
「社内でLLM試したいけど、ログをベンダーに全部持っていかれるのはさすがにイヤ」
そんな議論、ここ1〜2年で何回しましたか?😅
- 法務「この条文だと“技術的には読めちゃう”よね?」
- セキュリティ「E2EEならいいけど、そんなサービスないでしょ」
- 開発「ログ見えないと、こっちもデバッグできないんですが…」
この三すくみ、正直もう飽きた人も多いと思います。
そんなところに、Signal生みの親 Moxie Marlinspike が出してきたのが E2EE対応AIチャット「Confer」 です。
一言でいうと:「AIチャット界のSignal宣言」が来た
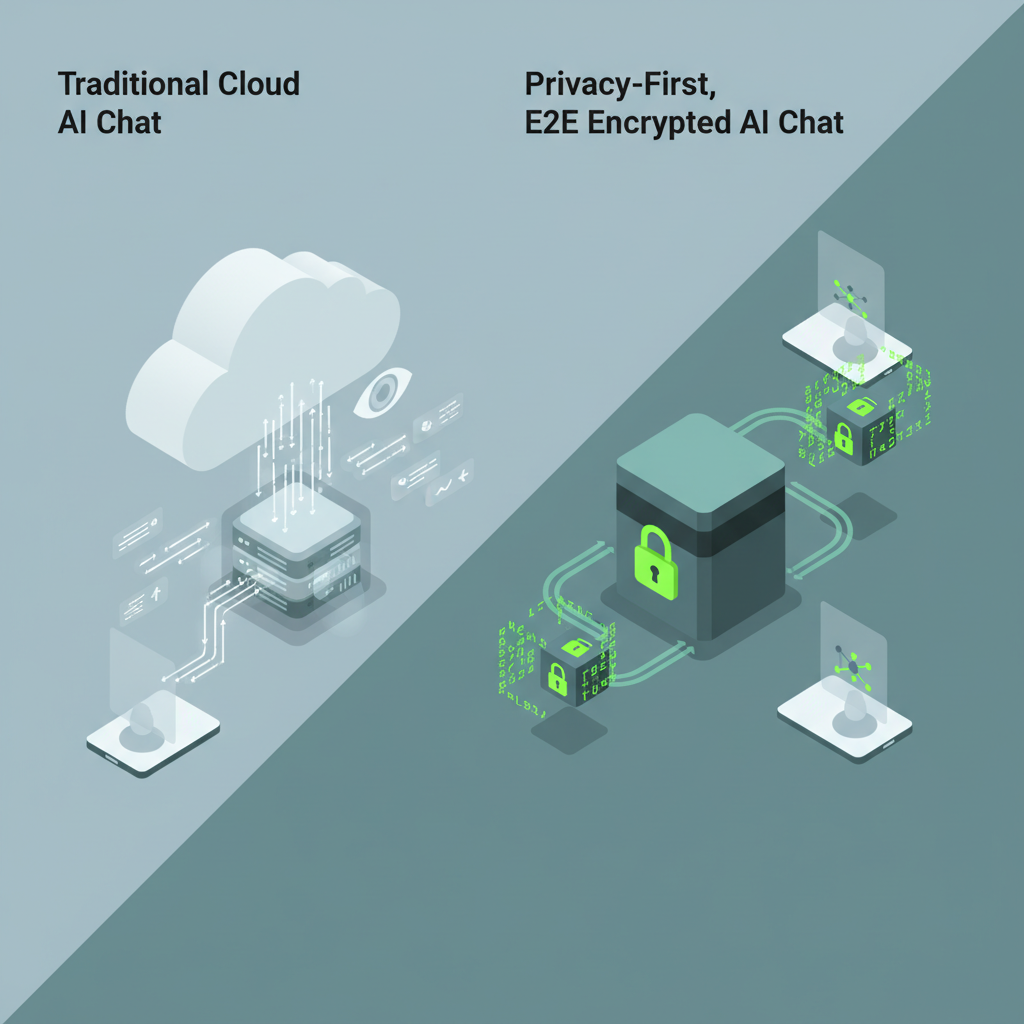
ニュースを一行でまとめるなら、
Confer は、AIチャットにおける Signal / WhatsApp 型E2EE を本気でやろうとしているサービス
です。
- ChatGPT など従来のクラウドAIチャット
→ ベンダーは理論上「全部読める」前提 - Confer
→ 運営ですら会話内容を読めないアーキテクチャを前提にする
この「前提をひっくり返す」感じ、
メッセージングの世界で
「SMSとか普通のチャットはサーバーが読めるの当たり前でしょ」
⬇
「読めるの当たり前、のほうがおかしいよね?」
とSignal/WhatsAppが価値観をひっくり返したときと、かなり似ています。
AIチャットでも同じ問いが突きつけられた、というのが今回の面白さです。
何がそんなに新しいのか?:機能じゃなく「設計思想」が新しい
正直、機能だけ見れば「またAIチャット出てきたんだね」で終わります。
モデル名も、コンテキスト長も、ツール呼び出しも、何も出てきてない。
それでもエンジニア目線で見ると、アーキテクチャ思想がかなり攻めている。
「クラウドAI × E2EE」というわがまま設計
普通のE2EEアプリはわかりやすいです。
- クライアントで暗号化
- サーバはただのリレー
- 受信側で復号して表示
ところが今回やりたいのは、
「クラウド上でLLMを回しながら、
そのクラウド運営者は会話内容を読めないようにする」
これ、ぶっちゃけかなり無茶な要求です 🤔
どこかのタイミングでモデルは「平文としてのプロンプト」を読まなきゃ動けない。
Confer がどこまでやっているかはまだ不明ですが、
- クライアント → Confer サーバ:E2EE
- Confer サーバ → モデル実行レイヤ:
- 自社ホスト+メモリ上暗号化などのガチ構成を狙うのか
- あるいは外部LLM(OpenAI等)にTLSで投げちゃうのか
ここで設計を誤ると「Conferには読めないけど、外部LLMは読めちゃう」というオチになります。
Moxie が関わっている以上、「そこツッコまれて終わる構成」はやらないと思いますが、
実装レベルではかなりチャレンジングなテーマです。
「運営者も読めない」をプロダクトのフロントに出した
既存の大手LLMサービスも、
- 「企業向けは学習に使いません」
- 「ログ保持期間を短くできます」
など、プライバシー配慮オプションは出しています。
でもそれは基本的に 契約ベースの約束 なんですよね。
Conferはそこを一歩進めて、
「技術的に読めませんを前提に設計しました」
と宣言しようとしている。
ここで変わるのはユーザーが信じるものです。
- 契約ベース:
- 「読めるけど読まないと約束したから大丈夫です」
- アーキテクチャベース:
- 「そもそも読めないので、約束以前の問題です」
この差を、法務・コンプラ部門はめちゃくちゃ気にします。
エンジニアも「そこまで言うならアーキ図を見せてくれ」と言いたくなるやつです。
なぜそこまでしてE2EEなのか:AI時代の「観測しない勇気」

個人的に一番おもしろいポイントはここです。
現代のSaaSは、
ユーザーの行動を観測して、
それをプロダクト改善にフル活用する
ことが前提のゲーム設計になっています。
LLMサービスならなおさらで、
