
「またツール増えたな……これ全部どうやってつなぐんだよ?」
最近のAIアップデート情報を眺めていて、正直こう思ったエンジニア、多いんじゃないでしょうか。
Runwayのサードパーティ連携、Claude Code Security、ComfyUIの新ノード、llmfit、SpargeAttn、TTSスイート……。
単体ではどれも「おお、すごいじゃん」なんですが、現場からすると、
- 本番ワークフローにどう組み込むのか
- どこまで任せていいのか
- どのタイミングで“賭け”に乗るべきか
が一番の論点です。
本稿は、ニュースの紹介というより「どこに賭けるべきか?どこは様子見か?」という話を、現場視点で整理してみます。
- 結論(先に)
- 一言で言うと:今起きているのは「AI版 Docker 時代」の到来
- Runway が「おしゃれツール」から「インフラ」になりつつある件
- Claude Code Security は「SAST ベンダーの無料広告」になるかもしれない
- ComfyUI スタック:週末で「AIスタジオ」は作れる。でも運用は別ゲー
- llmfit・SpargeAttn:「自前モデル」のハードルは下がるが、責任はむしろ重くなる
- Humanizer + Voicebox:倫理的に一番“地雷”なのはここ
- TTS-Audio-Suite v4.21.16:小さなバージョンアップに見えて一番ハマりやすい罠
- 「じゃあ、どれを今プロダクションに入れるのか?」という話
- 結論:プロダクションに入れるか?正直、ツールごとに温度差がかなりある
- 関連記事(あわせて読む)
- FAQ
結論(先に)
- 今は「全部乗り」より、レイヤーごとにPoC→小さな本番を回し、運用責任が持てるものだけ採用するのが安全です。
- Claude Code Securityは一次チェックとして早めに癖を掴む価値が高い(SASTの代替ではなく補助)です。
- Runwayはインフラ化が進むほどロックインも強まるため、抽象化と監視を前提に組み込みます。
想定読者:AI/生成系ツールの導入判断を迫られているエンジニア、EM、プロダクト/セキュリティ担当。
一言で言うと:今起きているのは「AI版 Docker 時代」の到来

今回のアップデート群、全部まとめて一言で言うと:
「マルチモーダル界の Docker + Docker Compose が一斉に出そろい始めた」
という印象です。
- 昔:
- 画像生成、TTS、動画アップスケール、コード解析…
それぞれバラバラのツールを手運用でつなぐ「VM 時代」。 - 今:
- Runway を「レンダリングマイクロサービス」として叩き、
- ComfyUI のノードグラフで画像・音声・動画を一気通貫で回し、
- Claude Code Security でCIにセキュリティチェックを足して、
- llmfit で自前モデルまでサクッと調整できる。
正直、「週末ハックでマルチモーダルの本格パイプライン作れます」レベルになりつつあります。
でも Docker 初期と同じで、「作るのは簡単、運用と責任は地獄」という未来も同時に見えているのが今回のポイントかなと
Runway が「おしゃれツール」から「インフラ」になりつつある件
何が変わったのか
Runway の「サードパーティ連携」路線は、ぶっちゃけかなりデカい方向転換です。
- 以前:
- クリエイター向けの“閉じた”ツール。
- ブラウザ開いてポチポチする世界。
- これから:
- REST / SDK 経由でジョブ投げて、
- Webhook で完了通知受けて、
- ID でアセット管理する「動画レンダリング API」。
Figma が「ただのデザインツール」から、API とプラグインでワークフローのハブになっていった流れとかなり似ています。
なぜ重要か
正直、こうなると Runway は「競合するサービス」ではなく「組み込むべきインフラ」になってきます。
- マーケのクリエイティブ生成を、
GitHub Actions から Runway 呼んで自動レンダリング - A/Bテスト用のバリエーション動画を、
API 叩いて一括生成 → S3 に格納 → 配信
みたいなことが普通にできる。
懸念点としては、ここまでパイプラインの中心に据えると、
- Runway から別プロバイダ(Pika, Adobe, 自前SDパイプラインなど)に移行するコストがバカにならなくなる
というロックイン問題は出てきます。
「レンダリングレイヤー抽象化するか?」みたいな話を真剣にやる必要が出てくるレベル。
Claude Code Security は「SAST ベンダーの無料広告」になるかもしれない

