
「問い合わせは増えるのに、モデル代は減らせと言われる」「RAGのためにLLMを何回も叩くから、気づいたら請求書がとんでもない額になっていた」——そんな経験、ありませんか?
正直、ここ1〜2年で一番キツいのは「性能」より「単価とスループット」の方だと思います。
そんな文脈で出てきたのが、今回の Gemini 3.1 Flash‑Lite です。
結論(忙しい方向け)
- Flash‑Liteは「RAG/ツール呼び出し/分類・ルーティング」など高頻度ステップの原価を下げるタイプ。スループット/TTFT(初回トークンまで)の改善とセットで効きます。
- 全面置き換えより「フロント(解釈・検索)→上位モデルへエスカレーション」の二段構えが安全です。
- まずは社内FAQ/問い合わせ分類/ログ要約のような短文・高頻度ワークロードで、$ / req・遅延・エスカレーション率を計測して適用範囲を決めるのがおすすめ。
想定読者:RAGやエージェントを本番運用していて、コスト/スループット/レイテンシで悩むエンジニア・PM。
関連:Gemini 3.1 Pro(上位モデルの位置づけ) / ChromeのGemini統合(運用・ポリシー観点)
一言で言うと「t3.micro が来た」:Gemini界のマイクロインスタンス

一言で言えば、Gemini 3.1 Flash‑Lite は 「Gemini界の t3.micro」 です。
- 旧来の Flash が「m5.large 的な汎用・安価モデル」
- 新しい Flash‑Lite は「とにかく数をさばくためのマイクロインスタンス」
というポジション。
技術的には:
- モデル名:
gemini-3.1-flash-lite-preview - 価格(標準・有料枠)
- 入力:100万トークンあたり $0.25(テキスト/画像/動画)
- 出力:100万トークンあたり $1.50
- 役割:
- RAG、ツール/関数呼び出し、エージェントのプランナー/ルーター向け
- 長文クリエイティブや巨大コンテキストはあえて切り捨て
npakaさんのまとめにもある通り、Artificial Analysisのベンチだと 2.5 Flash より速くて、品質も同等以上。
「高性能モデルを安くしました」というより、
「最初から“エージェントの脳+RAGのフロントエンド”に振り切ったモデル」
という方がしっくりきます。
これ、なぜ重要か:Googleは「エージェントの脳」を取りに来ている
正直、今回一番おもしろいのは 「どこを取りに来ているか」 です。
汎用アシスタントではなく「エージェントの中枢」を狙っている
OpenAI の gpt‑4o‑mini / 4.1‑mini は、
- 安い
- そこそこ書ける
- そこそこツールも呼べる
いわば「小さめの総合アシスタント」という立ち位置です。
一方で Gemini 3.1 Flash‑Lite のメッセージはかなり明確で、
- ツールコール
- RAGループ
- プランニング/ルーティング
に「最適化した」と言い切っている。
npakaさんの表現を借りれば 「ルーター / ブレイン for retrieval」 であって、「なんでも書く作家モデル」ではない。
ぶっちゃけると、Googleは 「アプリの中に埋め込まれる無数の小さな脳」 を丸ごと取りに来ている印象です。
コスト構造を変える:常時稼働エージェントを「現実的」にする価格帯
価格表を眺めていて、個人的に一番「おっ」となったのがここです:
- 3.1 Flash:入力 $0.50 / 出力 $3.00(100万トークンあたり)
- 3.1 Flash‑Lite:入力 $0.25 / 出力 $1.50
つまり、ほぼきれいに「半額」クラス。
しかも npaka さんの記事だと、
- 2.5 Flash 比で
- 最初のトークンまで 2.5倍速い
- 出力速度 +45%
となっている。
常時動いているエージェント(問い合わせ解析 → 検索 → 整形 → 必要なら別モデル呼び出し)を構成する「1ステップあたりの原価」が、かなり現実的なラインまで落ちてきました。
- 社内FAQボット
- ログ監視+異常検知→サマリ
- エンドユーザーごとにカスタムされたダッシュボード説明
みたいに、「1ユーザーあたり毎日数十〜数百クエリ飛ぶ」ようなワークロードは、Flash‑Lite クラスがないとビジネスとしてかなり厳しい。
そういう意味で、今回のリリースは 「やっと来たか」という感じがあります。
Googleスタックにいるなら、わざわざ他社の「小さいモデル」を探さなくてよくなる
これも地味に効きます。
今までは、
- 大きい推論は Gemini / Vertex AI を使う
- ルーティングや分類、軽めRAGは他社のミニモデル or ローカルモデル
みたいな「二刀流」構成を取っているチームも多かったはずです。
Flash‑Lite がこのポジションを取りに来ることで、
- GCP / Vertex AI に乗っている組織は
- ネットワークレイテンシ
- 権限・監査
- 請求書の分散
を気にせず、全部 Google 内で完結できる。
競合視点で言えば、
「ルーター専用の小型モデル」「安いエージェント向けモデル」だけを武器にしているベンダーは、かなりプレッシャーを感じるはずです。
とはいえ、懸念もある:安くて速いけど「これ1本運用」は危険
ここからは、ぶっちゃけ懸念ポイントです。
モデル能力の天井は、あくまで「ライト」
公式がやんわり言っているように、Flash‑Lite は:
- 長大コンテキスト
- 複雑なマルチモーダル(画像・動画ゴリゴリ)
- クリエイティブ長文生成
には向いていません。
なので「既存の 3.1 Flash / Pro を全部 Flash‑Lite に切り替えたらコスト半額では?」は、ほぼ確実に失敗します。
- FAQボットなのに、クレーム対応のニュアンスが急に雑になる
- 仕様が複数ドキュメントに跨るような質問に、途端に弱くなる
- マルチモーダルを前提にしていたUIレビュー系ワークフローが微妙になる
といった、「にぶい劣化」が起きる可能性が高い。
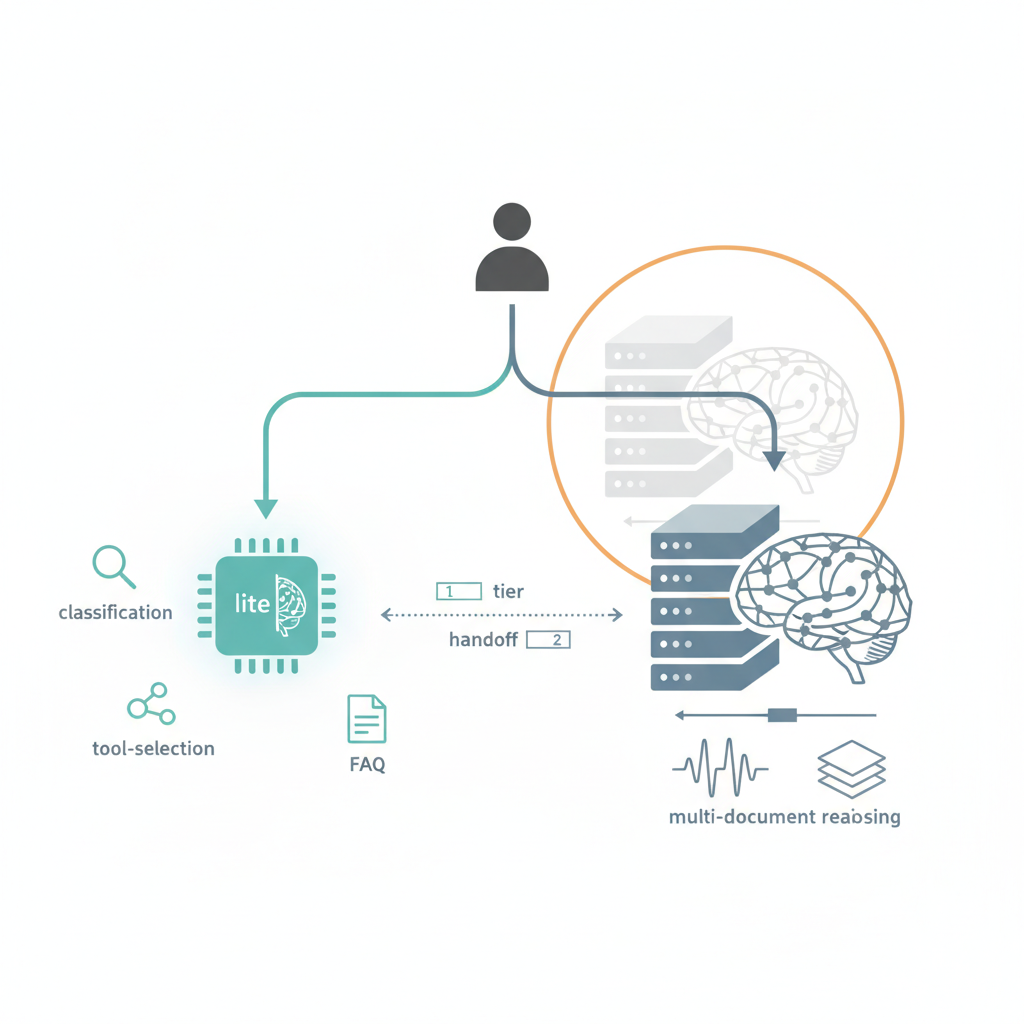
Flash‑Lite は、
- プランナー / ルーター / RAGのフロント
- シンプルなQ&A・翻訳・モデレーション
に絞って使い、
そこから 3.1 Flash / 3.1 Pro にバトンを渡す構成を組める人向けのモデル だと見た方が安全です。
システム構成が一段複雑になる
Flash‑Lite をちゃんと活かそうとすると、どうしてもこうなります:
- Flash‑Lite:ユーザ入力の解釈+ツール選択+必要ならルーティング
- ツール類:検索、DB、社内API、監査ログなど
- 必要に応じて Flash / Pro:長文生成や高度な推論を担当
つまり、
「1モデルで何でもやるチャットボット」から、「マルチモデル+ツール前提のエージェントアーキテクチャ」へ シフトせざるを得ない。
