
「最近のLLMの研究動向を追おうとして、論文の数と専門用語の洪水に溺れたことはありませんか?」
「新しい ‘Deep Research モード’ 試してみたけど、どのモデルを信じていいか分からない…」
「ベンチマーク SOTA って言われても、それ本当に意味あるの?」
正直、ここ半年くらいの「LLM能力・安全性・ベンチマーク」界隈、ノイズが多すぎて開発者の時間を食い過ぎです。
でも、そのノイズの裏で、わりとガチのパラダイムシフトが起きています。
一言で言うと…
「LLMは ‘チャットボット’ から、Docker+Kubernetes 付きの “自律エンジニアリング基盤” に変わりつつある」
この記事では、最近の論文群(agentic LLM、latent CoT、THINKSAFE、RedBench、A³-Bench など)を踏まえて、
「何が本当に変わりつつあるのか」と 「エンジニア目線でどこまで付き合うべきか」を、かなり率直に書きます。
結論(忙しい方向け)
- モデル本体の性能比較より、エージェント化(役割分担)・推論コスト設計・安全/評価パイプラインが主戦場になりつつあります。
- 「Deep Research」系は導入の是非より、まず限定ドメインでの検証→評価指標→運用ログの順で固めるのが安全です。
- ベンチはスコアより攻撃/幻覚/再現性を見える化(RedBench系 + 自社タスク)し、意思決定の材料に寄せるのがおすすめです。
想定読者:開発リーダー/SRE/AI導入の意思決定者(PoC責任者)
いま起きていることを雑にまとめると

ざっくり言うと、最近の流れはこの3つに集約されます。
- LLMが “おしゃべりボット” から “自律エージェント+ツール群” へ
- 推論(reasoning)が、個人技から “産業プロセス” に
- 安全性と評価が、完全に “別のエンジニアリング職種” になりつつある
これ、インフラの歴史でいうと、
「生の Linux コンテナ時代 → Docker & Kubernetes 時代」
にかなり近いです。
- 生の LLM = 生コンテナ
- マルチエージェント、探索戦略、RAG のアーキ変更 = Kubernetes のスケジューラやService Mesh
- THINKSAFE、token-level filtering、RedBench, A³-Bench = Network Policy, PodSecurityPolicy, ベンチマークスイート
モデルそのものより、オーケストレーションと安全と評価の設計がメインストーリーになりつつある、というのが正直な印象です。
LLM は「一体型チャットボット」から「マルチエージェント研究者」へ
-1. “AI as co-researcher” は、単なる論文サマライズの延長じゃない
OpenAI 系の「AI が共同研究者になる」系のプロジェクトや、
Insight Agents / MDAgent2 みたいな専門ドメインエージェント論文が示しているのは、
「1つのでかいモデルに頑張ってプロンプトを書く時代は終わりつつある」
という事実です。
典型的な構造はだいたいこんな感じ:
- Planner エージェント:研究ゴールや分析要求をタスク分解
- Executor エージェント群:
- SQL / データ変換
- コード生成・シミュレーション実行(MDシミュレータ、ラボツールなど)
- Web/API 呼び出し
- Critic / Reviewer エージェント:
- 結果の妥当性チェック
- 安全性・倫理チェック
- 実験設計の修正
これ、アプリ開発の感覚で言うと:
「1体型モノリス LLM ではなく、マイクロサービス+ワークフローエンジン化してる」
にかなり近いです。
なぜこれが重要か?
