
「社内オペレーションを自動化したいのに、肝心のSaaSにまともなAPIがない」
「RPAでブラウザ操作を書いたはいいけど、UIがちょっと変わるたびにスクリプトが死ぬ」
こういう経験、エンジニアなら一度はあると思います。
正直、ぼくも「人間に手順書を渡した方がまだ安定するんじゃないか…」と感じたことが何度もあります。
そんなところに出てきたのが、GPT-5.4の Computer Use API です。
実際に動かした技術レポートを読んで、「あ、これは“また一段階フェーズが変わったな”」と感じました。
この記事はニュースの紹介ではなく、「これを本気で使うと開発現場はどう変わるのか?」を、エンジニア目線で整理してみます。
結論(忙しい人向け)
- Computer Useは「API連携の外側」を自動化するレイヤー:ノーAPI業務の“最後の砦”になり得る
- 最初は「狭い業務 + 人間承認」から:送信/確定操作は承認、ログと上限(クリック回数など)を必須に
- 最大のハマりどころはコストと非決定性:全部任せず、スクリプト/RPAとのハイブリッドが現実解
想定読者:RPA/業務自動化を検討しているエンジニア、情シス、プロダクト/オペ責任者。
一言でいうと:「Docker が出てきた時の RPA 版」
一言でいうと、GPT-5.4 Computer Use は 「Selenium に人間のQAエンジニアが乗り移ったもの」 です。
- これまでは
- LLM → tool-calling → REST API
- これからは
- LLM → Computer Use → ブラウザやデスクトップそのものを操作
というレイヤーが増えました。
Docker が出てきたとき、
「サーバーの個別設定を覚える」のではなく、「環境をコードで記述する」という発想にシフトしましたよね。
同じように Computer Use は、
「各SaaSのAPI仕様を読み込んで統合する」から
「LLMにUI操作のゴールと制約を渡して、あとは任せる」
に、頭の使い方を変えさせにきています。
正直、この方向性はもう後戻りしないだろうな、という感覚があります。
何が本当に新しいのか:LLMが「マウスとキーボード」を持った
技術レポートを読む限り、Computer Use API の本質は「LLMにUI操作権限を与えた」ことです。
open_url,click,type_text,scroll,download_fileなどのアクションを
LLMが自ら決めて投げてくる- こちら側はそれを受けて、ヘッドレスブラウザや仮想デスクトップで実行する
- スクリーンショットやDOM情報を返すと、また次のアクションを決める
つまり、もはや「APIを叩くAI」ではなく、
「ブラウザを操作する人間の代わりに座っているAI」 です。
ぶっちゃけ、この1点だけでもRPA業界にはかなり効くパンチだと思います。
なぜ重要か:RPA・Zapier・Googleと比べて見えてくる「立ち位置」
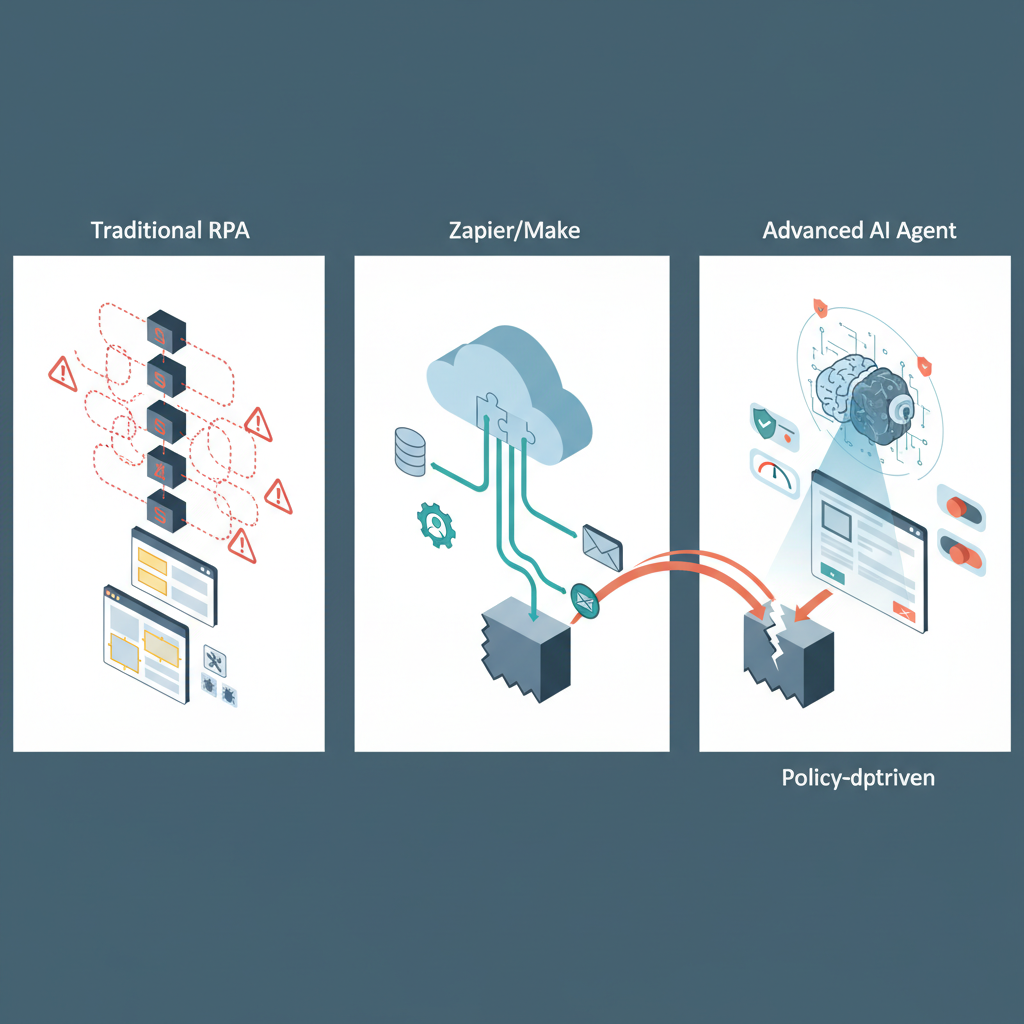
従来RPA(UiPathなど)との違い:シナリオから「方針と制約」へ
従来のRPAは、
- セレクタを指定して
- 手順書どおりのフローを書いて