- どんなプロンプトが多いか
- どこで hallucination が起きているか
- どの出力にthumbs up/downがついたか
をゴリゴリ集めて、安全性評価やモデル改善に回している。
Conferは、そこに対して
「あえて観測しない を前提にLLMサービスを作るとどうなるか?」
を実験しようとしているように見えます。
これは正直、かなりラディカルです。
プロダクトマネージャー視点で見ると、
- 利用ログが(ほぼ)取れない世界で
- どうやってUX改善のPDCAを回すのか?
- どうやって安全性評価をするのか?
という、今まで避けてきた問いに向き合わされます。
競合と比べると何が違う?:OpenAI / Google / Anthropic との距離感
「機能の豊富さ」で勝負するサービスではない
- ChatGPT / Gemini / Claude
→ モデル性能、マルチモーダル、ツール連携、API、プラグイン… - Confer
→ まだそういう話は皆無。ただのチャットUI に見える
なので、「ChatGPT killer か?」と言われたら、全然違う と答えます。
Conferが刺しにいっているのは、たぶん次のゾーンです:
- エンタープライズで、
- 機密情報をガッツリ投げたい
- でも「ベンダーには絶対に見られたくない」
- かといってオンプレGPUクラスターを自前調達するのもキツい
- 医療、法務、金融、政府系など
- ログの扱いが死ぬほど面倒
- 規約より「技術的に安全」が効く世界
ここでは、ChatGPT Enterpriseの「契約的に読まないです」より、
Confer型の「そもそも読めません」の方が、説得力を持つシーンが確実に出てきます。
競合が一番イヤがるのは「マインドシェア」を取られること
Conferが今日・明日でChatGPTのシェアを削るとは思いません。
でも、こんな質問がPM会議で飛び始める未来は想像できます:
「うちも“運営からは読めないアーキテクチャ”オプションを用意しないと、
金融・ヘルスケア系を取りこぼしませんか?」
こうなると、大手ベンダーのゲームルールも変わります。
- 「ログ前提で最適化」から
- 「ログなしでも耐える設計」に一部寄せざるをえない
Signalが出てきたことで、
「メッセージングはE2EEがデフォだよね?」という空気が生まれたのと同じ構図です。
Conferは、「AIチャットにおけるE2EE前提」という空気を作りたいのだと思います。
ただ、懸念点もあります… 😇

正直、エンジニア目線だと「理想はわかるけど、運用どうするつもり?」という疑問がモリモリ湧きます。
モデル改善どうする問題
LLMサービス運営側からすると、E2EEはけっこう致命的です。
- 会話ログを人手でレビューできない
- 有害出力や誤回答の「具体例」を直接観測できない
- どのプロンプトパターンで死にやすいか分析しづらい
安全性向上にも、性能チューニングにも、データが決定的に足りない。
やろうとするなら、
- ユーザーが任意で「この会話だけは報告してもいい」と opt-in 共有する
- ローカルで匿名化・要約してメタ情報だけ送る
- そもそも基盤モデルの改善は他社(オープンモデルコミュニティ等)に委ねる
など、かなりトリッキーな戦略が必要です。
モデレーションどうする問題
E2EEメッセンジャーはずっと、
- 児童保護
- 犯罪利用
- テロリズム
との関係で政治的に叩かれ続けています。
AIチャットも同じことが間違いなく起こります。
- サーバ側でプロンプト・レスポンスを読めない
- でも「危険な使われ方は検知しろ」と言われる
この矛盾にどう答えるか。
クライアント側で安全性チェックを走らせるなどの構成もありえますが、
ユーザーがクライアントを改造したら意味がないので、根本解決にはなりません。
規制当局と真正面から殴り合う覚悟がないと、この路線は続けづらいです。
サポート・デバッグが地獄
エンタープライズ導入を想像すると、さらにしんどい。
