
「AIのモデル選定、もう疲れました…」
そんなふうに感じたこと、ありませんか?
- 「GPT-4系は強いけど高いし、トークン請求書が怖い」
- 「ミドルクラスのモデルは安いけど、いざというとき信用できない」
- 「ルーターやエージェントで複数モデルを使い分けたら、システムがカオスになった」
こういう “コスト vs 品質 vs アーキテクチャ複雑度” の三すくみにハマっている開発チーム、多いと思います。
そんな中でリークされたのが、
「Claude Sonnet 5 “Fennec”」 です。
しかも出どころは、よりによって Vertex AI のエラーログ。
正直、エンジニア心をくすぐる登場の仕方ですよね。
一言で言うと:「Fennec」は Anthropic版 “React Hooks” になりうる

リーク情報をざっくり人間語に翻訳すると:
「Opus級の性能を、Sonnet級の価格でやってきた “かもしれない” モデル
という話です。
これはソース資料でも出ていましたが、
個人的に一番しっくりきた比喩がこれです👇
「Fennec は、Anthropic モデル陣営にとっての React Hooks かもしれない」
昔の React を思い出してください。
- クラスコンポーネント:
なんでもできるけど、重い・面倒・ボイラープレート地獄 - 関数コンポーネント:
軽いけど、できることが限られる
それが Hooks で一気に崩壊した。
「え、もう function コンポーネント一本でよくない?」
となった瞬間です。
今の LLM も、かなり似た構造になっています。
- Opus / GPT-4.x:
強い。けど高い、レイテンシも長い。 “クラスコンポーネント” 感。 - Sonnet / Gemini Pro / GPT-4.1-mini:
安いし軽い。けど、ギリギリの難問を投げるには不安。
ここに 「Fennec = Opus級性能 × Sonnet級コスト」 が本当に来るなら、
モデル選定の前提がかなり書き換わります。
ぶっちゃけ、「ミドルクラス1本でよくない?」の世界に近づく。
何がそんなにヤバいのか:コストだけじゃない
リーク記事や技術レポートを読む限り、「Fennec」まわりのポイントはざっくりこうです:
- 性能
- SWE-Bench で Opus 4.5 と同等〜やや上、という主張(※検証不能だが)
- コード生成・マルチファイル推論がかなり強いと言われている
- 長文コンテキストでの劣化が少ない、という証言
- 価格
- 「Opus の約 50% コスト」という噂
- 実際には 0.5〜0.7倍くらいのレンジの話が飛び交っている
- デプロイ面
- Vertex AI に 深く統合 されている(少なくともテスト段階で)
- GCP 前提の企業には導入障壁が一気に下がる
- 開発体験
- JSON/構造化出力の安定
- ツールコールが盛大に hallucinate しづらい
- 「エージェントっぽい」マルチステップ思考
ここで一番効いてくるのは、価格性能比 以上に、
アーキテクチャのシンプル化 だと感じています。
なぜ「Fennec」はアーキテクチャを変えうるのか
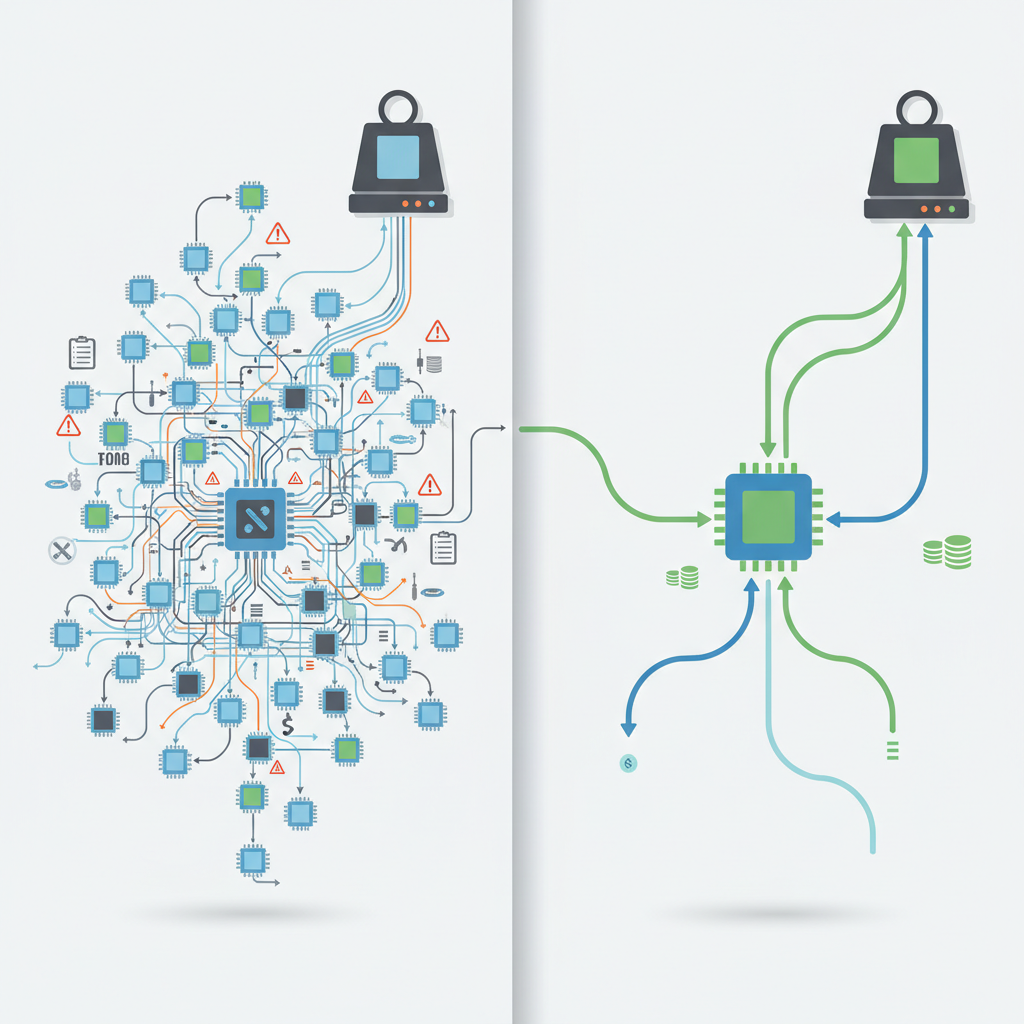
いま多くのプロダクトがやっていることは、だいたいこんな感じです:
- 軽量モデル(Gemini Flash / Sonnet / mini系)で
