
巨大なプロンプト1本で「設計も実装もレビューも全部やって」とLLMに丸投げして、
・途中で文脈を忘れられる
・ちょっと修正したいだけなのに、毎回最初から説明し直し
・どこで間違ったのかデバッグが地獄
…こういう経験、ありませんか?🤔
その「LLMに全部おまかせ設計」の限界を、かなり本気で壊しにきたリリースが出ました。
それが Claude Opus 4.6 と「Agent Team」 です。
一言で言うと:「LLM界の Kubernetes が来た」

今回のアップデートを一言で言うなら、
「1体のスーパーヒーローLLM」から「役割分担されたAIチーム + そのオーケストレーション」へのシフト
です。
技術的には:
- Claude Opus 4.6
- 推論・コーディング・長文コンテキストがかなり強化
- 独自ベンチマークでは GPT‑5.2 を 144ポイント差で上回ったと言われている(Elo的な複合指標)
-
最大 1Mトークン コンテキスト(ベータ)で、巨大コードベースや数百ページ級ドキュメントを一気に読める
-
Agent Team
- 「リサーチ担当」「設計担当」「実装担当」「QA担当」みたいな 複数エージェントを最初から前提にした仕組み
- それらをまとめて動かす “チーム” という一段上の抽象化 を、プラットフォーム側が公式に用意した
正直、この「Agent Team」を見た瞬間に、
「あ、LLMもついに Kubernetes みたいな“公式オーケストレーション層”を持ち始めたな」と感じました。
何がそんなに偉いの?:単なる「強いモデル」ではないポイント
「でかい・かしこい」だけじゃなく、「構造化された賢さ」に寄せてきた
Opus 4.6 はスペックだけ見ると分かりやすく強いです:
- 1Mトークンコンテキスト(ベータ)
- 出力最大128Kトークン
- ARC AGI 2 が 37.6% → 68.8% など、推論系ベンチマークが激伸び
- 独自指標では GPT‑5.2 を 144 Elo くらい上回る
でも今回の本質は、「LLMをどう使え」とプラットフォーム側が意図を示してきたことだと思っています。
今までは:
「強いLLMがあります。あとは LangChain なり自作フレームワークなりで勝手にエージェント構成組んでください」
だったのが、今回は:
「チーム前提で使ってね。そのための Agent Team も用意したから」
と、アーキテクチャまで込みのアップデートになっている。
この“使い方までセットで変えてくる”動きは、かなり大きいです。
Kubernetes 登場時の「暗黙のベストプラクティス」が思い出される
コンテナ黎明期を経験している人なら分かると思いますが、
Docker だけの時代って、みんなそれぞれ独自で:
- シェルスクリプトで無理やりオーケストレーション
- 自作スケジューラ
- 監視やロギングも全部手作り
みたいなカオス状態でした。
Kubernetes が出てきてからは、
- Pod / Deployment / Service / Ingress …という 公式の語彙と設計パターン
