだ様子見。ただし「触らない」は悪手
自分だったら、こう判断します👇
新規プロジェクト(まだPoC段階)
- コアドメインのツール / APIは最初からMCPサーバーとして切るのを強く検討
- ただし
- すべてをMCP化するのではなく
- 「どうせ長期で使い回すだろう」な中核APIから始める
- LLM側は:
- Claude Agent / ChatGPT Agents / 自作エージェント
- どれを選んでも動く前提で設計しておく
既存のLangChain / custom tool プロダクト
- 正直、一気にMCPへ全面移行するのはおすすめしません
- やるなら:
- 「頻出ツール」
- 「複数プロダクトから再利用されている社内API」
からMCPサーバー化していく段階移行 - しばらくは
- LangChain → MCPサーバー呼び出し
- LLM直呼びツールとMCPツールのハイブリッド
という構成が現実的だと思います
エディタ連携・開発者体験
- Claude Code + MCP Tool Search は一度触っておく価値が高い
- 「コンテキスト汚染がどれくらい減るか」を
- 自分のIDE + 自分のMCPサーバー
で試してみると、MCP導入のROI感がかなりクリアになるはずです
最後に:この波を「ただの新しいAPI」としてスルーしないほうがいい理由

ぶっちゃけ、MCP / A2Aは
- もう一つのREST
- もう一つのgRPC
ではありません。
「LLMエージェントが外界とどう接続されるか」
というレイヤーそのものの標準化
に踏み込んでいる点が、歴史的に見てもかなり大きい。
もしこのまま主要クラウド・SaaS・業界団体が
- 自社データ / API をMCPサーバーとして出し
- 自社エージェントをA2A対応していく
流れに乗った場合、
我々アプリケーション開発者は
- 「どのLLMを使うか」より
- 「どのMCPサーバー群・どのエージェントネットワークに乗るか」
を設計する立場にシフトしていくはずです。
なので、自分の今の立ち位置としては:
- プロダクションでMCP前提に全振り → まだやらない
- ただし、MCP / A2A前提で考えるクセ → もう今から持っておく
です。
具体的には、次にエージェント設計をするときに、
- 「このツール、本当にSDK直叩きでいいのか?」
- 「MCPサーバー化したときに嬉しい将来像はあるか?」
- 「このエージェント、将来A2Aで外部と連携する可能性は?」
を一度考えてみる。
ここまで頭を切り替えておくと、
2〜3年後「あのときからMCPを前提にしておいてよかった」と
本気で思うフェーズが来る可能性は高い、と感じています。
あなたのプロジェクトだと、
最初にMCPサーバー化するならどのAPI/どのツールになりそうですか?
その選び方から設計が変わってくるはずです。


コメント