
「マルチステップのエージェント作ったら、3ステップ目で急に話が迷子になる」
「RAG+ツール呼び出しを頑張って組んだのに、本番で動かすと謎行動連発」
……こういう経験、ありませんか?
LLMが「1回の回答」はそこそこ賢いのに、「ワークフロー」になった瞬間にポンコツ化する問題です。
そんな中で出てきたのが Google DeepMind「Gemini 3.1 Pro」。
これ、単なる「精度ちょっと上がりました」モデルじゃなくて、正直 「エージェント前提で設計された最初の実用モデル」 にかなり近いです。
一言でいうと:Gemini 3.1 Pro は「LLM界の React Hooks」だと思っている
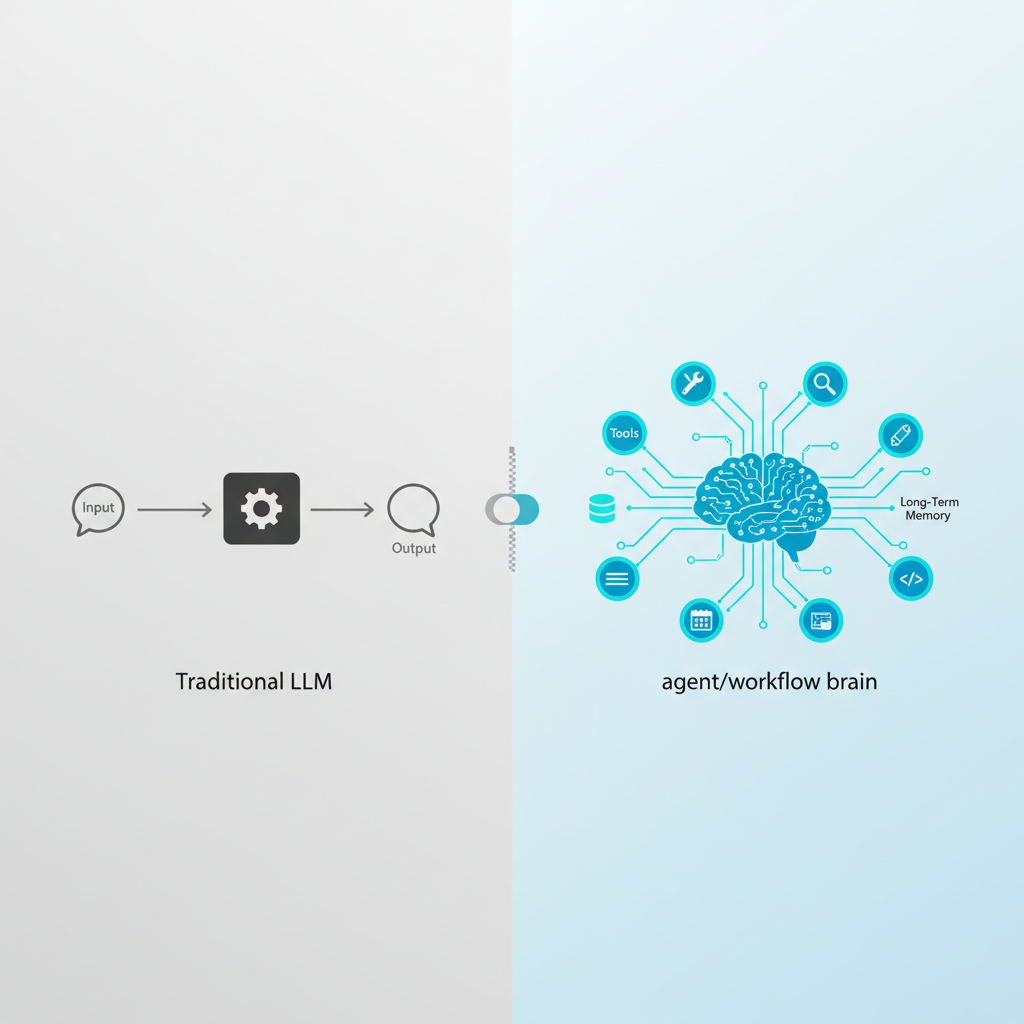
Google自身も「新しいフラグシップモデル」と言っていますが、開発者目線で一言でたとえるなら:
「Chatbot用のLLM」から「ワークフロー&エージェント用のLLM」へのスイッチを切ったモデル
にかなり近いです。
Reactが Hooks の登場で「ただのViewライブラリ」から「状態と副作用をちゃんと扱えるフレームワーク」に変わったのと似ています。
-
これまでの多くのLLM:
→ 「1プロンプト1レスポンス前提」の賢い関数 -
Gemini 3.1 Pro:
→ 「タスク分解・ツール呼び出し・長期コンテキスト前提」でチューニングされた “実務エージェントの脳みそ”
ぶっちゃけ、「プロンプト職人の人力サポート前提」から「モデル側でだいぶやってくれる」方向に一段階進んだ印象です。
何がそんなに違うのか:事実ベースで押さえておくポイント
ニュースの要点は他でも読めるので、ここでは開発者として「ここだけは押さえておけ」というポイントだけ絞ります。
推論性能が2〜2.5倍、ARC-AGI-2 77.1%
- 公式や日本語記事では「推論性能 2〜2.5倍」という表現が繰り返し出てきます。
- ARC-AGI-2で77.1% というスコア。今のところトップクラスの推論モデルと同じ土俵です。
正直、ベンチマークの数値そのものより大事なのは:
「マルチステップで壊れにくいかどうか」
で、3.1 Proに触った開発者の声やTRPG系の検証を見る限り、
「100ターン超えても破綻しにくい」「ツール連携を何度も繰り返しても筋が通る」という体感レベルの改善がかなり多いです。
「Pro」が本当にフラグシップになった
これまでのGeminiファミリーって、正直ポジションが分かりづらかったんですよね。
- Nano:オンデバイス
- Flash:軽量・高速
- Pro:中〜上位
- Ultra:一応最上位…
みたいな構図だったのが、3.1 Proでかなりハッキリしてきた:
「複雑なアプリを作るなら、とりあえず 3.1 Pro がデフォルト」
というメッセージに変わった。
Ultraは依然としてあるにせよ、
「実務で回すワークホースはPro」 という整理は、開発者にとってはかなりありがたいです。
