
「また OpenAI 依存のアーキテクチャか…」って、設計ドキュメントを書きながらため息をついたこと、ありませんか?
ベストプラクティスも SDK もサンプルも全部 GPT 前提。
でも心のどこかで「この一極集中、いつか逆襲されるよな…」と感じている。
その「第二勢力」が、いきなり 34 兆円の評価額と 3 兆円の弾を持って戦場に出てきた、というのが今回の xAI シリーズEのニュースです。
しかも「X(旧Twitter)のリアルタイムデータ + オープン寄り文化 + 検閲ゆるめ」という、かなりクセの強いキャラで。
この記事ではニュースの要約ではなく、「開発者として、アーキテクチャとリスクをどう考え直すか」という観点で整理してみます。
一言でいうと:AI界の「Android 上陸」っぽい出来事

今回の xAI の動きを、あえて乱暴にたとえると:
「iOS 一強だったスマホOS市場に、Android が本気で殴り込んできた瞬間」 に近いです。
- OpenAI = iOS
- クローズドだが完成度高い
- UX とエコシステムはガチガチにコントロール
-
エンタープライズ受けは最高
-
xAI/Grok = Android っぽいもの
- オープンウェイト(=ソースは閉じてるが、実行バイナリは配る感じ)
- X データと深く結合した「プラットフォーム前提」の設計
- ルールゆるめ・ポリコレ弱めで「なんでもできそう」な自由さ
正直、この 3 兆円調達は「単なる話題作りスタートアップ」から「長期戦に耐える本命プレイヤー」への昇格宣言です。
GPU を何年も燃やし続けられるだけのキャピタルがついた、という意味で。
何がそんなにヤバいのか:X データ × 巨額キャピタル × 逆張り文化
技術的に目新しい API が出たわけではありません。
でも、組み合わせがかなり危ない(=強い)。
X(旧Twitter)のリアルタイムデータと「ネイティブ統合」
Grok の最大の特徴は、
- X 上のポスト・トレンド・リプライ・ハッシュタグなど
- ほぼリアルタイムのストリーミングデータ
を、モデルのコンテキストとして直接吸い込める方向に全振りしていること。
これ、開発者目線で言うと:
- 炎上検知
- ブランドモニタリング
- 投資家向け「ニュース+センチメント」ダッシュボード
- 口コミベースのレコメンド
- リアルタイム世論解析
みたいな 「ソーシャルを前提にしたアプリ」では、もはや xAI が第一候補になりうる、ということです。
OpenAI もブラウジングはできますが、
- 汎用 Web クローリング + 検索経由