- 科学系・BI系のユースケースで、
「LangChain で雑に ‘DB ツール+1モデル’ を繋いだだけ」の構成は、
構造的に負けが見えてきた ということです。 - Insight Agents のように、
- “Analyst”
- “SQL”
- “Visualizer”
- “Explainer”
みたいに 役割をきっちり分けるアーキテクチャのほうが、
実務でバグの切り分けもチューニングもしやすい。
正直、「なんでもできるジェネラルアシスタントです!」系のプロダクトは、
特定ドメインに最適化されたエージェント群にじわじわ食われていくと思っています。
-2. MDAgent2 が示す「垂直特化エージェント経済」のリアル
MDAgent2 のような分子動力学専用エージェントは、
「GROMACS / LAMMPS のスクリプト書いて、プロトコル QA して、シミュレーションまで回す」という、
かなりガチなワークフローに踏み込んでいます。
ここで重要なのは、
- MDシミュレータ側が LLM から叩きやすい API を提供し始める
- LLM 側は、ドメイン固有の “やってはいけないこと” を安全制約として持つ
という、両側のインフラ整備が進むこと。
これは実務的には:
「GitHub Copilot みたいな ‘なんでも屋’ ではなく、
“○○専用 Copilot” が各業界で立ち上がる」
未来にかなり近いです。
ぶっちゃけ、ここにプロダクトチャンスが一番あると思っています。
推論は「チェーン・オブ・ソート芸」から「計算資源を食う工学」へ

ここ半年の reasoning 系論文を眺めると、はっきりしてきた流れがあります。
「推論の中身を、観測可能な自然言語の鎖から、
観測困難な潜在表現+探索戦略に逃がし始めている」
具体的には:
- ALiCoT / latent CoT (PLaT)
- CoT をそのまま出さずに、内部で圧縮・潜在化して計算だけする
- トークンコストを 10x〜50x 減らす
- RSE (Recycled Search Experience)
- 過去の探索・ツール呼び出しの「軌跡」を再利用する
- 推論を “キャッシュ可能な経験” として扱う
- MAXS (Meta-Adaptive eXploration Strategy)
- 「どの探索アルゴリズムで攻めるか」自体をメタ学習で最適化
デベロッパー目線で言うと:
- CoT を素直に全部吐かせるとコストが死ぬ
- でも CoT を完全に切ると精度が死ぬ
- → 「中でこっそり考えて、表にはあまり出さない」方向へ
という、けっこう分かりやすい圧力が働いています。
-1. 透明性 vs コスト:安全チームと開発チームのバトルが始まる
PLaT/ALiCoT 系のアプローチはインフラ的には超魅力的ですが、正直こういう懸念があります。
- 規制・監査側からすると:
- 「モデルが何を考えて、その結論に至ったか見えない」
- → 説明責任が取りづらい
- Thought-Transfer 攻撃論文が示したように:
- CoT 自体が汚染チャネル(悪意ある “思考パターン” の注入路) になり得る
- 一方で、CoT を完全に隠すと、その汚染の検知も難しくなる
つまり、
「観測可能な CoT は攻撃ベクトルでもあり、安全インタフェースでもある」
というジレンマが生まれている。
正直、このバランスは今後2〜3年、
インフラチーム・セキュリティチーム・法務がずっと揉み続けるテーマになると思っています。
安全性と評価は、もはや “後付けのガードレール” ではない
ここが一番変わったポイントです。
THINKSAFE, token-level filtering, RedBench, A³-Bench, DeepResearchEval…
これらを全部眺めると、明確にこう言えます。
「安全性と評価は、モデル開発と並列の “専門職” になった」
-1. THINKSAFE と token-level filtering:
「覚えさせない安全」と「自分で危険例を作る安全」
昔の RLHF 的発想は「とりあえず全部学習して、出力だけ人間がしばく」でした。
最近の流れはかなり違います。
- token-level data filtering(Anthropic 系)
- 危険能力(バイオラボ手順、エクスプロイトコード等)に対応するトークンを
事前学習データからそもそも削る/弱める - つまり 「覚えさせない安全」
-
結果として
- 高レベル議論はできる
- でも step-by-step 手順は吐けない
みたいな「能力プロファイル」がモデルごとに出てくる
-
THINKSAFE
- モデル自身が危険そうなプロンプトと応答例を自動生成して、
それで自分をさらに安全ファインチューニングする - 人間レッドチームに全部頼らず、
「安全データ生成も半自動化する」 方向
これ、インフラ観点だとかなり大きい変化で、
- 安全性が「ポリシー」じゃなくて データパイプラインと学習レシピに埋め込まれている
- ベンダー間の「能力差」が、ハードウェアやモデルサイズより “データとフィルタリング方針” に寄っていく
という現象が起きています。
ぶっちゃけ、オープンウェブ丸呑みモデル vs token-level で絞ったクリーンモデル の対立は、
この1〜2年でかなり政治的な論争にもなるはずです。
-2. RedBench, A³-Bench, DeepResearchEval:
「MMLU でマウント取り合う時代は終わり」
コミュニティを見ていても、「どの Deep Research AI が一番マシ?」という議論は増えている一方で、
MMLU や GSM8K の点数マウントにはみんな飽きている印象があります 🤔
新しいベンチマーク群がやっているのは、ざっくりこうです:
- RedBench
- 多種類の攻撃スタイル(jailbreak, prompt injection, obfuscation)を網羅する安全ベンチ
- 「このモデル、○○系攻撃に弱いよね」がちゃんと見える化される
- A³-Bench
- エージェントとしての記憶・マルチステップ推論を測る系
- 実際のエージェントタスクに近づけた評価
- DeepResearchEval
- 「研究者ペルソナ」が与えられた状態での文献調査・事実検証を自動評価
- OpenAI/Anthropic が “Deep Research モード” を推す文脈とかなり相性が良い
ここで怖いのは、
「ベンチマークにチューニングしすぎて、現実世界でのロバスト性が置き去りになる」
という、ImageNet → COCO でも散々見たやつです。
正直、RedBench や A³-Bench は 必要条件にはなっても十分条件にはならない。
「RedBench 95点です!」と書いてあるモデルを見たら、
「あ、これは RedBench 対策だけは死ぬほどやったんだな」 と冷静に見る必要があります。
LangChain 的世界観 vs 新しいエージェントスタック

コミュニティでもよくあるのが、
「LangChain / LlamaIndex + RAG でだいたい十分では?」
という問い。
正直なところ、“配管レイヤーとしては” まだめちゃくちゃ有用ですが、
最近の論文群が描いている将来像とは、かなりギャップがあります。
-1. 何が変わるのか?