モデル選定の悩みが1つ減るので。
エージェント/ツール利用前提のチューニング
公式・note・ZDNet系の記事を総合すると:
- 複数ツールの連続呼び出し
- コード実行とのループ
- 失敗時のリトライやプラン修正
といった「エージェント的ふるまい」がかなり強化されています。
APIの形自体はいつもの function calling ですが、
- ツール選択の精度
- 何度もツールを叩きながらゴールを目指す挙動
- 長い思考チェーンの保持
がかなり改善されている模様。
ここは実際に触った人の声とも一致していて、
「Google AI Studioで完全自己完結のコードを書かせても入出力のフォーマットが安定してる」
という報告が出ているのは、「道中の思考が迷子になりにくい」ことの裏返しだと思っています。
コスパがえぐい(と言われている)
日本語の記事ではかなりはっきり:
- 「推論性能 2倍以上」
- 「価格は競合の半額」
というフレーズが踊っています。
ここで言う「競合」はだいたい GPT‑4.1 / o3 / Claude 上位クラスを指していそうです。
もちろん正確な 1Kトークン単価は公式を見ないといけませんが、
もし本当に「高性能推論モデルとして半額クラス」なら、エンタープライズは一気に動きます。
これ、なぜそんなに重要なのか:GPT / Claude と比較して見える「役割の違い」

正直、今のLLM界隈は「どれが一番賢いか」より、「どのモデルをどの用途の主役にするか」のフェーズに入っています。
その観点で、Gemini 3.1 Pro をどう見るか。
OpenAI陣営との比較:GPT‑4.1 / o3 / GPT‑5クラス
OpenAI側はすでに:
- GPT‑4.1:汎用強モデル
- o1 / o3:推論特化モデル
- GPT‑5 / Deep Think 系:より高度な推論
というラインナップになりつつあります。
ここに対して Gemini 3.1 Pro が投げてきたのは:
「同クラスの推論性能を、より安く、Googleクラウド前提で提供します」
というストーリー。
企業目線で見ると:
- 既に GCP / Workspace を使っている
- BigQuery, Vertex AI, Docs, Sheets が仕事の中心
- あまりベンダーを増やしたくない
というケースでは、「多少の性能差があってもGeminiを選んだ方がトータルでは得」になり得ます。
逆に、OpenAI中心のスタックを組んでいるチームからすると、
- 「わざわざGeminiに乗り換えるほど、体感差 or コスト差があるか?」
- 「RAGやエージェントの仕組みをまるごと移植するコストを回収できるか?」
という計算が必要になります。
ぶっちゃけ、ここは 「思想」ではなく「エクセル」の世界です。
Anthropic(Claude 3.5 Sonnet / Opus)との比較
Anthropicは:
- 説明のわかりやすさ
- 指示追従の丁寧さ
