
「LLMのエンドポイントは動くけど、プロダクションに載せると途端に地獄」──そんな経験ありませんか?
- LangChainや自作フレームワークでエージェントを組んだ
- 監視もログもそこそこ整えた
- なのに本番に出すと、意図しないツール呼び出し、謎の遅延、GPUの無駄遣い、セキュリティレビュー地獄…
正直、ここ1〜2年の「エージェントやろうぜ」ムーブメントって、アプリ側だけが先走って、インフラ側が追いついてない状態でした。
その「インフラ側」をまるごと取りにきたのが、NVIDIA GTC 2026で発表された 「Vera Rubin プラットフォーム」だと感じています。
結論(忙しい人向け)
- Vera Rubinは「AIエージェント基盤を“インフラOS”として標準化する」宣言:ツール呼び出し/監査/スケジューリングまで含めて“土台”を握りに来ています。
- 効くのは「自前エージェント基盤を本番運用し始めている組織」:可観測性・セキュリティ・コスト最適化をプラットフォーム側へ寄せられる可能性があります。
- 最大の論点はロックイン:GPUだけでなく、ワークフロー定義や運用の作法までNVIDIA流儀に寄る点は要注意です。
想定読者:LLM/エージェントを本番運用している(または検討中の)プラットフォーム/インフラ/バックエンド担当。
関連:Vera CPUとNemoClaw/GTC 2026まとめ
Vera Rubin は一言で言うと「エージェント版 Kubernetes」

NVIDIA は今回の GTC で、はっきりと「Agent Era(エージェント時代)の開幕」を宣言しました。
その看板として出てきたのが、GPU「Rubin」とCPU「Vera」、そしてそれらを束ねる エージェント向けフルスタック基盤としての Vera Rubin です。
一言で言うと:
「Vera Rubin は、AIエージェント界の Kubernetes」
にかなり近いポジションづけです。
- 以前:
- LLMエンドポイント = コンテナ
- LangChain など = 手作りスクリプト & シェル芸 & ちょっとした orchestrator
- これから:
- Vera Rubin =
- エージェント定義
- ツール・関数呼び出し
- ワークフローDAG
- モニタリング・ポリシー・セキュリティ
をまとめて面倒見てくれる「標準オーケストレーター」
そして例によって、これはソフトだけの話ではなくハードまで一体化しています。
- Rubin GPU(FP64 33TFLOPS級)
- Vera CPU(AI/HPC向けCPU。従来CPU比で効率2倍・速度1.5倍とアピール)
- Vera Rubin NVL72 ラック(Rubin GPU 72枚 + Vera CPU 36個で FP64 2400TFLOPS)
- Micron の HBM4(GPU1基あたり288GB、NVL72で20.7TBメモリ)
- PCIe Gen6 SSD や SOCAMM2 メモリモジュールも「Rubin向け推奨構成」として最適化
Micron のリリースを見ると、「Vera Rubin プラットフォーム向け HBM4」「Rubin NVL72 向け Gen6 SSD」という書き方をしていて、完全に「プラットフォーム前提」の共同設計です。
ぶっちゃけ、ハードウェアからエージェントランタイムまで、全部 NVIDIA 色に染めるつもりなのがよく分かります。
Google / OpenAI / クラウド3社と比べて何が違うのか
ここ数年、各社が「エージェントプラットフォーム」を名乗り始めています。
- OpenAI:Assistants / tools / workflows 的な「SaaSとしてのエージェント実行環境」
- AWS:Bedrock Agents
- Azure:Azure OpenAI + Agents
- Google:Vertex AI Agents
そこに NVIDIA Vera Rubin が入ってきた構図を、ざっくり整理するとこうなります。
「どこにロックインされるか」が違う
- OpenAI / クラウド3社
- ロックイン先:クラウド + モデルAPI
- インフラ(GPU)はユーザからは隠蔽されている
-
自前データセンターやオンプレには持ち込みにくい
-
NVIDIA Vera Rubin