- LangChain 的世界
- チェーン、ツール、メモリの抽象化はあるが、
- 探索戦略(self-consistency, tree search, MAXS 的なメタ探索)はユーザー任せ
- 信頼度推定や、Epistemic Context Learning 的な「誰を信じるか」のモデリングもユーザー任せ
- Insight Agents / MDAgent2 / MAXS 系
- 「このドメインでは、この役割分担・探索戦略・ツール構成が強い」という
ドメインオピニオンが最初から組み込まれている - つまり「ライブラリ」ではなく「半分 SaaS / 半分フレームワーク」に近い
ぶっちゃけ、
- LangChain はこれからも Kubernetes 的 “低レイヤーオーケストレータ” であり続ける
- でもお金を生むのは、各ドメイン特化の “マネージドエージェントサービス” の方
だと見ています。
「チャットで自社ドキュメント検索できます」レベルの RAG プロダクトは、
OpenDecoder 的なデコーダ直結型 RAG + 専用ベンチでチューニングされた vertical agent に普通に負ける未来しか見えないです。
ただし、懸念点も山ほどある(ここをナメると死ぬ)
ここまでだと「うおー AI すげー!」で終わってしまうので、
実装側としてガチで気をつけるべき “ヤバめのポイント” もまとめておきます。
-1. システム複雑性が Kubernetes 並みに爆増する
- マルチエージェント(Planner / Executor / Critic)
- 動的ロール割り当て(タスクに応じて Critic 多めにする等)
- MAXS 的なメタ探索
- RSE 的な過去探索の再利用
- CSE(Controlled Self-Evolution)的な自己改善ループ
これ全部を本気で入れると、
「マイクロサービス地獄+ML Ops地獄+安全性評価地獄」
が一気にやってきます。
ログ・トレース・メトリクス・コストの可視化を
最初から設計に含めないと、デバッグ不能な黒魔術システムが出来上がります。
-2. コストとレイテンシは、思ってるよりキツい
- エージェント間のやり取り
- ディベート
- 自動評価・自己改善ループ
- Safety チェック
これらは1ステップごとに LLM 呼ぶので、
単純にトークン数ベースで “どれくらい高くなるか” を最初に見積もるべきです。
ALiCoT / latent CoT が「CoTを安くする」方向に頑張っている理由は、
裏返すと「このままだと経済的に破綻する」という危機感でもあります。
-3. メモリとプライバシー:モザイク記憶という悪夢
Mosaic Memory 論文が警告しているのは、
「モデルはバラバラな断片情報から、かなりえげつない再構成ができる」
という現実です。
- 1つのドキュメントに全部の秘匿情報がなくても
- いろんな会話ログ・ドキュメント断片をまたいで
- モザイクのように組み合わせて再現してしまう
RAG や過去ログ活用を考えるとき、
「ちょっとマスクしてるから大丈夫でしょ?」は、
セキュリティ的にかなり甘い認識になりつつあります。
エージェント間でのトレース保存(RSE 的な経験リサイクル)も、
「どこまで保存してよいか」「どこから削除するか」 を真面目にポリシー化しないと危険です。
-4. Thought-Transfer 攻撃:CoT は新しい攻撃面
Thought-Transfer 論文が指摘したように、
- 明示的な CoT を学習・利用するモデルは、
- 「悪意ある思考パターン」をデータポイズニングで注入しやすい
- そのパターンが推論時に再利用されることで、
- 安全ポリシーをすり抜ける「裏口思考スタイル」が生まれる可能性がある
これ、
「オープンソースの CoT データセットを無邪気に学習させる」のが
どれだけリスク高いかを示しています。
ぶっちゃけ、
“CoT データのサプライチェーン管理” が今後の安全エンジニアリングの新しい仕事になるはずです。
デベロッパーとして、今なにをすべきか?
