
「このLLM、精度いいって聞いてたのに、プロダクションに出したら地味にウソついてくるんだけど…」
そんな経験、ありませんか?
- テストでは90%以上の精度
- ベンチマークもそこそこ優秀
- でも本番のユーザ問い合わせログを見たら、堂々とありもしない仕様を書く
ぶっちゃけ、今のLLMって「嘘をついてもコストが見えない」んですよね。
バグればSLOに跳ねるアプリと違って、LLMの「ちょっとしたウソ」はログの海に埋もれて、誰もきちんと負債として扱っていない。
そこに「量子統計関数ベースのAI監査プロトコル」という、かなり変化球な提案が出てきました。
今回はそのPart 2 的な議論を、エンジニア+ちょっと会計に首を突っ込んできた立場から、かなり主観強めで整理してみます。
一言でいうと「AI界のVaRを作ろうとしている」

このプロトコル、ざっくり翻訳すると:
「AIのウソ(ハルシネーション)を、物理っぽい統計モデルで測って、
それを会計・監査の世界にそのまま持ち込もう」
という話です。
もう少し噛み砕くと:
- 量子統計力学っぽい関数(エントロピー、分布の距離、準自由エネルギーみたいなもの)で
- 「この出力はどれくらい“真実分布”からズレているか?」
- 「このモデルはどの領域で“系として不安定”にウソをつきがちか?」
を数値化する - その数値を、会計の言葉にマッピングする
- 信頼度の低い出力は「情報の減損」=価値の毀損
- ハルシネーションが多い領域は「期待損失」=引当金みたいに「真実性リザーブ」を積む
- 結果として、
- エンジニアには「ハルシネーションリスクのメトリクス」
- CFO・監査人には「AIが生み出した無形資産の価値と、その減損リスク」
を同じ数式群から出したいというかなり野心的なフレームワークです。
アナロジーで言うと完全に「AI信頼性版 Value-at-Risk (VaR)」です。
金融がリスクを感覚値から統計モデルに引き上げたように、
AIの「嘘」と「価値」を、一つの数理レイヤーに載せてしまおうという発想。
正直、発想としてはかなり好きです。
でも、運用する側としては「いや待てよ…」と思うポイントもかなりある。
なにがそんなに新しいのか?機能というより「物差し」が新しい
「真偽」を0/1じゃなく「状態」として扱う
普通のガードレール系だと:
- これは事実か? → Yes/No(+確信度)
- Web cross-check して一致率でスコア
みたいな、わりと離散的な判定になりがちです。
一方、このQSFプロトコルは発想がかなり違う:
- モデルの出力を「高次元状態空間の一つの状態」とみなす
- その状態が
- 安定(過去データにしっかり支えられている領域)
- 不安定(データが薄く、モデルが“それっぽさ”で補正している領域)
のどちら側にいるかを、 - 分布の距離
- エントロピーの増加