- ロックイン先:NVIDIA ハードウェア + ランタイム + オーケストレーション
- モデルは Baidu ERNIE 5.0 のような中国勢を含め、いろいろ「挿し替え可能」な前提
- 代わりにGPU/CPU/ネットワーク/メモリ/ストレージを NVIDIA 基準で固める
正直、「どのレイヤーでロックインされるかが変わっただけ」とも言えますが、オンプレ志向の企業からすると NVIDIA のアプローチはかなり魅力的です。
「誰の仕事を奪うか」が違う
Vera Rubin が一番効いてくるのは、実はクラウドというより
- いまエージェント基盤を自前で整え始めている 企業内部のプラットフォームチーム
- LangChain / LlamaIndex などの エージェント・オーケストレーション系 OSS / ベンダー
あたりだと思っています。
Rubin は最初から:
- ツールコール / function calling
- マルチエージェントのオーケストレーション
- DAGベースのワークフロー
- 監視・トレーシング・セキュリティ・ガバナンス
- GPU クラスタ上のスケジューリング
を「プラットフォームの標準機能」として持ち込もうとしています。
これは、Kubernetes が出てきた時に、
- 独自スケジューラ
- 自家製 PaaS
- 手作りコンテナオーケストレーション
が一気に「趣味枠」に追いやられた構図とかなり似ています。
「うちの社内エージェント基盤、けっこう頑張って作ったんだけど…」
→ 数年後には、「それ Rubin でよくない?」と言われる未来がリアルに見える
というのが、エンタープライズ側の現実だと思います。
「どこまで物理層を握るか」が違う
Gigazine の記事や Micron のリリースを眺めると、Rubin 世代では完全に
- HBM4 の積層数・帯域・電力効率
- PCIe Gen6 SSD のスループット・IOPS
- Vera CPU あたりのメモリ帯域(1.2TB/s)
- NVLink 6 や BlueField-4, Spectrum-X などのネットワーク構成
まで含めて「エージェント向けワークロードを前提に電力効率と帯域を最適化する」という発想になっています。
OpenAI も Google も当然ハードにはこだわっていますが、エンタープライズがその設計に直接アクセスできるわけではありません。
一方で NVIDIA は「NVL72 をデータセンターに丸ごと入れて、上に Vera Rubin を乗せる」という世界を作りにいっている。
- クラウドが abstract してきたレイヤーを、あえて再び表に出している
- そのうえで、「でも運用は Rubin が吸収するから楽ですよ」と言っている
ここが、クラウド各社との一番大きな違いかもしれません。
「すごい」のは分かる。でも実際、開発者に何が起きるのか
正直、「FP64 2400TFLOPS」とか「HBM4 2.8TB/s」と聞いても、
アプリ側のエンジニアからするとピンと来ないことが多いと思います。
ただ、Vera Rubin の「エージェント・プラットフォーム化」という文脈で見ると、開発フローへの影響はかなり具体的です。
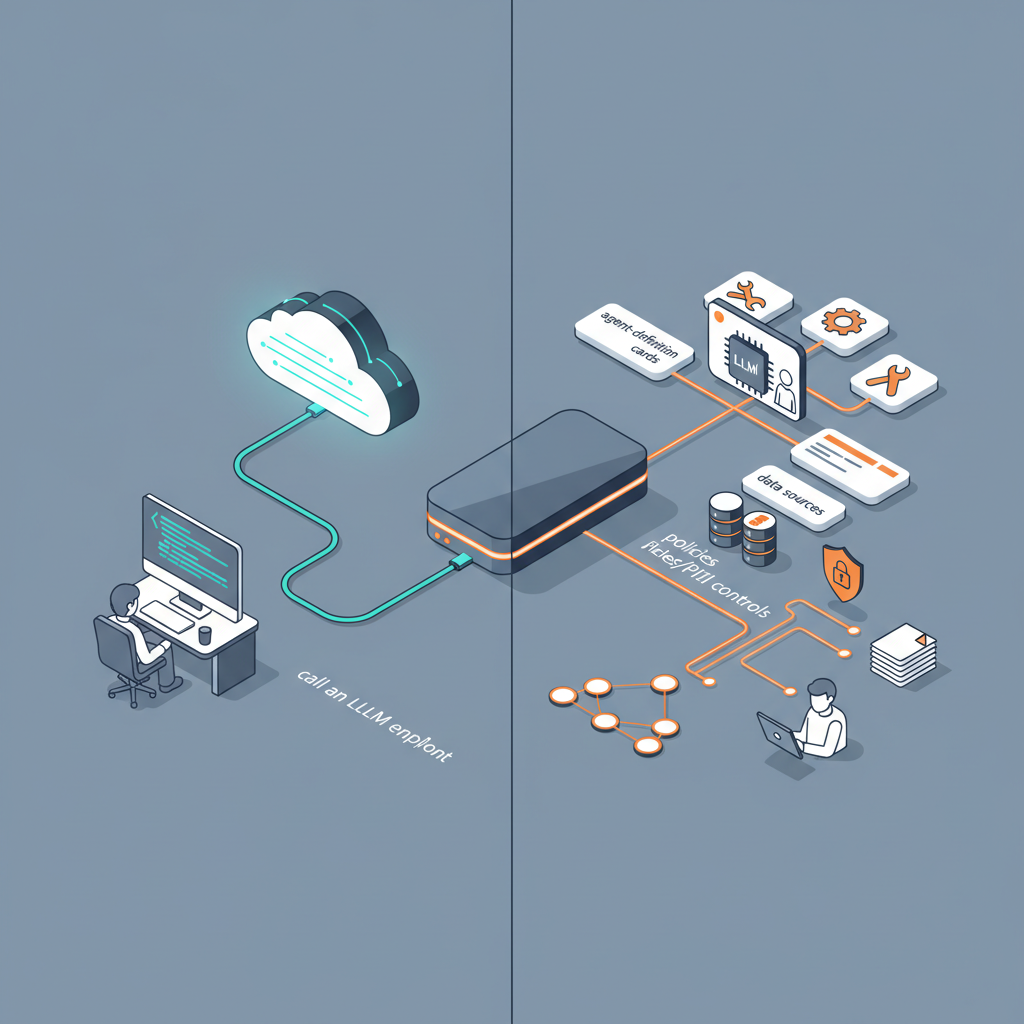
「LLMエンドポイントを叩く」時代の終わり
これまで多くのチームは:
- LLM API(OpenAI / Claude / など)を叩く
- LangChain / 自作コードで
- RAG
- ツールコール
- ワークフロー制御
- 監視やレート制御は別途自前実装 or APM に寄せる
という構成でした。
Rubin の世界では、おそらくこうなります:
- 「エージェント定義」を Rubin に登録
- 使えるツール群
- アクセスできるデータソース
- ポリシー(PII へのアクセス、外部API制限など)
- 「ワークフローDAG」を Rubin 上で定義
- チケット起票 → 要約 → 優先度分類 → 自動レスポンス案作成 → 人間レビュー
- LLMモデルは「エージェントの中の一コンポーネント」扱い
- ERNIE 5.0 でも、Anthropic でも、自社モデルでもよい
その代わり、
- ログ・トレース・メトリクスは Rubin のダッシュボードに集約