- UIが変わったらメンテ地獄
という世界でした。
GPT-5.4 Computer Use はこうなります:
- 「このSaaSにログインして、先月分の売上レポートをダウンロードして」
- ドメイン許可リストや上限クリック数などの ガードレール をコードで定義
- あとはモデルが画面を見ながら、自分でボタンや入力欄を探す
人間がやっている曖昧なUI読解(「多分このボタンがエクスポートだな」的なやつ)を、モデルに投げられる のが決定的に違います。
正直、
「細かいUI操作を全部コードに落とすのがダルいから結局人がやる」
という小さな業務、自社にも大量にありませんか。
そこにかなり刺さるはずです。
Zapier / Make との違い:APIがない世界の“最後の砦”
Zapier や Make は素晴らしいですが、前提は「APIか公式コネクタがあること」です。
現実には:
- 日本ローカルのSaaS
- レガシー風味の業務システム
- ベータ版の新サービスでAPIが未整備
みたいな「長い長いロングテール」が山ほどあります。
Computer Use はここを狙い撃ちしています。
- APIやコネクタがなくても
→ ブラウザさえあれば動ける - “ノーAPI”な業務に
→ “それでも自動化する” という選択肢をくれる
Zapier視点でいうと、
「自分たちがカバーできなかった領域を、プログラマブルなエージェントに持っていかれる」懸念が出てくるはずです。
Google Gemini / Workspace オートメーションとの比較
個人的に一番面白いのは、Googleとの比較です。
関連:Google側の個人文脈AI(Workspace横断)の方向性は、Google「Personal Intelligence」を米国で全ユーザー提供へ:個人文脈AIのインパクトと落とし穴でも整理しています。
- Google側:
- Gmail / Docs / Sheets / Calendar に 深くネイティブ統合
- ただし、基本は「Googleの世界」の中で完結する発想
- OpenAI側:
- どのSaaSにも依存しない、ブラウザさえあれば行ける汎用ロボット
- ただし、すべてを自前でサンドボックス・監査する責任が開発者側に乗る
Googleは「城の中を極限まで快適にする戦略」。
OpenAIは「どの城の城壁も越えられる操縦士を育てる戦略」。
スタートアップやSaaS横断の自動化をやりたいチームからすると、
現時点では GPT-5.4 Computer Use の方が“現場力”は高い と感じます。
使って見えてくる「現実的な使いどころ」
レポートの設計パターンを読むと、作者もかなり冷静に見ています。
特に「これは万能ではない」という含みが強くて、そこに共感しました。
向いている領域
- APIがない or 不完全なSaaSの定型作業
- 毎月のレポートDL
- CSVアップロード & バリデーション
- 社内オペレーションの“半自動化”
- エージェントがまず作業 → 最後の確定ボタンだけ人間が押す
- プロトタイプやPoC
- 「この業務、どこまで自動化できそうか?」を早めに検証する用途
まだ厳しい領域
- 秒単位でレスポンスが求められるUI