これ、ただの“賢い Copilot”じゃない
Claude の「Code Security」モード的なものは、
- コードの脆弱性検知
- リスクの説明
- 修正案の提示
にフォーカスした、AppSec / SAST っぽい使い方を狙っています。
似た領域だと、
- GitHub Copilot:生産性メイン、セキュリティは副産物
- 従来の SAST(SonarQube, Snyk Code など):静的解析+ルールベース
ですが、Claude は「説明能力」と「多言語対応力」でこの間を狙ってきた感じ。
中小〜スタートアップにはかなり刺さる
ぶっちゃけ、専用の SAST ツール入れるほどでもないけど、セキュリティちゃんとしないとマズい、というチームにはかなり現実的な選択肢になります。
- PR ごとの自動レビューコメント
- 高リスクファイルだけ毎晩スキャン
- 開発者がIDEで「これやばくない?」と聞ける
「とりあえず Claude で一次チェックしておこう」ができてしまう。
でも、SAST を完全に駆逐するかというと…かなり微妙
ここは意見分かれると思いますが、自分は:
「エンタープライズの SAST は、むしろ Claude のおかげで価値がはっきりする」
と見ています。
- LLM ベース:
- 柔軟、説明がうまい、でも確率的かつルールの一貫性がない
- SAST:
- つまらない・うるさい・でも決め打ちルールでコンプラと監査に強い
金融・医療・公共系の世界では、「このルールセットで N 年運用して、こういう検出結果が出てます」と説明できることが重要です。
そこに「LLM がそう言ってるから」の世界観をいきなり持ち込むのは、正直かなり厳しい。
現実路線としては:
- 中小:Claude Code Security + 軽量な OSS SAST
- エンタープライズ:既存 SAST + Claude は開発者体験改善用のレイヤー
という棲み分けに落ち着く気がしています。
ComfyUI スタック:週末で「AIスタジオ」は作れる。でも運用は別ゲー
ComfyUI 周りのアップデート(Actual‑Denoise、KittenTTS、動画アップスケールの Magnific など)は、明らかに
「画像だけじゃなくて、音声・動画まで含めたマルチモーダルパイプラインを、ノードグラフ一枚で回す」
方向に進んでいます。
良い面:Docker Compose みたいな“構成力”が手に入った
- Actual‑Denoise:
- ノイズスケジュールを細かくいじれて、
「元構図は維持しつつ、スタイルだけ変える」みたいな編集がしやすくなる - KittenTTS:
- テキスト → 音声を ComfyUI のノードとして扱える
- TTS も含めて一本のグラフで制御可能
- Magnific Video Upscaler:
- 低解像度で出した動画を、後処理で 4K まで持っていく
これを組み合わせると、
- プロンプトから静止画作成
- 軽めの動画生成モデルでアニメーション生成
- Magnific で高解像度アップスケール
- KittenTTS でナレーション生成
- 最後に全部 mux して一本の動画に
みたいな「YouTubeショート量産マシン」を週末で作れる世界です。
これは正直ワクワクします
悪い面:運用はマイクロサービス地獄の再来
ただ、ここが Docker 時代と同じ罠で、
- ノードが増えるほど
- VRAM の使い方がカオスになる
- どこで詰まってるのか分かりにくくなる
- パラメータも爆増
- サンプラー、シード、ステップ、sigma スケジュール…
「再現性」を維持するのがだんだん難しくなる
正直、「趣味プロジェクト」なら楽しいんですが、
商用パイプラインとして半年以上安定運用しようとすると、一気に難易度が跳ね上がるタイプのツールです。
個人的な立ち位置としては:
- PoC・社内ツール:ComfyUI フル活用、大いにアリ
- 対外サービス・長期運用:
- コンセプト確立後に、必要部分だけ SDK / API で書き直すのが現実的
くらいで見ています。
llmfit・SpargeAttn:「自前モデル」のハードルは下がるが、責任はむしろ重くなる

llmfit:scikit‑learn みたいに LLM を “fit” できてしまう世界
llmfit の思想は分かりやすくて、「LLM の fine‑tune を sklearn の .fit() みたいにしたい」というもの。
trainer = LLMTrainer(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
lora_r=16,
...