これ自体は良い流れですが、現場エンジニア的には:
- メトリクスが増える(どのステップが遅い/高いのか追う必要)
- フォールバック設計が必要(ツールが死んだら?Proが失敗したら?)
- モニタリングとテストのパターンも増える
という「運用疲れ」が確実にやって来ます。
正直、ここをちゃんとやれるチームと、そうでないチームで Flash‑Lite の体験差がかなり出るはずです。
ベンダーロックインの圧が強まる
Flash‑Lite 自体は API も普通の Gemini モデルと同じで、表面上はポータブルです。
ただし実際には、
- Google 検索グラウンディング
- Vertex AI のコネクタ
- Google流のツール定義・構造化出力
に乗せれば乗せるほど、「別クラウド+別ベンダーに引っ越し」が重くなっていきます。
「とりあえず安いし、RAGも便利そうだから全部 Vertex に寄せよう」は、
2年後3年後に「他がもっと良くなったけど動けない」という未来にもつながりかねません。
個人的には、
- 重要なビジネスロジックやツールI/Fは
- なるべく自前のサービス境界で閉じる
- モデルに依存する部分(プロンプト設計など)は
- 抽象レイヤーを決めておく
くらいは設計段階で意識した方がいいと感じています。
「安さ」に釣られてオーケストレーション過多になるリスク
もう1つの落とし穴は、「安いからいっぱい叩いて良いでしょ?」問題です。
- Flash‑Lite 1コールは確かに安い
- でも、
- 1ユーザー操作あたり
- ルーティング
- 2〜3回のRAG
- サブエージェントの起動
- 最後に Pro でまとめ
みたいな構成にすると、平気でトークン4〜5倍になります。
「面白いからとりあえずエージェントを重ねる」設計は、
Flash‑Lite になってもやはり危険です。
- どこまでを Flash‑Lite で即答させるか
- どの条件でだけ Pro/Flash にエスカレーションするか
- どこでツール呼び出しを打ち止めにするか
を はっきり線引きする設計力 が必要になります。
競合との比較から見える「Gemini側の戦略」
OpenAI の mini 系との違い
ざっくり整理すると、こんな棲み分けに見えます:
- OpenAI(gpt‑4o‑mini / 4.1‑mini)
- 「十分に賢くて、それ1本でも中小規模のアプリなら回せる」路線
- マルチモーダルもある程度こなす
-
Assistants API でエージェントもできるが、「汎用アシスタント」が主役
-
Gemini 3.1 Flash‑Lite
- 「エージェントの“脳”として振り切る」路線
- 自らはそこまで書かない想定(長文は上位モデルに委譲)
- Google Cloud / Vertex AI エコシステムにどっぷり最適化
つまり、
「小さい1人の優秀アシスタント」 vs 「無数の小さな脳が連携するエージェント群」
という思想の違いが濃くなってきました。
既に GCP に乗っている企業なら、
- ログも BigQuery、アプリもGKE or Cloud Run、アイデンティティもGoogle系
という構成が多いので、
そこに Flash‑Lite を「標準のエージェント脳」として挿すのは、かなり筋が良い選択肢に見えます。
逆に、AWS / Azure / OpenAI でがっつり組んでいる組織は、
- わざわざエコシステムを増やすほどの差が本当にあるか?
