
「LLMのレスポンス待ちで、UIが毎回“気まずい沈黙”になる」──そんな体験、ありませんか?
スピナーは回っているけど、ユーザーの集中はそこで一回途切れる。IDEのCopilot的な支援も、1〜2秒止まるだけで「自分で書いたほうが早いかも」と思われてしまう。
正直、ここしばらくのLLM界隈って「精度」ばかりが語られていて、「待ち時間」が真剣に扱われてこなかったんですよね。
そんな中で登場したのが、Google DeepMindの 「Nano Banana 2」 です。
結論(忙しい方向け)
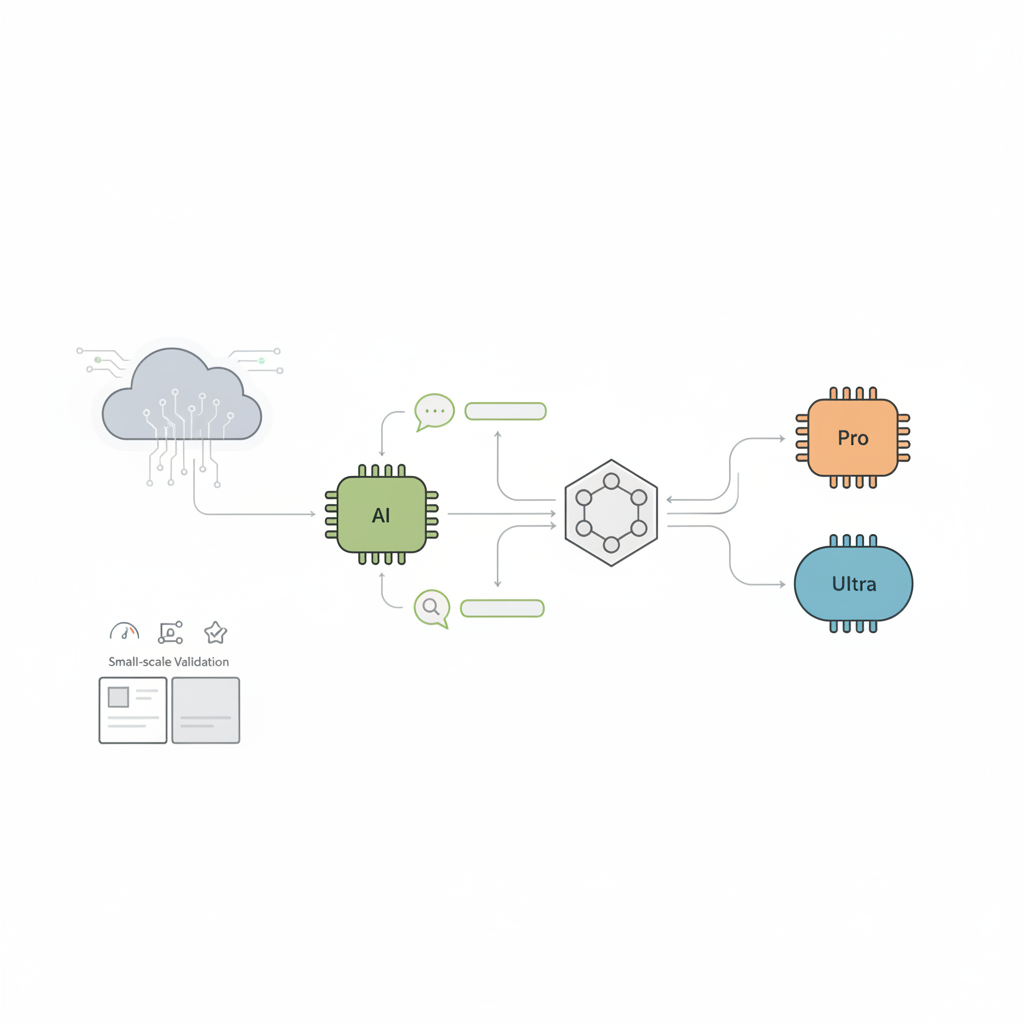
- Nano Banana 2は「一次受けモデル」として、チャットUI/インライン支援/高QPS要約のレイテンシ改善に効く。
- 設計のコツは「まずNano→失敗検知でProへ」のルーティングを前提に、評価と運用(ログ/品質/コスト)を最初から組むこと。
- 導入判断は、Googleスタック(Vertex AI/Android/Chrome)への寄せ方と、ロックイン許容度でほぼ決まる。
想定読者:プロダクト/開発リード、LLM機能を本番に組み込むエンジニア、SaaSのUXやコストを見ている人。
一言で言うと:「Node.js + V8」が出てきたときのJS界隈っぽい

一言で言うと、Nano Banana 2 は 「LLM界の Node.js + V8」 みたいな存在だと感じています。
- それまでの小さいモデル:
「簡単なスクリプトやチャットボット用だよね。真面目なことは Pro クラスに任せよう」 - Nano Banana 2:
「まあまあ本気の処理も、けっこうこれで回せるじゃん。しかも速いし安い」
かつて Node.js が「JavaScriptってブラウザのおもちゃでしょ?」と言われていた時代から、
「そこそこ高速で、スケールもできて、プロダクションのバックエンドも普通にイケる」 まで引き上げたのと、すごく似た匂いがあります。
Nano Banana 2 の設計思想はシンプルで、
- Pro級に「そこそこ近い」能力
- Nano級のレイテンシとコスト
このギャップを埋めに来ている。
ベンチマークで「SOTA達成!」というノリではなく、time-to-first-token とスループットに全振りしてきたのが今回のポイントです。
何がうれしいのか:ほとんどの“日常タスク”はこれで回せるかもしれない
個人的に「これは効く」と思っているのは、次の3パターンです。