- 「こう分割するのが良いよね」という 暗黙のベストプラクティス
が一気に共有されましたよね。
今回の Agent Team は、それの LLM版の入り口に見えます。
- 「研究」「設計」「実装」「レビュー」という 役割の分解
- それらをつなぐ チーム構造 という語彙
- 「1つの巨大プロンプト」よりも「複数のシンプルなロール定義」の方が良い、という 公式メッセージ
正直、これは 「LLMの当たり前の使い方」を数年スキップで前に進める 可能性があります。
競合と比べて、どこが“ヤバい”のか
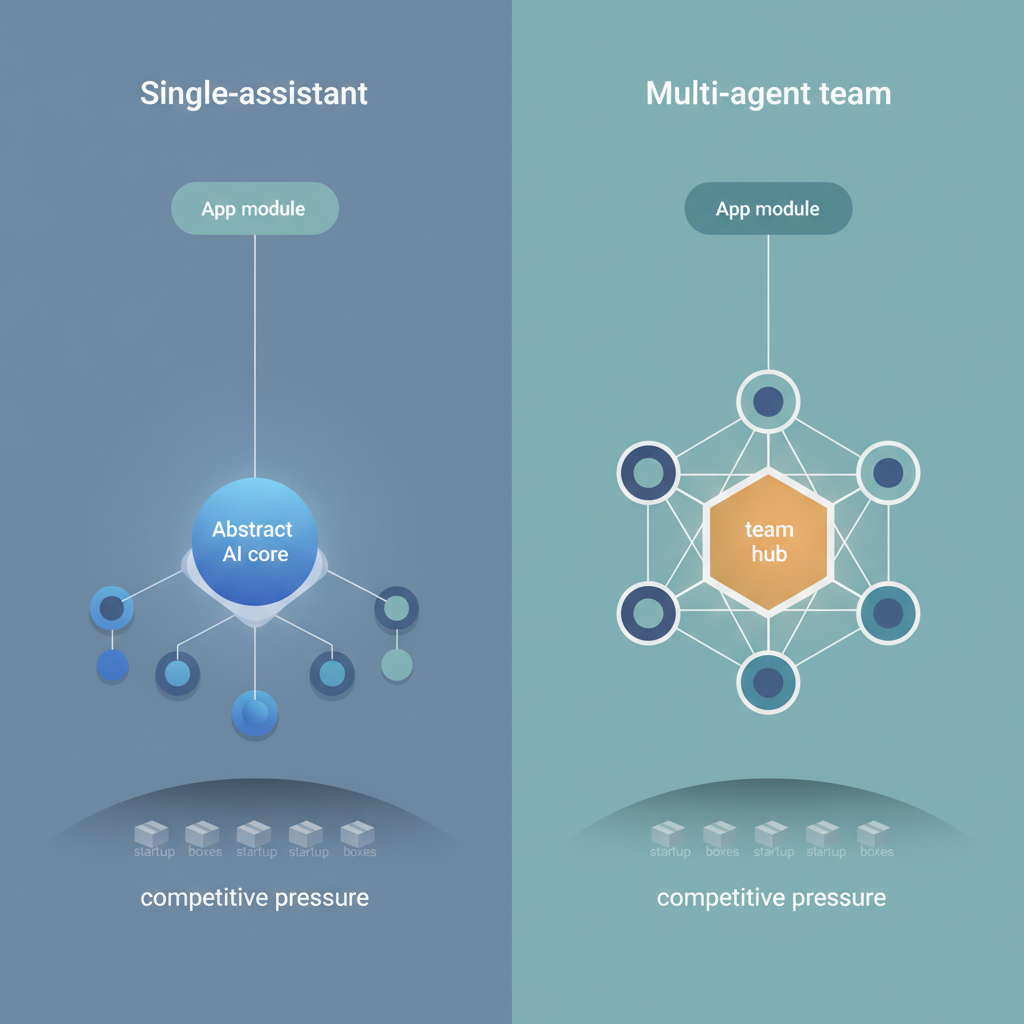
OpenAI との比較:Assistants API vs Agent Team
OpenAI ももちろんオーケストレーションに手を入れていて、
- Assistants API
- o3 みたいな推論特化モデル
- GPT‑5.3 Codex みたいなコーディング特化モデル
などを出してきています。
でも、構造の見せ方がかなり違う。
- OpenAI:
- 基本は 「1コンテキストに1 Assistant」 発想
- 複数エージェントや役割分担は アプリ側が実装 する前提
-
「チーム」というメタファーは、あくまでユーザ側の設計
-
Anthropic:
- プロダクトのど真ん中に 「Agent Team」 という概念を置く
- 「エージェントが複数いて当たり前」という発想をUI/概念レベルで押し出す
- マルチエージェント構成が“標準” というメッセージ
この差は、「単なる機能差」ではなく、どんなアプリを作ってほしいかのビジョンの違いです。
ぶっちゃけ、エージェントプラットフォームを作っているスタートアップはかなりプレッシャーを感じると思います。
- LangChain / LlamaIndex / crewAI などのフレームワーク勢
- 独自の「エージェントチームUI」を売りにしているSaaS
にとっては、
「え、トップティアLLMベンダーが、最初からマルチエージェント前提の一枚岩な堆栈を提供してくるの?」
という感じになる。
Google / 他OSS勢との距離
Google 側は Gemini + 自前ツール群で「全部入りプラットフォーム」を目指しつつありますが、
- オーケストレーションの抽象化は、まだ「開発者が自分で組む」路線が強い
- OSS界隈(AutoGen, CrewAI など)は頑張っているが、「どれがデファクトか」がまだ曖昧
そこに対して Anthropic は、
- 「1Mコンテキストで巨大文脈を一気に読む」
- 「Agent Teamで役割分担された対話」
という、コードヘビーなワークロード特化の2枚看板を出してきた。
「何でも屋のプラットフォーム」 vs 「開発ワークフロー直撃の特化路線」
という構図が、少しずつハッキリしてきたと感じます。
現場エンジニア目線での「本当のキラーフィーチャー」
1M トークンコンテキスト × Agent Team の組み合わせ
正直、1M トークンだけなら「すごいね」で終わりです。