なんかで測ろうとする
これって、「この回答は正しいか?」ではなく
「この回答が置かれている“情報のエネルギー地形”はどれくらい安定してるか?」
を測るイメージです。
VaR が「このポジションは明日いくらまで吹っ飛ぶ可能性があるか?」を統計的に出したのと同じノリ。
それを会計の言葉に変換する暴挙(褒めてる)
さらに面白いのは、これを「会計」にまで落としてる点。
- モデルが生成したレポートやコード、ナレッジを
→ AI生成の無形資産として扱う - 時間とともに
- 情報の陳腐化
- 後から発覚する誤り
に応じて
→ 減価償却・減損を記録する - QSFメトリクス的に「このドメインのハルシネーション率が高い」と分かれば
→ 「真実性リザーブ」を、貸倒引当金みたいに積む
ここまで行くと、ただの品質評価じゃなくて完全にバランスシートの話です。
エンジニアだけで完結できない世界に踏み込んでいる。
なぜこれが重要なのか?既存のガードレールとの一番の違い
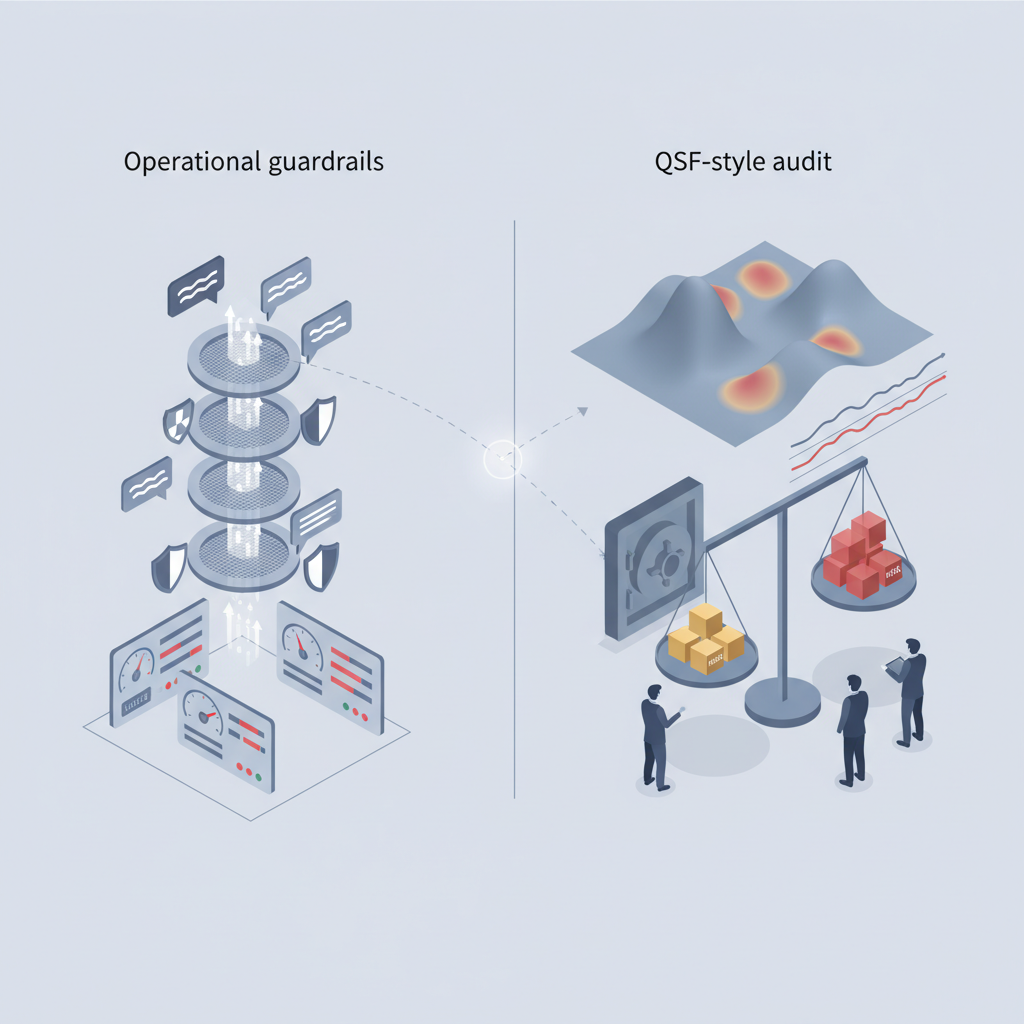
では、現状主流の「ガードレールSDK」「評価プラットフォーム」と何が違うのか。
いま主流のガードレールがやっていること
名前は出しませんが、代表的なガードレール系はだいたい:
- トキシック、ハラスメント、PII などのコンプラ違反検知
- ハルシネーションは
- Web検索とのクロスチェック
- 二次モデルでのファクトスコアリング
- メトリクスは
- エラー率
- 不適切率
- ユーザのthumbs up/down
- ダッシュボードで「だいたい安全です」「ここ危ないです」を可視化
つまり、オペレーションの安全と品質にフォーカスしています。
QSFベース監査が狙っているところ
対して今回のフレームワークは、もっと上の階層を狙っている:
- 物理インスパイアな統計モデルで
- モデルの「構造的なハルシネーション領域」を検知
- 長期的な分布の安定性を見る
- その上で
- CFO / CRO が理解できる
- 監査法人がサインできる
形に「価値」と「リスク」を翻訳する
ぶっちゃけ、
ガードレール = 「今このレスポンスはNGか?」
QSF = 「このAIシステム全体を、財務的にどう評価し、どれだけリスク資本を積むべきか?」
というレイヤー差があります。
だから既存ガードレールと「競合」というより、
ガバナンスの“北極星”を塗り替える提案なんですよね。
- いま:
→ 「有害レスポンスをブロックできるか」がKPI - QSFが普及した世界:
→ 「AI出力リスクを、財務的にどれだけ定量化できているか」がKPI
この発想に乗れないガードレールは、
長期的には「ただの下回りフィルタ」としてコモディティ化するリスクがある、というのが正直なところです。
正直ここがキモい(褒めポイント)