)
trainer.fit(dataset="data.jsonl", epochs=3, lr=2e-4)
正直、これがちゃんと動くなら、
- SaaS プロバイダに高いお金払って「専用モデルオプション」つけてもらうより
- 自前で LoRA 当ててしまった方が
- 早くて
- 安くて
- コントロール効く
ケースがかなり増えます。
ただし、ここで多くのチームが見落としがちなのが、
「学習は簡単になったけど、“評価と責任”は全く楽になってない」
という点です。
- どれだけ安全性・バイアス・漏洩リスクが悪化したかを、
誰がどうやって確認するのか? - 本番で事故ったとき、
「ベースモデルのせいです」とはもう言えない
このあたりをちゃんと設計できる組織じゃないと、「おもちゃ fine‑tune」で終わってしまい、むしろリスクだけ増やす結果になります。
SpargeAttn:長文コンテキストは“ただのオマケ”ではない
SpargeAttn のような「疎な Attention」は、
- 計算量:O(n²) → O(n log n) などに圧縮
- コンテキスト長を伸ばしやすくなる
という意味で、確かに魅力的です。
「32K トークンどころか 1M トークンいけます!」みたいな売り文句も出しやすい。
でも、ぶっちゃけると:
- 実際のアプリで「1M トークンを本当に活かせている」例はまだかなり少ない
- 疎なパターンにしたことで、
- どの情報が見落とされるか
- どういう失敗モードが出るか
が読みにくい
ので、「とりあえず長文対応してる風のモデルを出したいベンダー側には便利」くらいに見えてしまう側面もあります。
エンジニア視点では、
- 本当に長文が必要なプロダクト(法務文書、コードベース、研究論文など)だけ
- まずは PoC で評価してから採用
くらいの慎重さが妥当だと思います。
Humanizer + Voicebox:倫理的に一番“地雷”なのはここ
Voicebox系:ゼロショット音声はビジネス的には超魅力、でも…
Meta の Voicebox クラスのモデルや、それに近いゼロショット TTS は、
- 数秒のサンプル音声だけで声質・話し方をコピー
- 多言語・ノイズ混じりにも強い
という意味で、プロダクトにはめちゃくちゃ刺さります。
- プロダクトデモ動画を、
営業ごとに声を変えて生成 - カスタマーサポートの FAQ を、
各国言語+ネイティブっぽい声で自動生成
…みたいなことがたった数行コードでできる世界です。
ただ、この手の技術は悪用イメージが明確すぎるので、
- 金融・行政系のお客様は余計に疑心暗鬼になる
- 規制・ガイドラインの整備もほぼ確実に進む
という逆風も同時にセットでついてきます。
Humanizer:AIテキスト“バレ防止ツール”は、長期的にはかなり危険な流れ
「Humanizer」と呼ばれる系統のツールは、
- LLM っぽい文体を崩す
- AI 検知ツールをすり抜ける
ことを目的にしているケースが多いです。
正直、マーケ担当が「ちょっと機械っぽさを減らしたい」という用途に使うのはまだ理解できますが、