でも、これが Agent Team と組み合わさると話が変わる。
典型的なシナリオ:
- Researcherエージェント
- リポジトリ丸ごと(数十万行) + 技術仕様書 + 過去のバグレポートを読み込む
-
「現状のアーキテクチャと問題点」を構造化して出す
-
Architectエージェント
- Researcherの成果物を元に、新アーキテクチャ案を作成
-
影響範囲、移行ステップ、リスクを列挙
-
Coderエージェント
- Architect の仕様を見て、該当モジュールを一つずつリファクタリング
-
変更点のサマリやマイグレーション手順を記述
-
QAエージェント
- 差分をレビュー
- テストケース自動生成
- 危険そうな変更箇所をフラグ
ここまでを 単一のLLMでやろうとすると、プロンプトが地獄なんですよね。
- 「あなたはフルスタックエンジニアでありアーキテクトでありQAであり…」
- 「まずリサーチして、その後で設計し、その後で…(中略)…最後にテストを書いてください」
結果:
- どのステップでミスが起きたか分からない
- 途中から指示がぶれる
- プロンプトを修正しても、どの部分がどこに効いているのかがブラックボックス
Agent Teamなら:
- 役割ごとに シンプルで読みやすいプロンプト を1つずつ持てる
- どのエージェントがしくじったのか ログで追いやすい
- 一部のロールだけ差し替えたり、A/Bテストしたりしやすい
これは、アプリケーションエンジニアリングの観点ではかなり大きな進歩です。
Adaptive Thinking(effort parameter)で「考えさせる量」を制御
Opus 4.6 から入った Adaptive Thinking も、地味に効いてきます。
effort = low:軽い質問にサクッと答える(チャットボット・補助ツール向き)effort = max:分散システムの設計やアルゴリズム設計など、本気の思考時間を割いてほしいとき
正直、この「どれだけ考えさせるか」を APIパラメータで制御できるのはかなり良い。
特に Agent Team だと、
- Researcher は
medium - Architect / QA は
max - Coder は
high
みたいな ロールごとの思考コスト配分 が設計できる。
「全部 max にしておけば安心」だと、コスト的に普通に死ねるので、このチューニングが 現実的な運用の鍵になりそうです。
ただ、懸念点もあります…😇
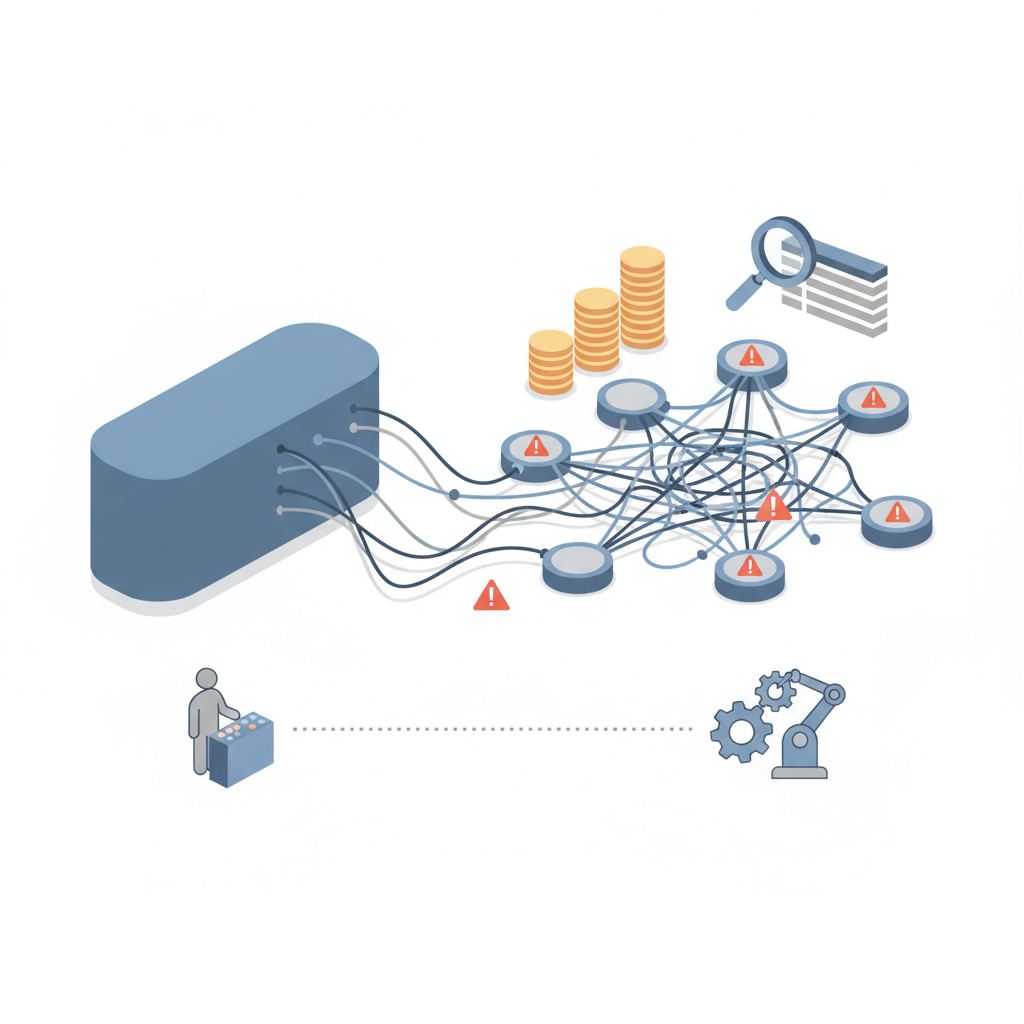
設計の複雑さは、普通に爆増する
正直、マルチエージェントは聞こえはカッコいいけど、設計工数は確実に増えます。
- 1つの巨大プロンプト → 4〜5個の役割プロンプト + チーム設計
- エージェント間のインターフェース(引き渡す情報の形式)を決める必要
- 「どこまでを人間がレビューして、どこからを自動化するか」という線引き
ここをちゃんとやらないと、ただの「AI版マイクロサービス地獄」 になります。
- 無意味にエージェントを増やしすぎる
