
「GPU は潤沢にあるのに、CPU 側のオーケストレーションがボトルネックで全然スループットが出ない」
そんなモヤモヤを、本番環境で味わったことはありませんか?
- 推論リクエストは捌けているはずなのに、なぜか p99 レイテンシが謎に跳ねる
- LangChain で組んだエージェントが、ツール呼び出しのたびに Python のシングルスレッドで詰まる
- GPU の利用率が 40〜50% でウロウロしていて、「金ドブ感」がすごい
正直、ここ数年の「GPU を積めば勝ち」みたいな空気に、エンジニアとしてはうっすら違和感がありました。
その違和感に、NVIDIA 自身が正面から答えに来たのが、今回の Vera CPU と NemoClaw です。
結論(忙しい方向け)
- Vera CPU + NemoClawは「GPUを回しきるためのCPU」と「エージェント/ツール実行を最適配置するランタイム」で、p99レイテンシやスループットのボトルネック(CPU/オーケストレーション側)に刺しに来ている
- 本番導入の判断軸は TCO(GPU利用率改善)・ロックイン・運用/デバッグ容易性(ブラックボックス化)
- まずは既存のLangChain等のフローを一部PoC置換し、レイテンシ/コスト/障害対応の現実を数字で比較するのが安全
想定読者:LLM推論基盤・エージェント基盤のアーキテクト / MLOps / インフラ/プラットフォーム担当
あわせて読む(背景整理):GTC 2026まとめ/フィジカルAI/260億ドル投資
一言で言うと、「NVIDIA 版 Apple Silicon + Kubernetes for Agents」です

一言で雑にまとめると:
- Vera CPU は、GPU クラスタ専用に最適化された「NVIDIA 版 Apple Silicon の CPU パート」
- NemoClaw は、「Kubernetes がコンテナを束ねたように、エージェント+ツール+GPU/CPU を束ねるランタイム」
という位置づけです。
Apple が Intel をやめて 自前 CPU(M1)+macOS を垂直統合したとき、
「単体スペックより“全体としての体験”を最適化するフェーズに入った」わけですが、
今回の Vera+NemoClaw は、AI インフラ版の同じ動きに見えます。
- これまでの NVIDIA:
- 「GPU はうち、それ以外(CPU や OS)は他社さんお願いします」
- これからの NVIDIA:
- 「CPU も OS まわりも、エージェントのオーケストレーションも、全部こっちで最適化します」
ぶっちゃけ、「GPU ベンダー」から「AI データセンター OS ベンダー」への進化宣言です。
何が変わるのか:Vera CPU と NemoClaw が狙っている“現実的な痛み”
Vera CPU:GPU クラスタを“ちゃんと回すための”CPU
Vera に関して重要なのは、GHz やコア数ではなく「何をしないか」です。
- x86 サーバー CPU:
- Web も、DB も、AI も、なんでも乗る汎用エンジン
- Vera:
- 「GPU をぶん回すための制御・前処理・後処理」に特化した CPU
役割としては:
- GPU クラスタの制御プレーン(タスク配分、スケジューリング)