- 文書理解の強さ
で評価されていて、「賢い同僚」的な立ち位置が強い。
一方、Gemini 3.1 Pro はどちらかというと:
「手足の生えたエンジニアリング・エージェント」寄り
に振ってきた印象があります。
- ツール呼び出しを繰り返しながらゴールに向かう
- 複数ステップの計画を自分で立てて進める
- 長いTRPGセッションでも世界観を保ち続ける
みたいな「自律行動」の部分にかなり投資している。
なので雑に言うと:
-
Gemini 3.1 Pro
→ 「複雑な業務フローを自動化したい」「マルチAPIオーケストレーションをやらせたい」 -
Claude 3.5 Sonnet
→ 「資料を読み込ませて要約・検討してほしい」「人間に近い説明力で議論したい」
といった棲み分けになりそうです。
本当のキラーフィーチャーは「エージェント耐性」と「Googleエコシステム内での一体感」
個人的に「ここが一番効いてくる」と思っているのは2つです。
「自律エージェント」を前提にした設計
記事でも「自律型パートナー」「自ら考える」というフレーズが繰り返されていますが、
これは単なるマーケ文句ではなくて、
- 長い思考チェーンでも破綻しにくい
- マルチツール呼び出しを前提にしている
- 多少のツールエラーも自分でリカバリしようとする
という「エージェントとして使ったときの歩留まり」をかなり意識していると感じます。
これまで、エージェント系フレームワークは、
- 「LLMがすぐ迷子になるから、手厚いプロンプト設計や制約で守る」
- 「タスク分解は外側のライブラリがやって、LLMは最後の一撃だけ」
みたいな発想が主流でした。
もし3.1 Proのエージェント性能が本物なら、
「外側のフレームワークを薄くして、モデル本人にもっと任せる」
という方向にシフトできる可能性があります。
これはアーキテクチャ的にかなり大きい変化です。
Google Cloud / Workspace / Android / Chrome への深い統合
もう1つのキラーフィーチャーは 「Googleの既存プロダクトに、最初から埋め込まれている」 こと。
- Vertex AI の標準モデルとして3.1 Pro
- Workspace(Gmail / Docs / Sheets)との連携
- NotebookLM、Geminiアプリ、Android、Chrome まで
「わざわざLLMを組み込む」のではなく、
「すでに使っているツールの中で、自然に3.1 Proが支えてくれる」 形になりつつあります。
これはエンジニアリングよりも、むしろ「組織的な導入コスト」を下げる意味でめちゃくちゃ効く。
- セキュリティレビュー
- 法務チェック
- 利用規約
- ユーザートレーニング
などを「Google製品でまとめて処理」できるのは、情シス/経営サイドには大きな説得材料です。
ただし、懸念点もかなりある…

ここまで褒め気味で書きましたが、ぶっちゃけ懸念点も多いです 🤔
「ベンチマーク番長」にならないか?