- レイテンシ・鮮度は「検索エンジン的な限界」に縛られる
のに対して、xAI は プラットフォームの「生データの蛇口」を握っている。
これは構造的にかなりデカい差です。
オープンウェイト路線という「逆方向の本気」
もうひとつのポイントは、オープンウェイト戦略を続けそうなこと。
- モデルを API だけでなく、重みとしても配る
- 企業は自社 VPC / on-prem に持ち込んでセルフホストできる
- 独自フィルタリング・独自監査を上に被せられる
ぶっちゃけ、
「クローズド API でロックインしたい OpenAI」と
「とにかく広くばら撒いてエコシステムを押さえたい xAI」
で、思想が真逆です。
しかも今回の 3 兆円で、
- H100/B100 世代 GPU をごっそり確保
- データセンター+ネットワーク帯域を Cisco・Nvidia とガチ連携
するわけで、
「オープン寄りでやりたいけど、性能しょぼいのは嫌」問題を殴って解決しに来た構図。
これは正直、開発者としては魅力的です。
「フィルタ緩め」文化が、資本を得て固定化される
Grok は最初から、
- セーフティフィルタを相対的に緩める
- ポリコレ・過剰検閲を嫌う層に刺さる設計
をウリにしてきました。
そこに 3 兆円が乗った、ということは、
「緩め路線」が短期的な実験ではなく、文化として固定される可能性が高い
ということでもあります。
これは、
- オープンAI/Anthropic の「安全性マシマシ路線」
- xAI の「自由度マシマシ路線」
という、価値観の分岐が資本レベルでロックインされたとも言えます。
なぜ開発者に効いてくるのか:OpenAI 一極集中アーキテクチャの「賞味期限」
ここからが本題です。
今回のニュースの本質は、
「OpenAI 前提でアーキテクチャを固定するのは、そろそろ危険シグナル」
になったことだと思っています。
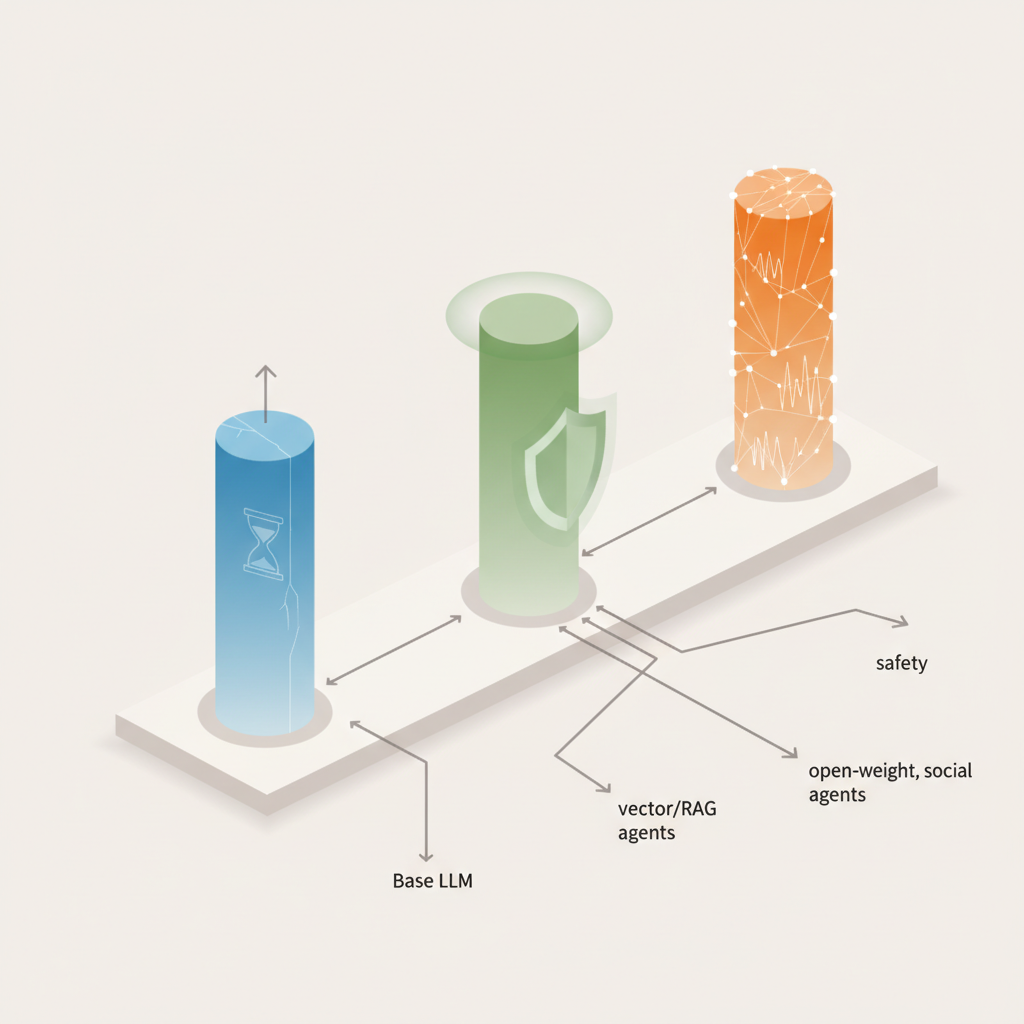
xAI が本命級「第三極」になった影響
これまで多くのチームで見てきた構成はだいたいこんな感じでした:
- ベース LLM: OpenAI (GPT-4.x, o3 など)
- セーフティ: OpenAI のガードレールにかなり依存
- ベクタDB+RAG: 任意(Pinecone / pgvector / Qdrant 等)
- エージェント: Assistants API or LangChain 前提で組む
ここに対して今後は、
- 「X データ × Grok 前提」のアーキテクチャ