- ルーティング
- ざっくり要約
- 低リスク処理
- 重いモデル(Opus / GPT-4.x)で
- 最終回答
- 難易度高いコード生成
- クリティカルな推論タスク
つまり 「安いモデルでフィルタ → 高いモデルへエスカレーション」 という二段構え。
これ、本番運用してるとわかりますが:
- ルーターの評価・メンテが地味にキツい
- モデルを一個変えるだけでルーティング精度が狂う
- 各モデルの API 仕様・制約に足を取られる
正直言うと、
「ミドルクラスのモデルが、8〜9割のタスクを“十分高品質”に処理できるなら、
ルーターなんて全部捨てたい」
と思っているチームも多いはずです。
Fennec の噂どおりに
- 「Opus クラス」
- 「Sonnet に近い価格」
が実現するなら、選択肢はこう変わります:
- これまで:
- Sonnet:普段使い
- Opus:ここぞというとき
- Fennec 後:
- Fennec:デフォルト一択
- Opus:よほどヤバいタスク専用 or そもそも不要
つまり、「React Hooks 以降にクラスコンポーネントをほぼ書かなくなった」のと同じ現象が、
モデル階層 にも起こりうる。
この「ルーターいらないかも問題」は、
モデルルーティング系スタートアップにとっては普通に死活問題だと思っています。
「でも OpenAI / Google がいるじゃん?」という話
ここで冷静に、競合との立ち位置も整理しておきます。
OpenAI 側:GPT-4.1 / o3 系との比較
- 強み(OpenAI側)
- エコシステムの厚み:Assistants API, Realtime, fine-tuning, tools…
- SDK・ライブラリ・サンプルの量が段違い
- マルチモーダルも含めた “統合プラットフォーム” としての完成度
- Fennec 側が刺さるポイント
- コストパフォーマンス:
「日々の開発タスクやエージェント実行を全部 GPT-4.1 に投げるのはつらい」という組織への回答になりうる - 特に コード生成 × エンタープライズ:
GCP 上でコンプライアンスを取りつつ、Opus/GPT-4級のコードエージェントを回したい組織にはどんぴしゃ
正直、「絶対性能で GPT を完全にしのぐ」 というよりは、
「GCP 企業にとって、OpenAI をわざわざねじ込む理由が薄くなる」
というところが一番効くと思います。
Google 側:Gemini 1.5 Pro / 3.5「Snow Bunny」リークとの関係
よりややこしいのは、Fennec が Vertex AI 上で動いている という点です。
- GCP チームから見れば:
- 自社の Gemini 1.5 Pro / Flash と
- パートナーの Anthropic Claude
が同じプラットフォーム上で競合する構図になる - 噂レベルでは、同時期に Gemini 3.5「Snow Bunny」 なんてコードネームも出てきている
正直、ここはかなり面白い力学で、
- GCP 営業的には:「どっちを売っても GCP の売上には貢献する」
- 技術的には:「じゃあ素直に一番コスパいいやつを選べばいい」
という、ユーザーにとっては実はかなりおいしい状況 になります。
「Google Cloud 上で OpenAI 級のモデルを、Google 製か Anthropic 製か好きな方を選べる」