- どのエージェントが何をしているのか誰も把握していない
- ログが膨大になって、障害時解析が地獄
ぶっちゃけ、「とりあえずカッコいいからチームにしてみた」は一番やってはいけない導入パターンだと思っています。
コストは“ほぼ確実に”跳ね上がる
Opus 4.6 の価格は(ざっくり):
- 通常コンテキスト:入力 $5 / 出力 $25 per 1M tokens
- 200K超コンテキスト:入力 $10 / 出力 $37.5 per 1M tokens(プレミアム)
これでエージェントを4体とか5体とか走らせると、素で単純計算4〜5倍です。
さらに:
- チーム内でのメッセージや中間サマリもトークンを食う
- 長時間のセッションだと、
Context Compactionで圧縮はされるものの、その要約にもコストはかかる
「人間の人件費と比べれば安い」とはよく言いますが、
“いい感じに雑に使う” と普通に請求書が炎上します🔥。
特にスタートアップや個人開発者にとっては、
- 「全部 Opus 4.6 + Agent Team」は贅沢構成
- 部分的に mini モデルや他社モデルと組み合わせる、みたいな コスト設計の余地 は依然として必要です。
ベンダーロックインはガチで深まる
Agent Team のような 高レベル抽象 ほど、ロックインが強くなります。
- エージェント構成・ロール定義・メッセージフォーマットが Anthropic 流儀に寄る
- 別ベンダー(OpenAI, Google, OSSモデル)に移行しようとしたとき、
- 「概念は同じだけど、APIも挙動も細かいところが全然違う」
- → オーケストレーション層をほぼ書き直し
正直、「Agent Team をど真ん中に据えたアーキテクチャ」 を組むのは、
中長期で Anthropic と心中する覚悟にそこそこ近いです。
エンタープライズならまだしも、初期フェーズのプロダクトでは、
- 「オーケストレーションは自前 or OSS、モデルは差し替え可能」
- 「本当に Agent Team 依存にするのは、1〜2クォーター試した後」
くらいの慎重さがあっても良いかな、と思います。
ベンチマークの「+144ポイント」を鵜呑みにすると危険
記事中では 「GPT‑5.2 を 144ポイント上回った」 という話が出てきますが、
- 独自複合ベンチマーク(Elo的な指標)
- 何をどの比率で混ぜたかは記事ベースの推定
- あなたのプロダクション負荷と必ずしも相関しない
という前提は忘れてはいけません。
「ベンチマークでは Opus 4.6 の方が強いけど、自社のRAGでは GPT 系の方が安定していた」
みたいなケースは普通に起こり得ます。
なので、
- 小さく A/B テストする
- 自社のタスクに近いベンチマークを自前で用意する
- 数値だけでなく、「振る舞い・デバッグしやすさ・チームが理解しやすいか」を見る
あたりは、引き続き重要です。
じゃあ、プロダクションで即採用するか?正直、こう見てます
エンジニアとして・プロダクト側として、今どう判断するかをまとめると:
Opus 4.6 自体は「試さない理由がない」