を、PoC でシビアに見ることになるでしょう。
では、プロダクション投入するか?正直「段階的な様子見」が現実解
最後に、エンジニア目線での「結論」に近い話です。
いきなり全面移行はおすすめしない
正直なところ、
- 今動いている 3.1 Flash / 2.5 Flash ベースのプロダクションを
- そのまま Flash‑Lite に差し替える
のは、かなり危険だと思っています。
- 回答のニュアンスやリッチさの劣化
- 長文問い合わせの品質低下
- マルチモーダルワークフローの破綻
が「じわじわ」効いてきて、半年後にNPSだけ下がっている、みたいなパターンが一番怖い。
現実的な落としどころ:まずは「脳の一部」を任せる
個人的におすすめしたいのは、このあたりの使い方です:
- 新規 or 既存ワークフローのうち、
- 「問い合わせの分類」
- 「どのツールを呼ぶかの選択」
- 「RAGのクエリリライト」
-
「簡易なFAQ回答」
だけを Flash‑Lite に置き換えてみる -
その上で、
- 一定長以上の回答
- 複数ドキュメントをまたぐ推論
- UX的に重要な「見せ文章」の生成
は引き続き 3.1 Flash / Pro に任せる
この「二段構え」がちゃんとハマるなら、そこで初めて:
- どの部分をさらに Flash‑Lite に寄せられるか
- どこは逆に Flash / Pro に戻した方が良いか
をチューニングしていくイメージです。
結論:エージェントを「本気でやる」チームには、かなり強い武器
プロダクションでいきなり全面採用するかと言われれば、
「正直まだ様子見。ただし、エージェント前提の新規開発なら最初から選択肢に入れる」
というのが今のスタンスです。
- 高頻度RAG/ツール呼び出しが中心
- Google Cloud / Vertex AI に既に乗っている
- マルチモデル・ツール前提のアーキテクチャを組む覚悟がある
この3つの条件が揃っているチームにとって、
Gemini 3.1 Flash‑Lite は 「ようやく来た、現実的なエージェント用の脳」 だと感じています。
逆に、
- 1モデルでサクッとチャットボットを作りたい
- ベンダーを増やしたくない
- マルチモデル設計までは今は踏み込みたくない
のであれば、
今すぐ無理に飛びつく必要はなく、「どんなアーキテクチャ事例が出てくるか」を観察しながら、落ち着いて検証環境で触ってみるくらいがちょうどいいと思います。
「モデルのIQ競争」から「インフラとしてのエージェント競争」へ。
今回の Flash‑Lite リリースは、そのスイッチがはっきり入った瞬間の1つだと感じています。
FAQ:導入前に出やすい質問
Flash‑Liteだけで本番チャットボットを回せる?
おすすめしません。短文・高頻度の処理(分類/検索クエリ整形/ルーティング)を担わせ、長文生成や複雑推論はFlash/Proへ段階的に渡す設計が安全です。
どんなタスクに向く?
RAGの入口(クエリリライト/検索結果の軽い整形)、ツール選択、分類、簡易Q&A、モデレーションなど「速く・安く・数をさばく」工程に向きます。
上位モデルに切り替える条件は?
回答が一定長を超える/根拠整理が必要/複数ドキュメントを横断/マルチモーダルが重い、などのときは早めに上位モデルへエスカレーションするルールを持つと事故が減ります。
まず見るべきKPIは?
$ / req、TTFT、成功率(自己評価ではなく実タスクの正答/解決率)、エスカレーション率、そして「ツール呼び出し回数の増え過ぎ」を見るのが実務的です。


コメント