- 監査ログも Rubin 側で面倒を見る(日本の「イノベーション志向AI法」対応をうたっている)
- GPUリソース管理も Rubin のスケジューラ任せ
つまり、我々がいま「Glue code」として苦労している部分のかなりの割合を Rubin が標準機能として持っていく構図です。
既存のエージェントフレームワークとの関係
ここが一番現場を悩ませるポイントだと思っています。
- すでに LangChain / LlamaIndex / 自作フレームワークでPoC〜準本番まで進んでいる
- そこに Rubin SDK / API が入ってくる
すると、こういう選択を迫られます:
- A. Rubin をコアに据え、LangChain 等は「薄いラッパー」に格下げする
- B. Rubin には乗らず、クラウド or OSS で粘る
- C. 中立的な抽象層を作って、Rubin もクラウドAPIも背後で切り替えられるようにする
個人的には、
- もう NVIDIA GPU にフルコミットしている企業は、A や C を真剣に検討するフェーズに入ったと思っています。
- 逆に、マルチクラウド / マルチGPU を志向しているチームは、Rubin のAPIにべったり依存しないよう、クリーンな抽象インターフェースを挟んでおくのが無難です。
「Kubernetes に乗るか、自前オーケストレーションを続けるか」を迫られた 2016〜2018 年くらいの空気感に、とてもよく似ています。
ぶっちゃけ、懸念もかなり大きい
ここまで褒め気味に書きましたが、正直、懸念も少なくありません。
ベンダーロックインの「質」がさらに重くなる
GPU / ドライバレベルのロックインは、これまでもありました。
でも Vera Rubin ではそこに
- エージェント定義
- ワークフローDAG
- ポリシー / ガバナンスルール
- モニタリング / ログフォーマット
- データコネクタ設定
といったアプリケーションに近い情報までがっつり乗ってきます。
一度ここまで Rubin 流儀で作り込むと、
- AMD / Intel GPU に逃げたい
- 別クラウドの独自AIプラットフォームに乗り換えたい
となったときの移行コストは相当重くなるはずです。
「Kubernetes から EKS / GKE / AKS を乗り換える」の比ではなく、
「Kubernetes をやめてまったく別の PaaS に移る」レベルの痛みが出る可能性があります。
小〜中規模チームにはオーバーキルになりがち
Vera Rubin は明らかに
- NVL72 クラスのラックを前提にしたデータセンター
- 規制対応・監査対応が必須な大企業
- グローバルにGPUクラスターを回している組織
をターゲットにしています。
スタートアップや中小規模のチームが、
- シンプルな社内Copilot
- 数本のエージェントワークフロー
を回すだけなら、正直
- 普通に OpenAI / Claude API + 軽量フレームワーク
- もしくはクラウドのマネージドエージェントサービス
で十分というケースも多いはずです。
Rubin をフルに導入すると、
- 学習コスト
- 運用の複雑さ
- ライセンスやサポート費用
が一気に上がります。「やりたいことの規模」に対してプラットフォームが重すぎるパターンが見えるので、ここは冷静な見極めが必要です。
プラットフォームの「思想」と合わないユースケースも出る
Rubin は明らかに
- データセンター中心
- 長寿命で常駐するエージェント
- 企業内システムや業務プロセスとがっつり統合
を主戦場に見据えています。
なので、
- 完全に分散したピアツーピア型エージェント
- 極端なエッジ前提(スマートデバイス単体で完結するAI)
- 超実験的なアーキテクチャ(例:オンチェーンエージェント など)
のような「型破りな」ユースケースは、Rubin上では逆にやりにくくなる可能性があります。
プラットフォームが強い意見を持てば持つほど、そのレールからはみ出したときの摩擦は大きくなる、という話です。
じゃあ、プロダクションで使うか?個人的な結論
正直なところ、「全力で乗り換えよう」ではなく「かなり強く PoC してみるべきフェーズ」だと考えています。
導入判断のチェックポイント(実務)
- ロックイン境界:どこまでをNVIDIA流儀(ランタイム/DAG/監査)に寄せ、どこを抽象化層で守るか?