- 「Anthropic(安全性重視)」前提のアーキテクチャ
をちゃんと比較検討すべき環境になった。
つまり、3 極構造です。
- OpenAI = UX・機能の完成度トップ
- Anthropic = 安全性・法務コンプラ志向トップ
- xAI = リアルタイム・ソーシャル連携・オープンウェイト志向トップ
この三者を前提に、「どこまで抽象化するか」「どこまでベンダー特化でチューニングするか」を設計しないと、
2〜3年後に技術的負債として跳ね返ってくる可能性が高いと感じています。
各社比較:どんなプロダクトなら xAI/Grok 一択になりうるか?
軽く整理してみます。
OpenAI vs xAI vs Anthropic をざっくりマッピング
OpenAI を選ぶとき
- ガバナンス・監査・法務がうるさいエンタープライズ
- マルチモーダル(画像・音声・ビデオ)を幅広く使いたい
- Azure / 既存クラウドネイティブなスタックとシームレスに統合したい
- 「とにかく壊れにくい API とドキュメント」を最優先
xAI / Grok を選ぶとき
- X 上のトレンド・会話をプロダクトのコアにしたい
- 「検閲が厳しいと価値が落ちる」コミュニティ(ゲーム、同人、匿名SNS 等)
- オープンウェイト前提で、
- 自社 VPC / on-prem で完結させたい
- X データ+自社ログでガチ RAG を組みたい
- リアルタイム性と「ネット直結」感を UX の核にしたい
Anthropic / Claude を選ぶとき
- 社内ポリシーがかなり保守的(金融・公共・医療など)
- 「モデルの憲法」「安全性の原則」がないと経営陣が首を縦に振らない
- 利用者が一般消費者で、炎上リスクを極小にしたい
ただ、懸念点もあります…🤔
ここまで書くと、「よし、Grok で全部置き換えだ!」と思う方もいるかもしれませんが、
正直、プロダクションでメインに据えるには注意点だらけです。
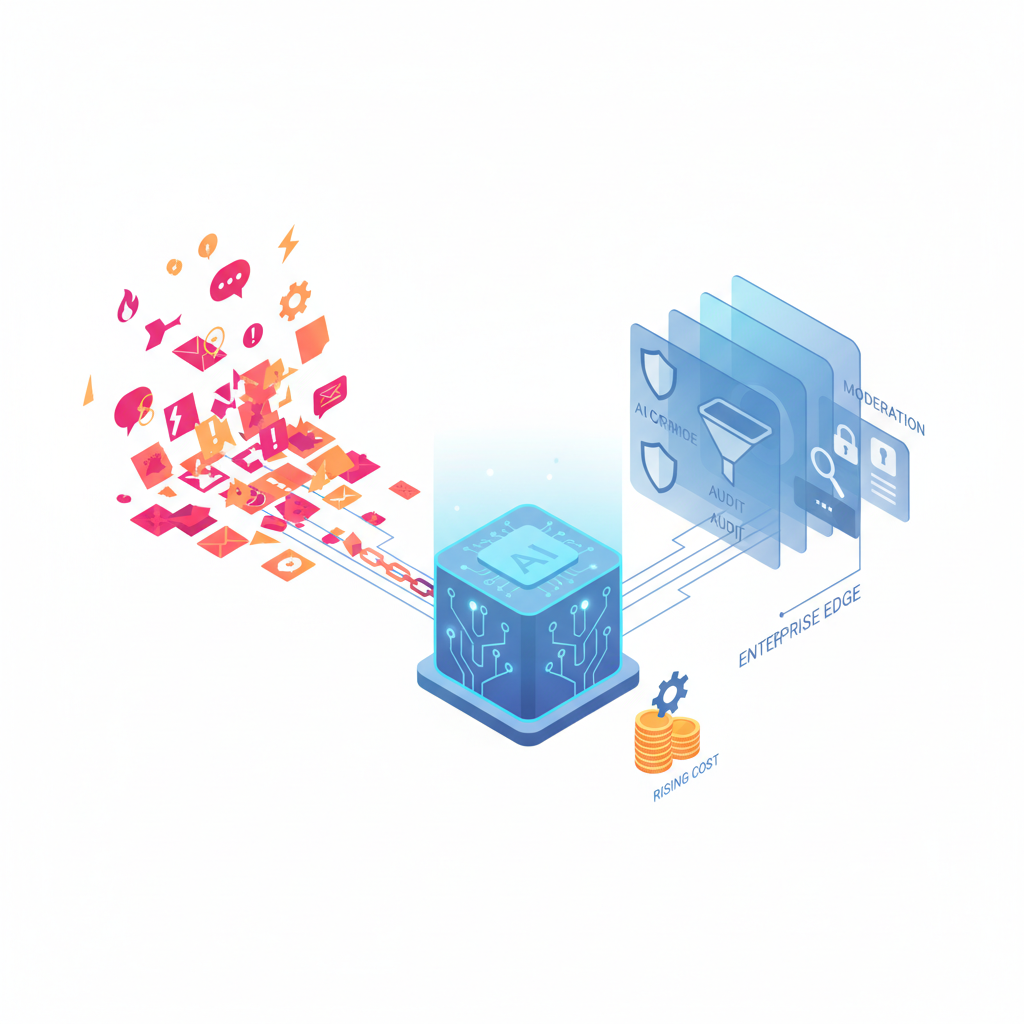
X データ依存という「毒にも薬にもなる成分」
利点はわかりやすいです。
でも、開発者として冷静に考えると:
- X は誤情報・陰謀論・過激な言説・ボット・スパムの宝庫
- それがトレーニングにもリアルタイム推論にも混ざる
結果として、
- 出力が「センセーショナルな言説」に寄りがち
- 微妙な差別表現やヘイトが混ざるリスク
- 企業利用にはコンプラ的に危うい場面も出やすい
という リスクフレーバー付きのモデルになります。
ぶっちゃけ、