- レポート代筆
- 論文のゴーストライティング
- 身分を偽った口コミ生成
みたいなグレー〜ブラック用途と紙一重です。
長期的には、
- 「AI コンテンツはラベリング・開示が当たり前」
- 「ラベリングを意図的に外すツール」は
プラットフォーム側で規約違反扱い
という流れになる可能性はかなり高いと見ています。
個人的には、
「文章の自然さを上げるツール」としての Humanizer は歓迎、
「AI で書いたことを隠すための Humanizer」は、組織として禁止ルールに入れておいた方がいい
と思っています。
TTS-Audio-Suite v4.21.16:小さなバージョンアップに見えて一番ハマりやすい罠
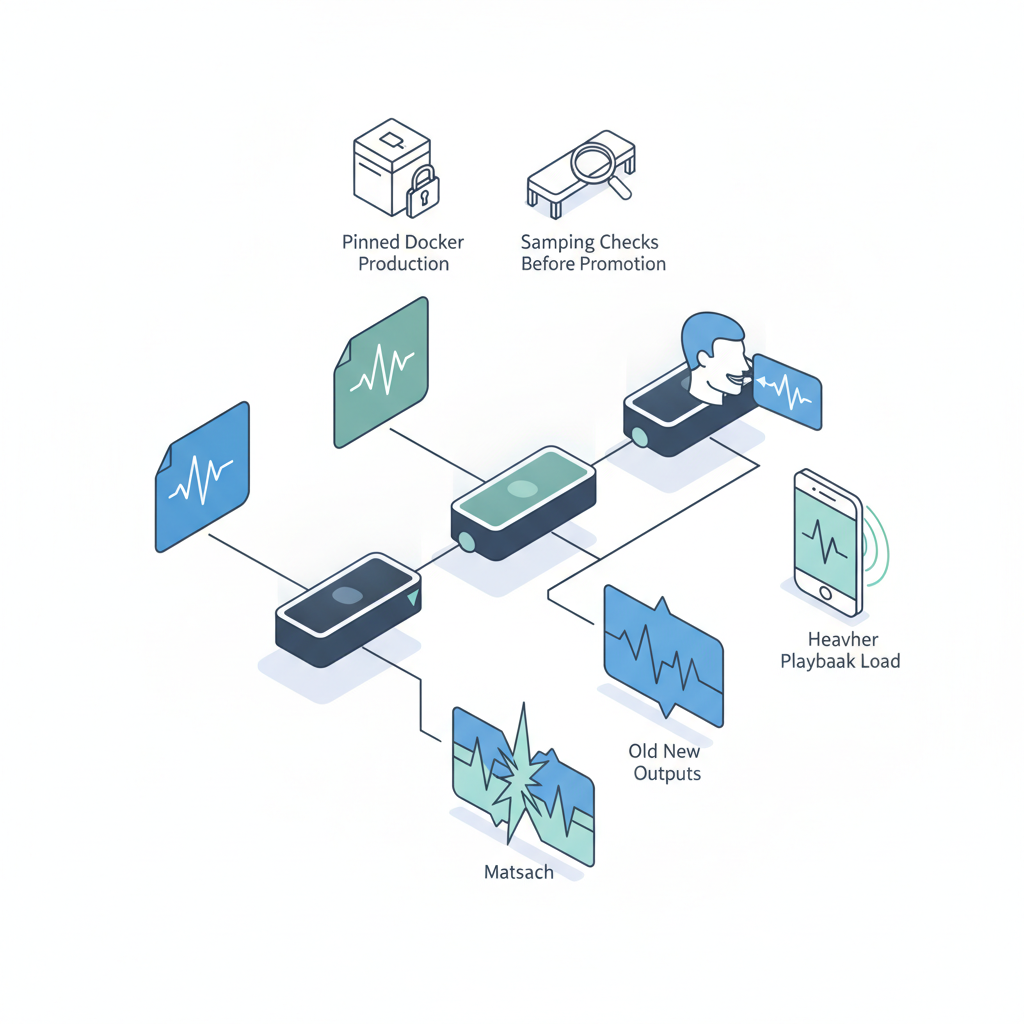
TTS-Audio-Suite のような「多エンジンTTSラッパー」は、
バージョン番号的にはマイナーアップデートでも、
- デフォルトのサンプルレート変更(24kHz → 44.1kHz など)
- デフォルトの話者IDの差し替え
- ノイズリダクションやポストプロセスのチューニング変更
だけで、下流のパイプラインが静かに壊れるタイプの危険があります。
- 口パク同期(lip-sync)がズレる
- モバイルアプリでの再生が重くなる
- 旧バージョンで作った音声と、
新バージョンの音声が混ざると違和感が出る
など、ユーザー体験側に地味に効いてくる。
個人的には、こういうツールこそ、
- 本番用の Docker イメージ内でバージョンピン止め
- 新バージョンはステージング環境で
サンプリングチェックしてから昇格
くらいの運用をしておかないと、気づいたら「なんか最近声変わった?」とサポートに問い合わせが来る、みたいな事故になります。
「じゃあ、どれを今プロダクションに入れるのか?」という話
最後に、自分ならどう判断するか、ざっくり優先度を分けてみます。
今すぐ PoC / 小さめ本番で試す価値が高いもの
- Claude Code Security
- 高リスクリポジトリの PR チェックにまず投入してみる
- 既存 SAST と併用しつつ、開発者の受け入れ度・ノイズ率を計測
- Runway サードパーティ連携
- マーケティングや社内資料用の動画生成パイプラインに組み込む
- ただし抽象化レイヤーを一枚かませて、ベンダーロックインを和らげる
- Design System 向け AI
- 新規プロダクトやブランド刷新時の DS 立ち上げに使う
- 最終決定は必ずデザイナーがレビュー、アクセシビリティは人間確認
PoC 止まりにしておきたいもの(まだ様子見)
- ComfyUI スタック(Actual-Denoise, KittenTTS, Magnific)
- 「こういうことできるよね?」を示すには最適
- でも長期運用を前提にすると、再現性・監視・スケールでまだツラい
- llmfit
- ユースケースを見極めるための実験には最高