これ、数年前にはなかった風景です。
とはいえ、ぶっちゃけリークの信ぴょう性は「低〜中」です

ここまでワクワクする話を書いてきましたが、
現時点での Fennec 情報はかなり怪しい という点は、強調しておきたいです。
日本語の記事の検証でも指摘されていますが:
- 情報源は ほぼ単一の X(Twitter) 投稿
- SWE-Bench スコアは
- 80.9%
- 82.1%
- 82.3%
- 83.3%
と、発信元によってバラバラ - コンテキスト長も
- 「100万トークン」説
- 「128K」説
で矛盾 - 価格「50%安」は、明確な根拠のない “希望的推測” に近い
正直…
「AI 覚醒の特異点」「Opus 4.5 超え」とか煽りワードがつき始めた時点で、一回疑ったほうがいい
と思っています。
さらにまずいのは、Anthropic 公式が一切コメントしていない こと。
- モデルカードもない
- 安全性仕様も不明
- ベンチマークの正式発表もなし
- Vertex AI 側のリリースノートにも載っていない
エンプラ視点で言うと:
「1ツイート起点のリークモデルを、コンプライアンス部門にどう説明するのか」
というレベルの話です。
金融・医療・公共系なら、まずアウトでしょう。
「Fennec を本番で使うか?」という問いに、今どう答えるか
ここからは、Techリードとしての自分の結論です。
本番利用:正直、まだ様子見一択
理由はシンプルで:
- モデル ID・名前・挙動が GA 時点で変わる可能性が高い
- そもそもこの “Fennec” が、今後マーケ名として出てくる保証もない
- SLA / サポート / 価格が定まっていないものに、ビジネスを乗せるのはさすがにギャンブル
もし本番で使うなら、最低でも:
- Anthropic 公式ブログ or Vertex AI 公式ドキュメントで
- モデル名
- 価格
- 利用制限
- ベンチマーク
が明示されるのを待つべきだと思います。
検証・PoC:積極的に触る価値はある
逆に、PoC レベルなら話は別です。
- 今の Sonnet / Opus / GPT-4.x / Gemini 1.5 Pro で回している
- RAG パイプライン
- コードエージェント
- バッチ処理
-
これらに Fennec 相当のモデル を混ぜて、次を測るべきです:
-
コストあたりの成功タスク数
- 長文コンテキストでの精度劣化
- JSON/ツールコールの安定度
- レイテンシとスループット
ただし、やるなら設計をこうしておくべき だと考えます👇
- モデル ID は 設定ファイル or 環境変数 で差し替えられるようにする
- ルーティングロジックも 「このモデル前提」ではなく、「capability タグ前提」 で設計する
- 例:
supports_long_context = true,tier = "mid"みたいなメタ情報で選ぶ - 評価パイプラインを用意しておき、新モデルを A/B テストで流し込めるようにする
Fennec が GA で若干スペックダウンして出てきても、
あるいは名前が完全に変わっても、「モデル差し替えコストが低い状態」 を作っておくこと自体に価値があります。
個人的に一番気になっている「本当の killer feature」

リークの中で派手なのは、
- 「Opus 4.5 超えの SWE-Bench」
- 「コンテキスト 100万トークン」