- LLM のトークナイズや post-processing、軽量ツール呼び出しの実行
- NUMA や NVLink 括りを意識した「GPU までの最短・最太経路」の確保
これ、オンプレで GPU クラスタを運用している人なら、心当たりがあると思いますが:
- CPU 側の NUMA 設計が悪くて、GPU 間の通信が不必要に遠回りしている
- 推論前後の前処理(JSON 整形やログ/認可処理)が Python でダラダラ詰まっている
- でも、クラスタ構成を最適化しようとしても、GPU ベンダー/CPU ベンダー/OS ベンダーが全部バラバラで、誰も“全体最適”を見てない
Vera はここを「NVIDIA が責任を持って見ます」と言ってしまったわけです。
良くも悪くも、これはかなり大きな転換です。
NemoClaw:LangChain を“インフラの都合で”最適化し直したもの
一方 NemoClaw は、エージェント開発の現場で、みんながなんとなく感じていた限界にメスを入れています。
- エージェントの実装が Python のイベントループ任せで、スループットが頭打ち
- どの部分を GPU に乗せるか、どこは CPU でいいか、人間が手作業で決めている
- LangChain / LlamaIndex のチェーン定義が、そのままでは「ハードウェア的に最適なフロー」にならない
NemoClaw がやろうとしているのは:
- エージェントのプラン(DAG / グラフ)と
- 手元のハードウェアトポロジ(Vera+GPU+NVLink)
を同時に見て、
「このステップは CPU(Vera)でまとめて処理した方がよい」
「ここは GPU に近いところでストリーミングしながらやろう」
と、自動的に割り当てるオーケストレーション層です。
Kubernetes が「どの Pod をどのノードに載せるか」を抽象化してくれたように、
NemoClaw は「どのエージェント・ツール呼び出しをどの CPU/GPU に載せるか」を抽象化してくる。
正直、「GPU と LangChain を筋トレでねじ伏せていた」今までのやり方からすると、
かなり発想を変えさせられます。
なぜ重要か:NVIDIA は「GPU ベンダー」ではなく「AI OS ベンダー」として戦いに行っている

ここからが本題で、「なぜこれが重要か」を競合との比較で整理します。
CPU ベンダー(Intel / AMD)から見たインパクト
これまでの構図はシンプルでした:
- GPU:NVIDIA がほぼ独占
- CPU:Intel / AMD がデータセンターの“ホスト”として主役
Vera が出ると、NVIDIA はこう言えるようになります。
- 「NVIDIA GPU を本気で使うなら、Vera ベースが一番パフォーマンス出ますよ」
- 「CPU と GPU の境界をまたいだ最適化(帯域・レイテンシ・スケジューリング)は、Vera 前提でやります」
Apple が M1 で「Mac を買うなら Apple Silicon が一番いいです」と言ったのと同じ構図です。
Intel/AMD は、「NVIDIA GPU の世界」で急速に“空気”になるリスクがあります。
エージェント/オーケストレーション層(LangChain など)から見たインパクト
今、現場で使われているエージェント系スタックは、おおざっぱに:
- Python ベース(LangChain / LlamaIndex / custom framework)
- インフラ非依存(GPU でも CPU でも、一応動く)
- 実験〜プロトタイプには最高だが、ハイパフォーマンス本番にはちょっと辛い
というポジションです。
そこに NemoClaw が投げてくるメッセージは、かなり直球です。
- 「本番用のエージェント・インフラは、ハードウェア非依存ではなくハードウェア前提で最適化するべき」
- 「GPU の配線や NUMA まで見てスケジュールできるのは、インフラ層に近いランタイム(=NemoClaw)だけ」
つまり、
- LangChain は UI/DSL 的なフロントエンド
- NemoClaw がバックエンドの実行ランタイム
みたいな二層構造に寄せていきたい、という意図が透けて見えます。
Google / Microsoft / OpenAI も、クラウド側で似たことをやっていますが:
- 彼ら:
- 「自社クラウド上のマネージドな“黒箱”としてエージェント基盤を提供」
- NVIDIA:
- 「オンプレ/自社クラウド含めて、どこに立ててもいい物理 AI ファクトリーの OSとして提供」
という住み分けです。
オンプレで AI ファクトリーを作りたい企業にとって、NVIDIA はかなり強い“もう一つの選択肢”になってきました。
クラウドベンダー(AWS / Azure / GCP)との関係
クラウド側から見ると、この動きはかなり微妙なバランスです。
- プラス面:
- Vera ベースのインスタンスを提供すれば、「NVIDIA フルスタックで回る AI ファクトリー」をクラウド上で売れる
- NemoClaw をマネージドサービスとして載せれば、エージェント時代の PaaS として差別化できる
- マイナス面:
- ただでさえ GPU で NVIDIA 依存なのに、CPU とランタイムまで NVIDIA 依存が進む
- 自社の“AI プラットフォーム”(Vertex AI, Azure AI, Bedrock など)との棲み分けが難しくなる
AWS / Azure が今回の GTC に深く絡んでいるのは、「短期的な旨味」を取りに行きつつ、
「中長期的なプラットフォーム主導権」は絶対手放したくない、というせめぎ合いだと思います。
ただし、懸念点もあります:ロックイン・コスト・運用の三重苦リスク
ここまで割とポジティブに書きましたが、ぶっちゃけ懸念もかなり大きいです。
ベンダーロックインは、これまでと“質が違う”
これまでの NVIDIA ロックインは、主に GPU レベルでした。
- 「GPU を NVIDIA から AMD に変えたいけど、CUDA 依存がきつい…」
ぐらいの話です。
しかし Vera+NemoClaw まで入れると、ロックインはスタック全体におよびます。
- CPU:Vera 前提の最適化(NUMA / NVLink トポロジ)
- エージェントランタイム:NemoClaw の API/DAG モデル
- モデル:NeMo / Nemotron Coalition 前提のチューニング
ここまで踏み込むと、
- 別ベンダーの GPU に乗り換えようとした瞬間:
- エージェントのオーケストレーションロジックを まるごと書き換え る羽目になる
- モデルのデプロイ方法・監視・スケジューリングの仕組みも変えないといけない