- 本番投入前に、評価・安全性チェックの体制を固めてから
- SpargeAttn
- 長文コンテキストがビジネスの本丸なら、リサーチとして試す価値あり
- ただし、いきなりコアモデルをこれ前提で作るのはリスキー
組織のポリシーをまず決めてから触るべきもの
- Voicebox系 TTS
- 声の同意、クレジット、利用範囲(政治・金融など)は
事前にルール決めてから - Humanizer
- 「AIであることを隠す用途」は明確に NG にするかどうか
- コンテンツチーム・リーガル・セキュリティと一度テーブルについた方がいい
結論:プロダクションに入れるか?正直、ツールごとに温度差がかなりある

まとめると、自分のスタンスはこんな感じです:
- Claude Code Security
→ 中小〜ミドル規模のチームなら、むしろ「早めに入れて癖を掴んだ方が得」。
ただし、SAST の代わりではなく「フロントラインの相談役」として。 - Runway サードパーティ連携
→ 収益直結の動画パイプラインに組み込む価値は高い。
ただし、抽象化とモニタリングはきちんとやる前提で。 - ComfyUI マルチモーダルスタック
→ プロダクションの“心臓部”に置くには、まだ時期尚早。
PoC・R&D 用としては最高の遊び場。 - llmfit / SpargeAttn
→ 「モデルを持つ側」の組織になる覚悟があるなら、今から触っておくべき技術。
そうでないなら、無理に飛びつかなくてもいい。 - Voicebox / Humanizer 系
→ ビジネスインパクトは大きいが、倫理・規制・ブランドリスクも同じくらいデカい。
技術より先にガバナンスの設計が必要。
正直、今は「全部乗り」するフェーズではなく、
- どのレイヤーを自前で強くするか
- どこは外部インフラに任せるか
- どこはあえて“まだ触らない”か
を決めるフェーズだと思っています。
「とりあえず全部試す」は楽しいですが、
半年後に「これ誰が面倒見るんだっけ…?」となる未来もセットでついてきます。
そこまで見据えた上で、どこに賭けるか。
今回のラウンドアップは、その判断材料として眺めるのがちょうどいいかな、というのが自分の結論です。
関連記事(あわせて読む)
- Claude Sonnet 4.6 Release
- Google Gemini 3.1 Pro / Gemini 3.1 release
- Google Gemini 3.1 Pro Launch and Early Coverage
FAQ
Q. まず何をPoCすべき?
A. 既存開発フローに差し込みやすい「CI/PRのセキュリティチェック」「生成物の自動パイプライン」から始めるのが安全です。
Q. SASTは置き換えられる?
A. 監査・説明責任が必要な組織ほど、従来SASTは残しつつLLMを“補助レイヤー”に置く形が現実的です。
Q. ロックインを避けるコツは?
A. 生成/レンダリング系は「抽象化レイヤー」「入出力の標準化」「監視とコスト計測」をセットで設計すると移行耐性が上がります。

コメント