- 「ゼロ・レイテンシ・シンキング」
- 「開発チームモード(サブエージェント生成)」
みたいなワードですが、
ぶっちゃけ、ここはかなり話半分で見ています。
正直なところ、
一番現実的で、かつ業界をじわっと変えうる “killer feature” はこれ だと思っています:
「Opus / GPT-4.1 クラスの思考力を、
デフォルト選択しても怖くない価格帯に落としてくること」
- コントラストは「100万トークン」でも「擬人化エージェント」でもなく
- 毎日の CI/CD パイプラインの中で
- 毎日の PR Review の裏側で
- 普通の B2B SaaS のチャットボットの中で
「いつの間にか、トップティア相当のモデルが “ふつうの選択肢” になっていた」
となることが、一番大きい。
React Hooks がすごかったのは、
- 「斬新なことができるようになった」からではなく、
- 「面倒くさいけど強力だったクラスコンポーネントを、ほぼ忘れてよくなった」から
だと思っています。
Fennec も同じで、
「強力な Opus / GPT-4 を、
特別扱いしなくていい日常のツールに変える」
という変化を起こせるかどうか、が本質だと感じます。
最後に:僕ならどう動くか
エンジニア/Techリードの立場として、
自分なら 今から半年くらいのプランをこう組む と思います。
- 短期(今〜1〜2ヶ月)
- Vertex AI を使えるなら:
- 既存ワークロード(コード生成・RAG・チャット)に対して
- 現行 Sonnet / Opus / GPT-4.1 / Gemini 1.5 Pro と
- 触れる範囲の「次世代 Sonnet 系」(Fennec 含む)
- を比較する検証ジョブを用意
-
本番トラフィックは 絶対に乗せない
-
中期(公式発表待ち)
- Anthropic 公式ブログ / Vertex AI リリースノートをウォッチ
- GA されたタイミングで:
- コストシミュレーション
- ルーティング設計のシンプル化(1モデル化)の検討
-
「モデル ID を差し替えるだけで切り替えられる」状態を整備
-
長期(1年スパン)
- もし本当に「ミドルクラス1本で8〜9割のタスクが回る」世界が来たら:
- 複雑なモデルルーティング・マルチモデル前提の設計は、技術的負債に転落 する可能性が高い
- そうなっても移行しやすいように、モデル依存ロジックをできるだけ薄く保つ
結論:
「Claude Sonnet 5 “Fennec” は、めちゃくちゃ面白いコンセプトだけど、
2026年2月時点では “リーク情報ベースでの設計変更はやめたほうがいい”」
- アーキテクチャの方向性を考える材料としては、最高のネタ。
- でも、請求書と SLA を背負うプロダクションに乗せるには、情報が足りなすぎる。
正直、ワクワクはしています。
でもエンジニアとしては、ワクワクと本番環境はちゃんと分けたい。
なので今できる一番賢い動きは、
- 「いつでも Fennec クラスのモデルに乗り換えられる柔軟な設計」を先に作っておくこと
だと考えています。
本当に “React Hooks 的転換点” になるのか。
それとも、単なる “Opus 4.5.1 的マイナーチェンジ” に落ち着くのか。
そこを見極めるまでは、
「PoC で触りまくるけど、本番は冷静」 くらいの距離感がちょうどいいかな、というのが今の正直なスタンスです。


コメント