- 推論+ブラウザ操作+ネットワークで平気で数十秒クラス
- 完全に決まったフローを1,000回/日まわすバッチ処理
- コストと非決定性の両面で、シンプルなスクリプトやAPI連携がまだ強い
この線引きを誤ると、「Computer Useすごい!」から「あれ?なんか遅いし高いし、たまにミスるんだけど…」に一気に落ちます。
「ただ、懸念点もあります…」と思ったところ
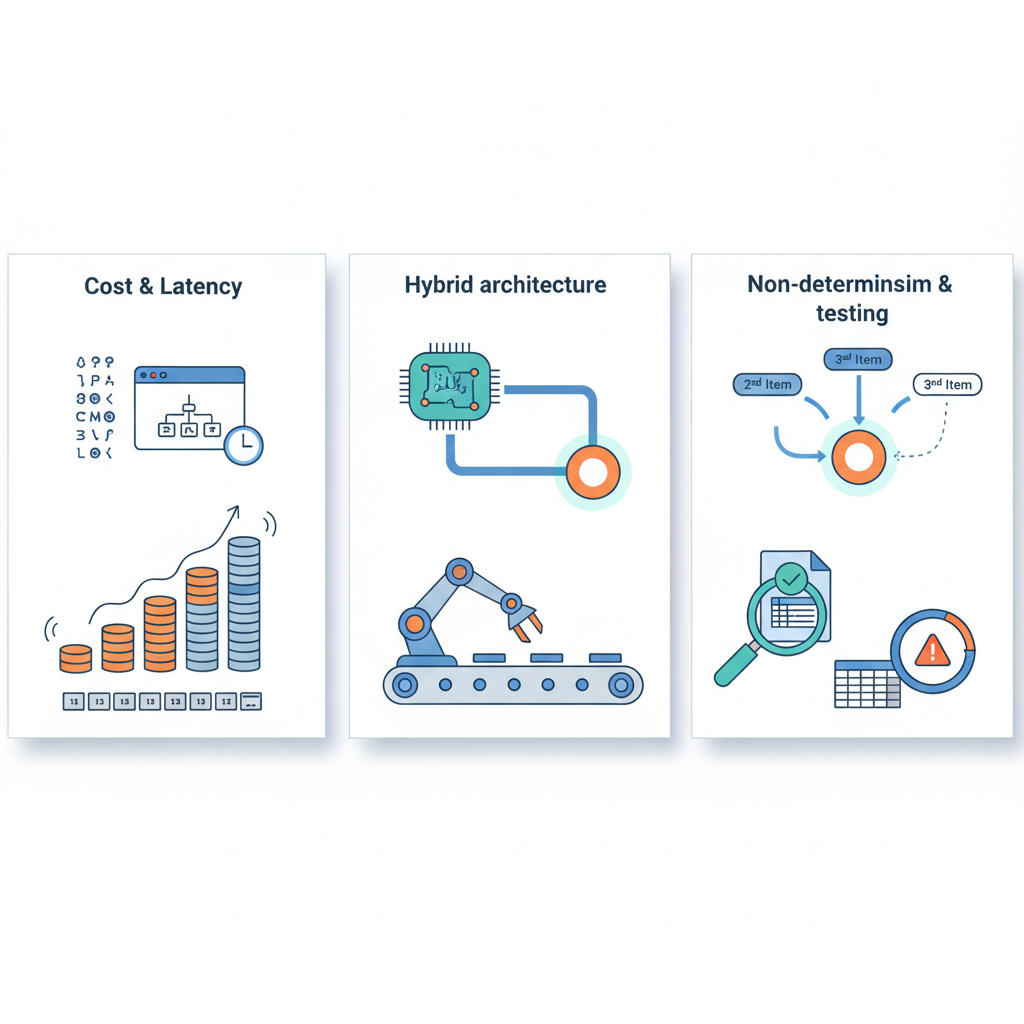
ここからは、正直に気になるポイントです。
コストとレイテンシ:魔法ではなく“高級RPA + LLM”
- 1クリックごとに
- LLMの推論トークン
- 画像 or DOM解析
- ブラウザの実行時間
- 10〜20ステップあるような業務を1件処理したら、それなりの課金額になります。
ぶっちゃけ、
「人件費より高くなってない?」というケースも普通に出るはずです。
なので、
- “全部Computer Use” ではなく
- 重要な分岐や判断だけを任せる
- 単純連打はPlaywrightや従来RPAでやる
という ハイブリッド構成 が現実解になりそうです。
コスト最適化(軽量モデルの使いどころ)まで含めた考え方は、OpenAI GPT-5.4 mini / nano登場:コスト・性能・使い分けと導入判断の要点も参考に。
非決定性:テストと監視の考え方を変えないと危険
LLM+UI操作なので、
- 同じ指示でも、
- 違うボタンを選ぶ
- 商品リストの2番目を選ぶ日もあれば3番目の日もある
といった揺らぎが起きます。
テスト観点も変わります。
- 以前:
- 「このボタンIDをクリックしているか」をテスト
- これから:
- 「意図した結果になっているか」をテスト
- 例:正しいファイルがDLされたか / データ整合性は保たれているか
正直、テスト自動化の文脈ではかなり発想を変えないとキツいです。
セキュリティとコンプライアンス:LLMは“高性能だけど信用できない外部委託”
レポートで一番共感したのがここです。
Computer Use を安全に使うなら、LLMを 「賢いけど信用してはいけない外部オペレーター」 とみなす必要があります。
- 許可ドメインのホワイトリスト
- アップロード/ダウンロードの制限
- 「ログイン」「送信」操作の人間承認
- 全クリック・入力のログとスクリーンショット保存
これらを コードとして一元管理するポリシー層 を作らないと、
「AIが勝手に顧客情報を別サービスに貼り付ける」といった悪夢が普通に起きます。
特に
- 認証情報の扱い
- 画面キャプチャの保存とマスキング
- 規制業界での監査ログ
ここは「面倒だからとりあえずフルアクセスで試すか」は本当にやめた方がよい領域です。
ベンダーロックイン:ビジネスロジックを“GPT-5.4に書く”怖さ
今回のAPI設計はかなりOpenAI固有です。
computer_useという特定ツールタイプ- アクション名や引数の設計
- モデルのGUI理解の挙動
これを前提にビジネスロジックを書き始めると、
- 料金変更
- 利用ポリシー変更
- モデル挙動のアップデート
にガッツリ巻き込まれます。
ここは、
- 自社側に抽象レイヤーを作る
- 「UI操作の意図」を自前APIにする