エンタープライズ案件で「デフォルトのまま Grok を投げる」のは、
法務が OK を出す気があまりしません。
現実的には:
- xAI の前後に自前のモデレーションレイヤー
- プロンプトフィルタ
- 出力フィルタ
- ログ監査
- さらには社内ポリシーの再設計
がほぼ必須になる。
つまり、「自由度の高さ」がそのまま開発・運用コストになって跳ね返る懸念があります。
ベンダーロックインの新しい形
「X ネイティブに最適化」って、聞こえはいいんですが、
これはそのまま ロックインの別形態でもあります。
- ユーザ認証・行動ログ・レコメンド・通知
- モデル推論
- コンテキストとなるソーシャルデータ
これを全部「X / xAI スタック」に乗せると、
- 他クラウドに逃げにくい
- 別の LLM に乗せ替えるとき、トレンド情報やリアルタイム性を再現するのが大変
- データポータビリティも怪しくなりがち
という、アーキテクチャ的負債を抱えます。
正直、
「X 連携を使い倒したいプロダクト」と
「クラウド/モデルをいつでも乗り換えたいプロダクト」は、
設計段階からきっぱり分けて考えるべきだと思います。
「資金=完成度」ではないギャップ
20B USD(200億ドル)調達、評価額 34 兆円。
数字は派手ですが、開発者が日々向き合うのはもっと地味な部分です。
- API のエラーハンドリング
- バージョニングポリシー
- レート制限とクォータ管理
- 日本語サポートと多言語評価
- ドキュメントとサンプルコードの質
ここは一朝一夕では追いつけません。
正直、「OpenAI 並みに気持ちよく使える API 体験」には、数年単位の時間差が出てもおかしくない。
プロダクションで使うなら、
- 致命的な Breaking Change がないか
- サポート体制(SLA 含む)はどうか
- 障害時・規制時の事業継続リスク
を冷静に見てから、徐々にトラフィックを振り向けるくらいが現実的です。
じゃあ実務ではどうする?(個人的な「Verdict」)
エンジニアとして、今どう動くかを自分なりに整理すると、こんな感じです。
いきなりメインにはしない。でも「本気で触りに行く」フェーズ
プロダクションでいきなり中心に据えるか?と言われると、
正直まだ様子見です。
- セーフティ・モデレーションの安定度
- API の互換性・障害実績
- 日本語含む多言語性能のばらつき
ここが見えるまで、
いきなり基幹システムに突っ込むのはギャンブルすぎる。
ただし、PoC・個人開発・プロトタイピングでは積極的に触るべきだと思っています。