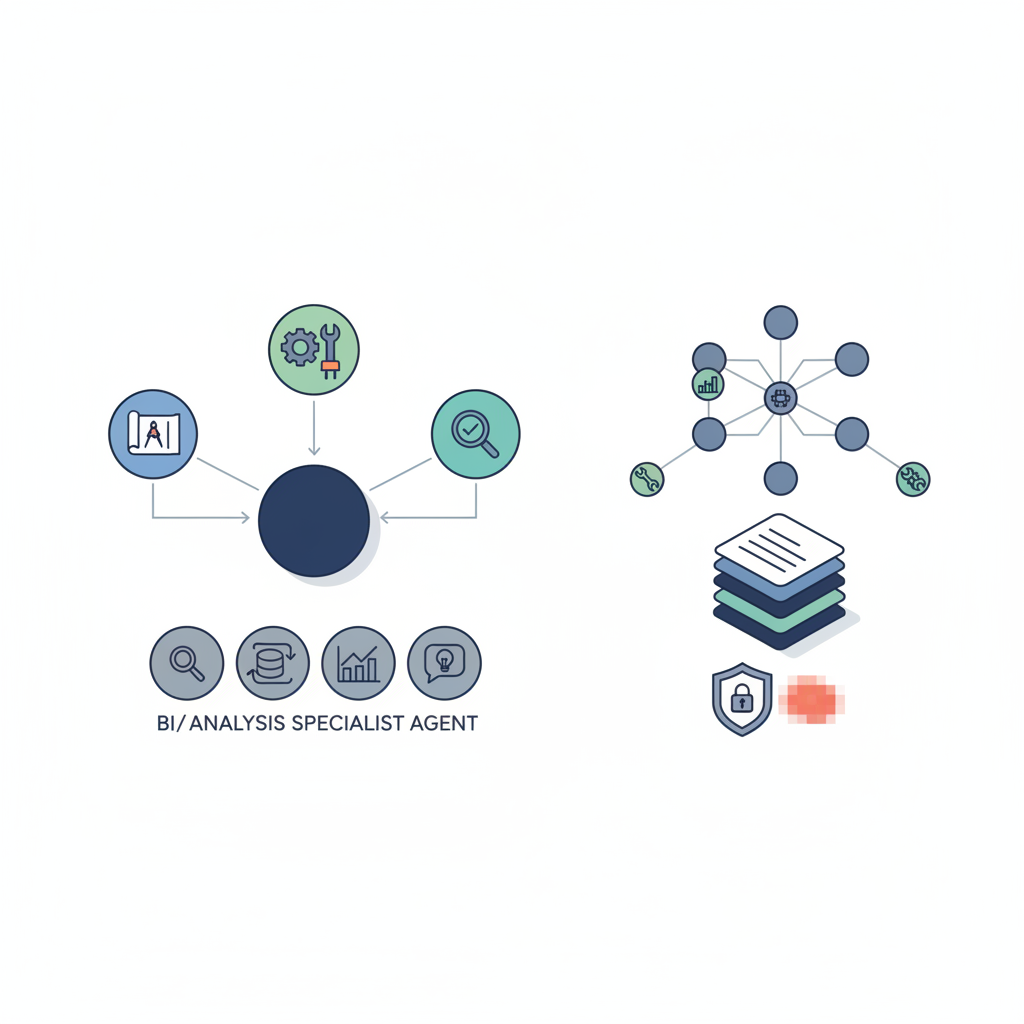
ここまで読んで「で、結局何をやればいいの?」となると思うので、
実務的なアクションに落とします。
-1. アーキテクチャ:1モデル主義から、役割分担エージェントへ
- 「なんでも 1 モデル+RAG+長プロンプト」で頑張るのをやめる
- 少なくとも:
- Planner
- Executor(ツール呼び出し役)
- Critic / Verifier
の3役には分ける
BI/分析・科学系なら、Insight Agents や MDAgent2 がやっているような:
- Query理解
- データ変換 / SQL
- 可視化
- 説明
といった 職能別エージェントに寄せるのが、現時点のベストプラクティスだと思います。
-2. 推論トレースを「ちゃんと」ログに残す(が、その怖さも理解する)
- 単なる Q&A ログではなく:
- CoT(可能なら)
- ツール呼び出しのシーケンス
- 分岐した探索ツリー(RSE 対応可能な形で)
を保存しておくと:
- 後で RSE 的に再利用できる
- バグ調査・安全監査に使える
ただし Mosaic Memory / Thought-Transfer の観点から:
- PII やセンシティブ情報を含まないように 前処理パイプラインをちゃんと作る
- 外部から持ち込まれた CoT を学習データ化する場合は
出所と内容の検証プロセスを設ける
ここをサボると、本気で後悔する未来が見えます。
-3. 安全は「後でガードレール」ではなく、データ設計から
- もし自前で事前学習や大規模ファインチューニングをするなら:
- token-level filtering 的な「能力カット」の発想を検討する
- 汎用モデルを使うだけでも:
- THINKSAFE 的な自己生成安全データ+人間レッドチーム+RedBench 的 eval
の 組み合わせ を意識する
「ベンダーが安全と言っているから大丈夫でしょ」は、
さすがにもう通用しないフェーズです。
-4. 評価指標を “現場寄り” に刷新する
- MMLU, GSM8K だけ見てモデルを選ばない
- やるべきは:
- A³-Bench 的なエージェントタスク
- DeepResearchEval 的な文献調査タスク
- RedBench 的な安全タスク
に近い 自社版ベンチ を、
小さくてもいいので作っておくこと。
「どの Deep Research AI が一番マシか?」を Reddit や X で見ていても、
最終的には自分のユースケースでしか判断できません。
関連記事(合わせて読むと整理が速い)
- GitHub Copilotのモデル選択自由化(Business/Enterprise向け新機能)