- 「昨日の17:35にXさんが送ったプロンプトで変な回答が来たんだけど?」
→ でも運営側はログを見れない - 「この部署だけ応答が遅いんだけど?」
→ 内容に基づくトラブルシュートができない
結局、
- ユーザー側でログをエクスポートして共有してもらう
- それを一緒に見ながらサポートする
みたいな、人力運用に頼らざるをえません。
SaaSの「観測して即時に改善」という強みが、かなり削られるのは否めないです。
開発者視点で「Conferをどう捉えるか」
今のところ、Conferは
- APIもSDKも公開されていない(少なくとも記事ベースでは)
- 「自前アプリに埋め込むLLMバックエンド」として触れる段階ではない
なので、
「今すぐ自社プロダクトに採用しよう」というより、
「E2EE前提でLLMサービスを設計した場合のリファレンスケース」
として眺めるのが現実的だと思います。
自分がプロダクト側の立場で設計を考えるなら、次の問いを整理します:
- どのレイヤーまで暗号化するか?
- クライアント → 自社サーバはE2EEにする?
- 自社サーバ → LLMプロバイダはどうする?
-
「どこで平文になるか」をちゃんと図に描いて説明できるか?
-
何を犠牲にするかを明文化する
-
ログがない世界で、どうやって
- モデル改善
- モデレーション
- サポート
を回すのか?
「観測しない」ことのコストを、経営にどう説明するか?
-
規制・監査との折衷案を決めておく
- ログ保存義務がある業界で、本当にフルE2EEでやるのか?
- 「鍵を誰が持つか」「どのイベントで開示されうるか」まで詰める
Confer は、これらの問いを無理やり今のタイミングで可視化してくれた存在、という意味で価値があります。
プロダクションで使うか?正直まだ様子見です

技術者としての正直な感想をまとめると:
- アイデア&メッセージング
- めちゃくちゃ良い。
「AIチャットの世界にもSignal的価値観を持ち込む」という動きは歓迎です。 - 実用サービスとして
- まだ何もわからない。
モデル性能も、E2EEの具体実装も、運用ポリシーも未知数。
当面の立ち位置は、
- 個人利用や、社内の「プライバシー重視層」が試してみる
- セキュリティ・法務・コンプラ部門向けに
- 「こういうアーキテクチャも実在します」という説明材料に使う
くらいが現実的だと思います。
エンジニアとしては、
「Conferが成功するかどうか」より、
「プライバシーファーストAIアーキテクチャ」というカテゴリが立ち上がるか
のほうが、長期的には重要です。
数年後、
- 「え、あのサービス、いまだに運営から会話ログ読めちゃうの?😨」
- 「AIチャットならE2EE対応が当たり前でしょ」
という空気になっている可能性は、割とある。
Confer は、その未来を「ありえる選択肢」として可視化した一歩目、くらいに見ています。
じゃあ、今なにをすればいいか?
実務的には、次の2つだけやっておく価値があります。
- 自分たちのLLM利用の「平文ポイント」を棚卸しする
- どこで暗号化されていて
- どこで平文になっていて
-
どこにログが残っているか
を、図にして説明できるようにする。
これだけでも、社内議論の質がかなり変わります。 -
「読めない前提」の設計を一度シミュレーションしてみる
- もし会話ログを一切保存できなかったら、
- どんな機能が死ぬか?
- どんな運用が成立しなくなるか?
- 逆に、クライアント側だけでできることは何か?
この思考実験をやっておくと、Conferのようなサービスが本格的に選択肢に入ってきたとき、
「うちはここまでは踏み込める」「ここから先は無理」と冷静に判断しやすくなります。
ぶっちゃけ、E2EE前提のAIチャットは「運営としてはつらいけど、ユーザーとしては最高」です。
そのギャップをどう埋めていくのか。
Confer は、その葛藤をようやくテーブルの上に乗せてくれた存在だと感じています。


コメント