チャットUIとインラインアシスタントの“標準エンジン”候補になる
- Webアプリ内のチャットヘルプ
- SaaSの右下にいるサポートボット
- プロダクト内の「AIに聞いてみる」ボタン
- IDE / エディタの簡易Copilot(関連:Copilotのモデル選択自由化)
これらの多くは、超高度な推論能力よりも、レスポンス速度と安定した挙動が重要です。
Nano Banana 2 はここにちょうど刺さるポジションで、
- v1よりも指示追従が改善されていて
- ツールコール(関数呼び出し)も以前よりまともで
- コーディングも「普段使いレベル」にはけっこう戦える
というバランス。
「最強ではないけど、9割のユースケースでは“十分に良い”」というゾーンを狙っているように見えます。
“まずは全部 Nano で投げて、ダメなら Pro にエスカレーション”という構成が現実解になる
ぶっちゃけ、今までは
- 小さいモデル:速いけど賢くない
- 大きいモデル:賢いけど遅くて高い
で、「小さいのでまず試して、ダメなら大きいのに投げ直す」という二段構えが、あまり現実的じゃなかったんですよね。
1回目で失敗する確率が高いと、結局「最初から Pro でよくない?」になりがちです。
Nano Banana 2 は、この「一次受けモデル」としての期待値が一気に上がった感じがします。
- 通常ルート:
nano-banana-2 - 難しそう / 失敗検知:
pro/ultraクラスへ
というルーティングを前提に設計しても、
「だいたい Nano で終わる」可能性が現実的なレンジに入ってきた。
これはシステム設計のパラダイムをじわじわ変えます。
高QPSワークロードで「コストとレイテンシの壁」が少し下がる
- 検索連動の要約
- 入力補完(メール、ドキュメント、フォーム)
- コードレビューのコメント生成
- FAQ自動生成
こういう「とにかく回数が多い」タスクに対して、Proモデルを使うと
「1リクエストあたりは安いけど、積み上がるとシャレにならない」問題が出やすい。
Nano Banana 2 は、ここを
- 単価を下げ
- レイテンシも減らし
- ある程度の品質を維持する
という、現場エンジニアが CFO と仲良くなれる方向に寄せてきています。
正直、こういう“地味に効くチューニング”のほうが、派手なベンチマーク結果よりありがたかったりします。
競合と比べると何が違うのか:Google vs OpenAI vs OSS

OpenAI の GPT-4o-mini / gpt-4.1-mini とどう違う?