- Claude Sonnet 4.6とは?Opus級をミドル価格で使う判断ポイント
- Google Gemini 3.1 Pro / Gemini 3.1 release
FAQ(導入判断でよく詰まる所)
Q. まず追うべきは「能力」「安全」「ベンチマーク」のどれ?
A. 体感では評価(自社タスクでの再現性)が最優先です。能力と安全は評価で“差が出た箇所”を起点に深掘りすると、追う範囲を絞れます。
Q. Deep Research系を本番投入しても大丈夫?
A. いきなり全面投入はおすすめしません。限定タスク(調査/要約/レビュー補助)から始め、ログ・コスト・誤りパターンを見て段階的に広げるのが安全です。
Q. CoT(思考過程)を残す/残さないはどう決める?
A. 監査/デバッグ目的なら有用ですが、攻撃面とプライバシーのリスクも上がります。保存期間・マスク・アクセス制御を先に決め、必要最小限の粒度で運用するのが現実解です。
Q. ベンチのスコアはどの程度信じていい?
A. 必要条件としては有用ですが十分条件ではありません。自社の業務フローに近いミニベンチ(例:調査→根拠→レビュー→差分提案)を用意し、そこに寄せて判断するのが確実です。
結論:プロダクション導入するか?正直、段階的に “限定導入” が妥当
個人的な結論を言うと:
「マルチエージェント+高度な推論+安全スタック全部盛りを
いきなりプロダクションに突っ込むのは、正直まだやめた方がいい」
理由はシンプルで、
- システム複雑性
- コスト
- 安全面の “未知の未知”
- ベンチマーク過学習リスク
が、どれもまだ見えきっていないからです。
一方で、
「エージェント・ツール連携・安全評価を “プロトタイプとして” 触り始めない組織は、
2〜3年後に Kubernetes 触ったことないインフラチームみたいな立場になる」
という危機感もあります。
なので、おすすめのスタンスは:
- 限定ドメイン(BI分析、社内ドキュメント検索、コード補助など)から
小さめのマルチエージェント構成を試す - 推論トレース&安全ログをちゃんと集めて、
自社なりの “A³-Bench / RedBench / DeepResearchEval もどき” を作り始める - その上で、
- latent CoT などのコスト削減系
- token-level filtering 的な能力制御
に徐々に手を広げる
AI 研究者界隈は相変わらず派手なスコアとグラフを量産していますが、
開発者として本当に見るべきなのは、
「推論・安全・評価を、ちゃんとしたエンジニアリングプロセスに落とし込めているか?」
この一点です。
ぶっちゃけ、そこをやり切ったチームだけが、
「Deep Research AI うまく使えてる側」に残ると思っています。

コメント