- その下にOpenAI・将来のGemini・Anthropicを切り替えられるようにする
- 「コア業務ロジック」をプロンプトの中に書きすぎない
といった地味な設計を、最初から意識しておいた方が良いと感じました。
結局、プロダクション投入するか?個人的な結論
正直に言うと、「本番の中核システムにはまだ様子見、ただし“現場PoCと一部業務”にはすぐ試したい」 というのが今の結論です。
今すぐやってもいいと思うこと
- スコープの狭い業務から始める
- 例:特定SaaSから毎日1種類のレポートをDLする
- ドメイン許可リストとアクション上限をガチガチに決める
- 全操作ログ+スクリーンショットを必ず残す
- 重要な送信操作には人間承認を挟む
この範囲なら、「壊れても影響が限定的」で、
かつ「どこまで自動化できそうか」の感覚を掴めます。
まだやらない方がいいと思うこと
- 売上や在庫に直接影響するクリティカルな本番フローを全面移行
- コアな業務プロセス全体を「GPT-5.4に任せる」前提で設計し直す
- 監査・ログ・セキュリティポリシーを整える前に、
内部システムへフルアクセス権を与える
ここを焦ると、「PoCは盛り上がったけど、運用で詰む」の典型パターンになりそうです。
まとめ:これは“第二世代RPA”の始まりだが、魔法ではない

- GPT-5.4 Computer Use は
- 「APIがない世界」を自動化するための 新しい強力なレイヤー
- Selenium + 人間QAエンジニアを1つにしたような存在
- しかし同時に
- コスト・レイテンシ
- 非決定性
- セキュリティ・監査
- ベンダーロックイン
という現実的な課題も、かなり重いです。
個人的には、
「Docker初期に、いきなり本番サーバー全部をコンテナ化しなかった人」
の姿勢がちょうどいい
と思っています。
- まずは 小さく、よく観察できるところから
- ガードレールとログ設計を最初から「本気」でやる
- RPAとAPI連携とLLMを、うまく役割分担させる
このあたりを意識して触り始めると、
「自社の業務どこまで自動化できるか?」の上限値が、かなりクリアに見えてくるはずです。
そして、そのとき本当に怖くなると思います。
「いままで“人がやるしかない”と諦めていた仕事、本当はだいぶ機械に投げられるんじゃないか?」 と。
FAQ
Computer Use APIは、どんな業務から試すのが安全?
影響範囲が小さく、結果が検証しやすい業務(例:特定SaaSからのレポートDL、定型のCSVアップロード)からがおすすめです。送信/確定など不可逆操作は人間承認を挟みましょう。
従来RPA(UiPath等)は不要になる?
当面は不要になりません。決まったフローを大量に回すなら従来RPA/Playwrightが強く、Computer UseはUI変化や例外が多いロングテールに刺さります。役割分担(ハイブリッド)が現実的です。
最低限のガードレールは何を用意すべき?
まずは許可ドメインのホワイトリスト、操作上限(クリック数/時間)、全操作ログ(入力・クリック・スクショ)、そして重要操作の承認フローです。「賢いけど信用できない外部オペレーター」前提で設計するのが安全です。

コメント