ポジション的には、ほぼ真っ向勝負のレンジです。
- OpenAI mini系
- コストも安く、能力も高く、クラウド前提でとにかく「APIとして強い」
- OpenAIプラットフォームやChatGPTとの連携が魅力
- Nano Banana 2
- Googleのインフラ(TPU / Android / Chrome)と組み合わさると、レイテンシと一貫性で有利そう
- 将来的な オンデバイス展開(Android / Chrome) まで見据えた設計
開発者視点で正直に言うと:
- 既に OpenAI をメインにしているチーム:
わざわざ乗り換えるほどの決定的な差があるかは、まだ不明。
自分たちのワークロードでベンチを取るまでは様子見でいいと思います。 - GCP / Vertex AI / Android 依存度が高いチーム:
Nano Banana 2 を標準モデルにしておくと、全体設計がきれいに揃いやすい。
Android や Chrome での将来的なオンデバイス連携も含めて、長期的にはメリットが大きい。
Meta Llama 3.x 8B / 1B と比べると?
オープンモデル勢と比べると、Nano Banana 2 は
- 「自前デプロイの自由度」を捨てて
- 「Google のフルマネージド(最適化された推論スタック)」を選んでいる
という立ち位置です。
- Llama系:
- 自前ホスティングでカスタムしたい人向け。
- コストと制御性に強み。
- Nano Banana 2:
- 「インフラ周りを全部 Google に任せて、本番運用の細かい最適化まで含めて乗る」選択肢。
なので、Vertex AI / Google AI Studio 前提で構築するつもりがあるか? が一番の分かれ目です。
「どのみちGCPでやるし、Androidも視野にある」というチームにとっては、Llama より Nano Banana 2 に寄せるインセンティブは大きいと思います。
“Proみたいに使えるNano”の裏側にある懸念点
ここまで割とポジティブに書きましたが、正直、懸念点もそれなりにあります。
「Proライク ≠ Pro」なのをどこまで組織が理解できるか
マーケ的には「Proに近い能力を…」という表現が増えがちですが、
エンジニアとしては 「いや、それはさすがに言い過ぎでは?」 と感じる場面も出てくるはずです。
- 複雑なリファクタリング
- 長大なコンテキストをまたぐ推論
- 高度なマルチステッププランニング
このあたりは、やはり Pro / Ultra クラスが必要になるでしょう。
なのに、社内で
「Nano Banana 2 でだいたい Pro と同じって聞いたよ?全部それでいいじゃない」
という圧がかかると、現場がツラいことになります。
ここは技術リーダーがきちんと期待値コントロールするポイントです。
Google スタックへのロックインがかなり進む
ツールコール、ログ、監査、セーフティ、評価系…。
ここを素直に Google のスキーマやサービスに乗せていくと、将来のマルチクラウド戦略が一気に重くなります。
- モデルIDを差し替えるだけでは済まなくなる
- 安全設計 / ツール設計がプラットフォーム依存になる
- 将来「やっぱり Anthropic / OpenAI / OSS に変えたい」となった時の移行コストが高い
ぶっちゃけ、便利さと引き換えに「プラットフォーム債務」を負うイメージです。
個人的には、社内SDKやアダプタレイヤーを挟んで、モデル固有の仕様が外に漏れないようにすることを強くおすすめします。
NanoとProのハイブリッド運用は、地味に難しい
「普段は Nano、必要なときだけ Pro」という二段構えは合理的ですが、実装してみると意外と面倒です。
- どこで「Pro行き」にエスカレートするか(ルール設計)
- 同じタスクでも、NanoとProで返答のスタイルや粒度が変わる問題
- 評価・テストが 2モデル x 全フロー で必要になる
ここを雑にやると、「どこで何が起きているか誰も把握していないブラックボックスなAIシステム」が爆誕します。
正直、このあたりの運用設計コストは、あまりマーケ資料には書かれない部分です。
「安いからいっぱい使おう」の結果、トータルコストがむしろ上がるリスク
Nano Banana 2 はおそらくかなり安価に設定されるはずですが、