- 運用と監査:障害時の切り分け(MTTR)や監査ログの粒度は、現場の要求を満たせるか?
- 性能/コスト:ツール呼び出しが多いワークロードで、p95/p99とGPU利用率が本当に改善するか?
こういう組織は、かなり真面目に検討した方がいい
- すでに NVIDIA GPU クラスターを大量に抱えている
- 社内で AI プラットフォームチームが立ち上がっている / 立ち上がりつつある
- LangChain 等で自前のエージェント基盤を作り始めているが、「これを数年スケールさせ続けるのはしんどい」と感じている
- 規制対応(日本の「イノベーション志向AI法」や各国のAI規制)をどうするか悩んでいる
こういう組織は、
- 既存ワークロードの一部を Vera Rubin に載せて PoC
- エージェントの定義・ポリシー・ログ周りを Rubin 流儀に寄せたときの得失を検証
- GPU リソース利用効率とオペレーションコストのトレードオフを見る
あたりから始めるのが現実的だと思います。
逆に、まだ様子見でいいケース
- まだ本格的な「エージェント・プラットフォーム」を立てるほどの規模ではない
- まずは SaaS 的な LLM / エージェントサービスでビジネス価値検証をしたい
- マルチクラウド・マルチベンダー戦略を強く維持したい
こういうチームが、いきなり Rubin にフルコミットするのはおすすめしません。
- まずはクラウド各社のエージェントサービスや OpenAI のプラットフォームで「どんなワークフローが刺さるのか」を見極める
- 同時に、自分たちのエージェントロジックをきれいに抽象化しておき、「いつでも Rubin / 他プラットフォームに載せ替えられる」コードベースを意識して作る
くらいがバランスの良い位置取りだと思います。
まとめ:NVIDIA は「エージェントの Kubernetes」を取りに来た。ただし、乗る覚悟も試される
- Vera Rubin は、単なる新GPUや新CPUの発表ではなく、
「エージェントを第一級ワークロードとして扱うフルスタック・プラットフォーム」の宣言だった - 歴史的には、コンテナ時代の Kubernetes 登場にかなり近く、
LangChain 的フレームワークや自前エージェント基盤にはプレッシャーがかかる - 一方で、ハード〜ランタイム〜エージェントまで NVIDIA 流儀に乗ることになるため、
ロックインの重さとプラットフォーム思想との相性は冷静に見極める必要がある - プロダクションで全面採用するにはまだ様子見したいが、
「Rubin 前提での PoC を今年中に一度はやってみる」価値は、GPUを多く抱える組織には十分ある
正直、ここまでハードとエージェントランタイムが一体化した「AI基盤」は、いい意味でも悪い意味でも、もう引き返せないレベルの「プラットフォーム戦争」に突入した感じがあります。
数年後、「あのとき Vera Rubin をどう扱ったか」で、AIインフラ戦略の勝ち負けが分かれていてもおかしくない──それくらいの節目になりそうです。
FAQ
Vera Rubin は「Kubernetes」や既存のエージェント基盤と何が違う?
狙いは「コンテナやGPUを並べる」だけではなく、エージェント定義・ツール呼び出し・ポリシー(監査/セキュリティ)・可観測性までを一体の実行基盤として標準化する点です。
まずPoCで何を測ればいい?
p95/p99レイテンシ、ツール呼び出し回数あたりのオーバーヘッド、GPU利用率、そして障害時の切り分け時間(MTTR)を、既存構成と並走で比較するのが現実的です。
ロックインを抑える現実的な方法は?
ワークフロー定義やポリシーを“そのままVera Rubin固有仕様に閉じない”ために、中立的な抽象レイヤー(自前のDAG表現/実行API)を挟むのが無難です。
中小チームはどう向き合うべき?
いきなりフルコミットせず、まずはクラウド側のマネージドエージェント/LLM実行環境で要件を固め、本当に「インフラ側の最適化」がボトルネックになった段階で検討するのが安全です。

コメント