- X 連携アプリ
- トレンド分析ダッシュボード
- 炎上検知・センチメント分析ツール
こういう「X 前提」の領域では、
Grok 前提の設計を一度体験しておくこと自体がアセットになります。
今から「マルチプロバイダ前提の抽象レイヤー」を用意する
今回のニュースで一番重要なのは、
「OpenAI 一社に全振りする設計は、もう戦略として危うい」
というシグナルだと捉えています。
- OpenAI
- Anthropic
- xAI
少なくともこの 3 つは、切り替え可能 or 並列利用可能な設計にしておきたい。
具体的には:
- モデル呼び出しを直接 SDK にベタ書きしない
LLMClientみたいなインターフェースを自作 or ライブラリで用意- セーフティポリシーの差異(プロンプト拒否・出力遮断)をアプリ層で吸収できるようにする
これを今からやっておくかどうかで、
2〜3 年後の「移行コスト」が桁違いに変わります。
「X ネイティブ」と「非 X」を意識的に分断する設計
xAI / Grok の強みは明確です。
ただし、それにベッタリ乗ると、X 依存のロックインもかなり強くなる。
なので、
- X がコアな価値になっている機能
- 例: ソーシャルリスニング、トレンド解析
- そうでない機能
- 社内検索、ドキュメント QA、業務チャットボット等
をコンポーネントレベルで分離して設計し、
- 前者は xAI/Grok 最適化を許容(ロックイン前提)
- 後者はマルチクラウド/マルチLLM前提で汎用に設計
という住み分けを、意識的にやるべきかなと思っています。
まとめ:これは「API リリース」ではなく、「前提条件が変わった」ニュース

今回の xAI の 200 億ドル調達は、
- 新しいエンドポイントが増えた
- 高性能モデルが一つ増えた
というレベルの話ではなく、
「X データ × オープン寄り文化 × 巨額キャピタル」という、まったく別ベクトルの AI プラットフォームが、長期戦の土俵に正式に上がった
という出来事です。
開発者としてのメッセージを一言でまとめると、
「OpenAI 一極前提でアーキテクチャを組むのは、そろそろ危ない。
最低でも xAI を含めた三つ巴を想定した設計に切り替えるタイミングに来ている」
だと思っています。
ぶっちゃけ、
まだ「全部 Grok にしようぜ」とは口が裂けても言えません。
ただ、「Grok 前提の世界線」を試さずに、OpenAI 一択で走り続けるのは、
数年後に後悔する未来がだいぶ見えてきた──そんなニュースだと感じています。


コメント