- 機能追加のたびに「とりあえずAIで何か出させよう」が増え
- ユーザー行動ログも「とりあえず全部LLM経由で整形しよう」になり
- バッチ処理や裏側のオーケストレーションでも使い倒す
と、最終的な請求額が「安くない」ラインに到達する可能性は普通にあります。
「単価が安い = 無限に使っていい」ではないので、
観測とコストガードレール(上限設定やアラート)は最初から組んでおいたほうが安全です。
オンデバイスはまだ“魔法”ではない
Android や Chrome 向けの「Nano展開」は確かに熱いですが、
- 端末スペックのバラツキ
- バッテリー持ち
- モデルのサイズと起動時間
を考えると、「クラウドと遜色ない魔法のローカルLLM体験」には、まだ距離があると思っています。
現時点では、
- コアな体験:クラウド推論(Nano Banana 2)
- 一部の補助機能やオフライン:オンデバイス
くらいの役割分担を想定しておくほうが、現実的です。
プロダクションで使うか?個人的な結論
正直に言うと、今の時点での自分のスタンスはこうです。
-
新規プロダクトで、GCP / Googleエコシステム前提なら
→ Nano Banana 2 を「デフォルトモデル」として採用する価値は十分あると思います。
特に、UIに埋め込むライトなアシスタントや、検索・補完系の機能にはかなりフィットしそうです。 -
既に OpenAI mini 系をしっかり使っているプロダクトなら
→ すぐに全面移行するほどの理由は、まだ見えていません。
まずはスモールスケールで比較検証して、
「自分たちのトラフィック+レイテンシ要件+品質要件」で優位があるかを確認してからでも遅くないはずです。 -
マルチモデル前提のアーキテクチャをちゃんと設計する気があるチームなら
→ Nano Banana 2 を「一次受けモデル」として据え、
Pro/Ultra へのエスカレーション戦略を組むのはかなりアリだと思います。
ただし、評価基盤とルーティングロジックは最初から設計しておく前提で。
導入判断チェックリスト(プロダクト目線)
- 体験:「待ち時間」がUX/離脱に効いているか(チャット、入力補完、検索要約など)。
- 品質:Nanoで失敗したときに検知してProへエスカレーションできる設計になっているか。
- 運用:2モデル運用のテスト/評価(回帰)を回す体制があるか。
- コスト:安さに釣られて呼び出し回数が増える「トータルコスト増」リスクを監視できるか。
- 戦略:Googleスタックへのロックインを、事業として許容できるか(SDK/アダプタで緩衝できるか)。
まとめると、
「プロダクションで“いきなり全面的に”使うか?
正直、まずは限定的な範囲での A/B テストとベンチマークからだと思っています。」
とはいえ、LLMの世界で“小さいのにちゃんと使える”モデルが出てきた意義はかなり大きいです。
JSが「ブラウザのおもちゃ」から「バックエンドの主役候補」に変わっていったように、
LLM も「巨大で重い Pro モデルが主役」という世界から、
「ほとんどの仕事は Nano で回し、難しいところだけ Pro に任せる」 世界にシフトしていく。その一歩目として、Nano Banana 2 はかなり象徴的なモデルだと感じています。
もし、今のあなたのスタック(クラウド、言語、典型的なワークロード)を教えてもらえれば、
「どこに Nano Banana 2 を挿すと一番コスパがいいか」をもう少し具体的に掘り下げてみます。
FAQ
Q. Nano Banana 2は「全部これでいい」モデル?
A. いいえ。一次受けとしては強い一方、複雑なリファクタリングや長い文脈の推論はPro/Ultraが必要になりやすいです。
Q. まずNano→Proへ切り替える判断はどう作る?
A. 失敗を「感覚」で判断せず、ツール実行失敗・制約違反・自己評価スコア・再試行回数などのシグナルをログに残し、ルールを段階的に育てるのが現実的です。
Q. どんなユースケースが相性良い?
A. 速度が価値になるチャットUI/インライン支援/高頻度要約・補完で、しかも出力の誤りを検知・吸収できるワークフローがあるものです。
Q. ロックインを抑える最小の工夫は?
A. 早い段階からモデル抽象化(アダプタ)を挟み、プロンプト/ツール仕様がベンダー固有に散らばらないようにするのが効きます。


コメント