エンジニア目線で「これはやってもいいかも」と思うポイントを先に挙げておきます。
✅ 1. 「ハルシネーション = バグ」から「期待損失」にメンタルモデルが変わる
いま、ハルシネーションはどう扱われているかというと:
- 「まあLLMだし、多少はね」
- 「プロンプト工夫しましょう」
- 「必要ならhuman-in-the-loopを挟みましょう」
で終わりがち。
QSFフレームワークはこれを完全に金融の言葉に置き換えます:
- あるドメインXでのハルシネーション頻度 p
- そのドメインでの平均ビジネスインパクト L
→ 期待損失 = p × L
これを当たり前にダッシュボードで見られるようにする、という発想はかなり健全です。
正直、CFOに「LLMは時々ウソをつきますが、全体としては便利です」と言っても刺さらない。
でも「年間期待損失はこのくらいで、その分リザーブを積んでいます」と言えれば、ようやく会話になる。
✅ 2. 「生成」と「検証」を完全に分離する設計を促す
QSFを真面目にやろうとすると、どうしてもこうなります:
- LLMが回答を生成する(Generationレイヤ)
- QSFベースのバリデータが
- 参照分布との距離
- エントロピー
を計算し、「この回答の信頼度スコア」をつける - スコアに応じて
- 人間にエスカレーション
- 出力を抑制
- ユーザに「これは低信頼です」とラベルを出す
つまり2段構成がデフォルトになる。
この設計をプロダクトレベルで義務付けられると、
「LLMをそのままUIに直結しました」系の安直な実装は、監査的にNGになっていきます。
開発コストは上がるけど、これは長期的には良い圧力だと思っています。
✅ 3. 「ログ=技術メトリクス」から「ログ=監査証跡」へ
QSFに従うと、ログ要件がかなりシビアになります:
- プロンプト
- モデル出力
- 参照データの出典
- QSFメトリクス(分布距離、エントロピー等)
- それを元にした業務判断 or 人間の修正
ここまで全部揃って、ようやく「監査可能な履歴」になる。
これはエンジニアにはめんどくさいですが、
逆に言うと「ちゃんとしたMLOps/LLMOpsを整備するインセンティブ」になるとも言えます。
ただ、懸念点もあります…🤔

ここからはぶっちゃけモードです。
個人的に「これ、そのまま鵜呑みにすると危ないな」と思っている点。
❌ 1. 量子統計を“それっぽく”使う危険
量子統計力学は、正直かなりヘビーな分野です。
- エントロピー
- 分配関数
- 密度行列
などの概念を、用語だけ拝借して「量子っぽい評価指標です!」とやり始めると、
完全にカゴに入った猫を見て「シュレーディンガー」と言ってるだけみたいな世界になりがちです。
- 数式としてちゃんと意味があるのか?
- その指標が、本当に将来の誤りや損失と相関しているのか?
- 単なる「賢そうな数字」になっていないか?