- 推論系ベンチマークの伸び方が素直にすごい
- コード生成・長文コンテキスト対応も、現場ユースケースに直結している
- 価格も「最上位モデルとしては」妥当なレンジ
なので、既に Claude 系を使っているなら、まずは一部フローを 4.6 に切り替えてみる価値はかなり高いです。
特に:
- 仕様書生成
- 既存コードのリファクタ提案
- 設計レビュー
- 複数PRの要約・リリースノート作成
あたりは、「人間のペアプロ相棒」としての精度を一度体感してみるべきレベルだと思います。
Agent Team は「すぐ本番導入」はおすすめしない(が、PoCは絶対やるべき)
正直に言うと:
「Agent Team をフル活用した構成を、いきなりプロダクションの中核に据える」のは、まだ様子見が妥当
だと考えています。
理由はここまで書いてきた通り:
- 設計が一段難しくなる
- コストが読みにくい
- ロックインが濃くなる
- まだリサーチプレビュー段階の機能も多い
一方で、
「PoCレベルで、本気のエージェントチームを1ユースケースだけ組んでみる」
のは、かなり強くおすすめします。
例えば:
- 大規模モノリスのリファクタリング支援
- テストコード自動生成 + 回帰テスト設計
- SRE向けの「インシデント分析チーム」(ログ解析 / 影響範囲特定 / ユーザ向けサマリ)
など、「今まで人間が複数人でやっていた知的作業」を、どこまでAIチームに寄せられるかを測るには絶好のタイミングです。
ここでの学びは、
- 「どこまでをAIに任せてよいか」
- 「どのロールはまだ人間に残すべきか」
- 「どの単位でレビューを挟むのが安全か」
といった、“AIと人間の役割分担” の具体的な形に直結します。
最後に:これからのエンジニアは「AIチームのマネージャー」になる

Opus 4.6 + Agent Team を見ていて一番感じたのは、
「エンジニアの仕事が、ますます“AIチームをどう設計し、どうマネージするか”に寄っていくな」ということです。
- 自分の手で全てコードを書く時間は確実に減る
- 代わりに、
- どんなエージェントを用意するか
- どういうインターフェースでつなぐか
- どこに人間レビューを入れるか
- 出力されたものの妥当性をどう検証するか
- そういった システム+ワークフロー設計能力 が、かなり重要になっていきます。
技術は勝手に進化しますが、
「どの程度まで任せるか」「どう組み合わせるか」 を決めるのは、結局人間側の仕事です。
ぶっちゃけ、今このタイミングで Opus 4.6 と Agent Team に触れておくかどうかで、
2〜3年後の「AIを使いこなしている開発者」か、「ツールに振り回される側」かが結構分かれる気がしています。
- まずは Opus 4.6 単体で既存ワークフローをどれだけ改善できるか試す
- その上で、Agent Team を1ユースケースだけ PoC して、AIチーム設計の感覚を掴む
この2ステップくらいから、冷静に始めてみるのがちょうど良い落としどころかな、というのが、今のところの私の結論です。🚀


コメント