ARC-AGI-2 77.1%、推論2〜2.5倍。
数字としては美しいですが、現場エンジニアからすると大事なのはそこではなくて:
- 「JSONスキーマをどれだけ正確に守るか」
- 「長いRAGコンテキストでも変な捏造をしないか」
- 「APIチェーンの中で予期しない挙動をしないか」
といった 「地味だけど致命的なところ」 です。
Googleは歴史的に「論文とベンチマークは世界最強、プロダクトは惜しい」みたいな評価を受けがちで、
Gemini初期の品質問題もあって「おかえり、Gemini」という声が出るぐらいには信頼を落としていました。
3.1 Proはその「挽回版」という空気がありますが、
「ベンチでは強いけど、本番で使うと微妙」
にならないかどうかは、正直まだ見極め中です。
ベンダーロックインの罠
3.1 Proの真価を引き出そうとすると、どうしても:
- Vertex AI のエージェント的機能
- Google 独自の「Gems」テンプレート
- NotebookLM などの専用UI
に乗っかりたくなります。
ここで気をつけないといけないのは、
「Google前提で作り込みすぎると、将来 OpenAI / Anthropic / オープンモデル に乗り換えにくくなる」
という点です。
おすすめとしては:
- 自前 or 軽量フレームワークで LLMアクセスの抽象レイヤー を1枚作る
- プロンプトやツールスキーマをできるだけ ベンダーニュートラルな表現 にしておく
- ベンダー固有の機能(Gemsなど)は “UIの便利機能” として割り切る
ぐらいの距離感がちょうどいいと思います。
Googleの安全ポリシーの「厳しさ」
Google製のモデルは、安全ポリシーがかなり厳しめです。
- センシティブなトピック
- 一部の研究領域
- クリエイティブな「グレーゾーン」
などで、「これは出せません」「検閲的なフィルター」が挟まるケースは他社より多くなりがちです。
企業ユースではプラスですが、
クリエイターや研究者視点だと、
「同じプロンプトでもOpenAI / Anthropicの方が情報量が多い・切り込んだ議論ができる」
という場面は今後もありそうです。
プロダクションで即採用か?正直、まだ「A/Bテスト前提の様子見」が妥当だと思う
ここまでいろいろ書いてきましたが、自分だったらどうするか。
いきなり全面移行はしない
理由はシンプルで:
- まだ現場での「実戦レビュー」が十分溜まっていない
- 既存スタック(OpenAI / Anthropic)が安定して動いているなら、リスクを取る必要はない
からです。
とはいえ、無視するのももったいないレベル のアップデートなのも事実。
やるなら、まずはこの3つをA/Bテスト
もしあなたが既に何らかのLLMアプリを本番運用しているなら、
Gemini 3.1 Pro は以下の3領域でA/Bテストする価値があります。
- エージェント/ツール呼び出し系
- マルチAPIオーケストレーション
- コード生成+実行ループ
- データ収集→整形→レポート化の自動パイプライン
→ ここでの「歩留まり」「リカバリ力」が本当に高いなら、Gemini採用の理由になります。
- 長文コンテキスト+一貫性が重要なタスク
- TRPG/ゲーム的な長期対話
- 長いプロジェクトの要件管理・議事録要約
- 複数ドキュメントを跨いだ設計レビュー
→ 100ターン超えても破綻しにくいなら、運用コストがかなり下がります。
- コストがボトルネックになっている重い推論タスク
- 高頻度のバッチ推論
- 大量ドキュメントの一括処理
- エンドユーザー向けの高負荷SaaS
→ 本当に「同等精度で半額」なら、ここが一番インパクト大です。
その上で「どのモデルを主役にするか」を決める
最終的には、
-
OpenAI中心:
推論性能も大事だが、エコシステム・ツール群・ブランドの安心感を重視 -
Google中心(Gemini 3.1 Pro 主役):
GCP / Workspace 一体で進める。コストと社内導入のしやすさで勝負 -
Anthropic中心(+他をサブ):
「人間に近い説明力・安全性」を軸に据えつつ、他モデルをタスク別に併用
みたいな 「モデル戦略」 の話になります。
Gemini 3.1 Pro は、そのどの選択肢でも:
- 「メインで据えてもおかしくない」
- 「サブとしてでも置いておきたい」
レベルの選択肢には入ってきた、と感じています。
まとめ:Gemini 3.1 Pro は「無視はできないけど、盲信も危険」な転換点

整理すると:
-
単なるマイナーバージョンアップではない
→ 推論性能2〜2.5倍、ARC-AGI-2で77.1%と、明確に新世代 -
エージェント前提の設計に大きく舵を切った
→ マルチツール・長期思考・自律行動向き -
コスパが競合の「半額クラス」なら、特にGCP勢には強い選択肢
一方で、
- ベンチマークと実運用のギャップ
- Googleエコシステムへのロックイン
- 安全ポリシーの厳しさ
といった懸念もはっきり存在します。
なので、個人的な結論としては:
「プロダクションで全面採用」ではなく、
まずは重要フローで A/B テストして、“エージェント耐性” と “コスパ” を自分の目で確かめるフェーズ
が妥当だと思っています。
正直、今のLLM選定って「どのモデルが最強か」じゃなくて、
「自分たちのワークフローにとって、どのモデルを“主役”に据えるのが一番ラクか」
の話です。
Gemini 3.1 Pro は、その「主役オーディション」に本気で名乗りを上げてきた。
あとは、あなたの現場の評価軸でジャッジする番です。


コメント