ここを厳密にやらないと、
「量子」という言葉を付けたコンプライアンスシアターになる危険があります。
❌ 2. 「真実分布って誰が決めるの?」問題
QSFの前提には「参照となる“真実の分布”」があります。
- ゴールドデータ
- 外部データベース
- 人間アノテータの合意
などで作る想定ですが、
世の中の多くのドメインでは、そもそも地面が揺れている。
- 医療:ガイドラインは数年で変わる
- 法律:国ごとに解釈が違う、判例で揺れる
- 社会的トピック:そもそも「真実」が政治的
そうなると、「参照分布からのズレ」と言っても、
「どの権威にどれだけ従っているか」を測っているだけになる可能性が高い。
これは監査的には一見きれいですが、
技術的・倫理的にはかなりトリッキーです。
❌ 3. アジャイル開発とガチガチ監査の衝突
QSFフル実装を想像すると:
- 新しいプロンプト設計
- 新モデルの切り替え
- 新ドメインへの展開
のたびに、
- QSFパラメータのチューニング
- 参照分布の構築
- 監査向けドキュメント更新
が発生します。
正直、スタートアップや小規模プロダクトでこれをやると、
実験スピードがごっそり削られる懸念があります。
どこまでをQSFガチ運用のスコープに入れて、
どこからは「ライト版モニタリングで十分」と割り切るのか、
その線引きがないと、組織全体が「AIやるのやめようぜ」ムードになりかねない。
❌ 4. 過度な「財務化」の危険
すべてのAI出力を
- 無形資産
- 期待損失
- リザーブ
という枠に押し込めようとすると、
シンプルなユースケースまで金融プロダクトみたいな重さになってしまう懸念があります。
- 社内FAQボット
- ちょっとしたドキュメント要約
- デバッグ時の補助コード生成
まで、全部「貸借対照表の話」にするのはさすがにやりすぎです。
「どのリスクレベルからQSFフル装備を要求するのか?」
ここを決めないまま導入を進めると、オーバーエンジニアリング地獄に陥る気がしています。
❌ 5. 標準化されるまでのカオスとロックイン
歴史的に、VaRもそうでしたが、
一つのリスクメトリクスが“事実上の規制標準”になると、そこから抜けるのが地獄です。
- そのメトリクス前提で
- システム
- プロセス
- レポーティング
を全部組んでしまう - 後から「やっぱり別の指標の方がよかった」と気づいても、簡単には変えられない
QSFも、もしどこかの大手ベンダ or 規制当局が特定の実装を推し始めると、
その瞬間に巨大なロックイン装置になります。
標準がない初期フェーズでは、
似たようで互換性のない「量子インスパイア評価フレームワーク」が乱立する可能性も高く、
現場としては「どれ選べばいいの?」状態になりそうです。
じゃあプロダクションで使うか?正直、まだ様子見です
エンジニア+プロダクト側の立場から、現時点での結論を書いておきます。
🎯 いますぐ取り入れてもいいと思う部分
- 「ハルシネーションを期待損失として扱う」メンタルモデル
- 「生成」と「検証」を分離する2レイヤ設計
- ドメインごとに
- 参照データ
- リスク許容度
を定義しておく発想
これらはQSFの看板がなくても、今すぐ自前でやるべきだと思います。
- 単純な確率モデルでもいいので、
「このドメイン、このユースケース、このモデル構成での期待損失」をざっくり計算してみる - それをCFO or 事業責任者と共有する文化を作る
ここは取り入れて損はない。
⏳ 一方で「量子統計ガチ導入」は、正直まだ様子見
- 量子統計の形でやる必然性がどこまであるのか?
- 単純なベイズモデルや既存の不確実性推定で代替できないのか?
- 将来の規制や監査実務が、この路線を本当に採用するのか?
このあたりがまだ霧の中です。
個人的な戦略としては:
- まずは
- ハルシネーション確率
- ビジネスインパクト
の「期待損失」を、自前の統計でざっくり回し始める - ログとプロセスを
- 監査に耐えうる粒度
- エンジニアが運用できる負荷
の中間あたりまで整えていく - そのうえで
- 規制動向
- ベンダーロードマップ
を見ながら、「QSF的な物理インスパイアモデル」を採用するか検討する
くらいが現実的かなと思っています。
最後に:これからのAIエンジニアは「物理と会計の間」に立つ

このプロトコルの面白いところは、
エンジニア/データサイエンティスト/会計・監査の世界を、
強制的に一つの数理レイヤーで結ぼうとしている点です。
- 物理インスパイアな統計で「系としてのAI」を理解する
- その指標を、そのまま「企業価値」と「リスク」の言葉に変換する
正直、「そこまでやる?」という気持ちもありますが、
LLMがインフラ化していく世界では、いずれ避けて通れない方向性だとも感じます。
これからのAIエンジニアには:
- ロスや精度だけでなく
- 「このモデルの嘘が、BSとPLにどう効くか?」
までセットで語れるスキルセットが求められるかもしれません。
QSFはそのための一つの極端なプロトタイプとして、
今のうちから「どこが筋が良くて、どこがやりすぎか?」を見極めておく価値は、間違いなくあると思います。


コメント