という、「物理インフラとアプリケーションの結合」がかなり強い状態になります。
正直、「AI ファクトリーを丸ごと NVIDIA で建てる」という意思決定は、
クラウドベンダー並みの覚悟がないと危険です。
コスト構造:CPU までプレミアム価格で買う覚悟があるか
NVIDIA のフルスタックは、歴史的に見ても「安い」という話はほぼ聞きません。
Vera もおそらく、汎用 x86 CPU と同じ価格帯になることは期待しにくいです。
- 多くの AI ワークロードでは:
- GPU が常時フル稼働
- CPU はピーク以外はかなり余らせがち
となりがちで、CPU 部分に高いお金を払ったのに、平均利用率は 20〜30% みたいな世界も普通にありえます。
もちろん、「GPU の利用率が 20% しか出ていない」状況を解消できるなら、
トータルでは得する可能性もあるのですが、
- どのくらい Vera で最適化したら本当に TCO が下がるのか
- 既存の x86 ベースクラスタとどう共存・移行させるのか
は、相当シビアに試算する必要があります。
運用とデバッグ:Python から“ブラックボックスなランタイム”に寄せる怖さ
今の LangChain ベースの世界には、「雑に書ける」という大きなメリットがあります。
- 何かあれば Python のスタックトレースを見て、print デバッグすればいい
- レイテンシ問題も、プロファイラをあてればボトルネックがだいたい見える
NemoClaw のようなランタイムにロジックを寄せていくと、
- エージェントの制御フローが「ランタイム内部の DAG グラフ」に吸い込まれる
- デバッグには NVIDIA 独自のツールやダッシュボードが必須になる
- インフラチームとアプリチームの境界が、今よりさらにややこしくなる
という新しい“運用の壁”が立ち上がります。
正直、初期フェーズでは:
- ドキュメントも追いつかない
- ベストプラクティスもまだ固まっていない
- API もゴリゴリ変わる
という「早期導入者の宿命」を背負う覚悟が必要だと思います。
筆者の結論:プロダクションでフル採用するか?正直、段階的な“実験導入”が現実的です
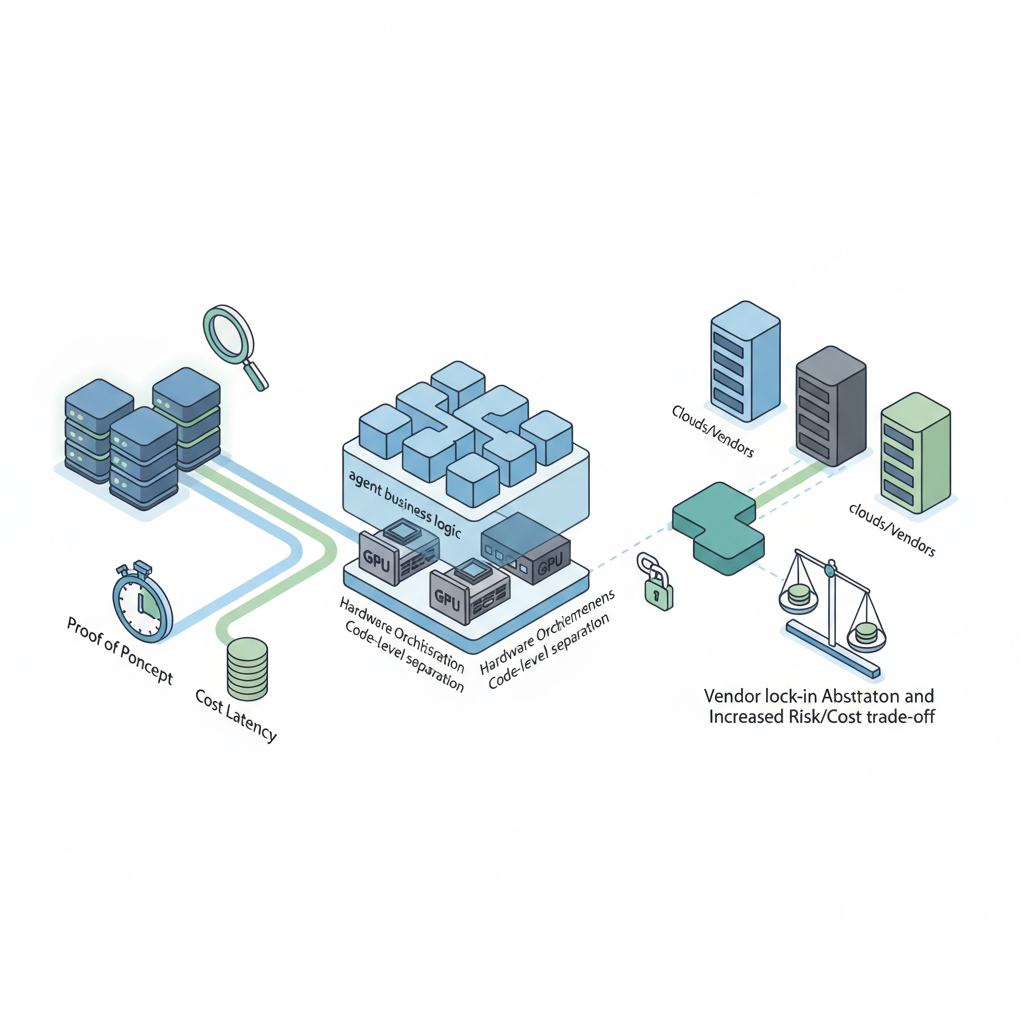
まとめると、Vera CPU と NemoClaw は:
- 「GPU だけじゃなく、AI データセンター全体を OS 的に握る」という NVIDIA の大きな一手
- GPU クラスタ運用・エージェント本番運用の“現実的な痛み”にかなり正面から刺さっている
- その一方で、ロックイン・コスト・運用設計のリスクも、これまで以上に重い
では、現場のエンジニア/技術決裁者としてどう動くか。
自分なら、次のように整理します。
今すぐやってよいこと
- NVIDIA GPU に全振りしている組織:
- Vera ベースのノードと NemoClaw SDK を 小さなクラスターで PoC する
- 既存の LangChain ベースのフローを、一部 NemoClaw に写経して 実運用時のレイテンシ&コストを比較 する
- マルチクラウド/マルチベンダーを重視する組織:
- NemoClaw を「バックエンドの 1 実装」として扱えるように、自前の抽象化レイヤーを用意する
- エージェントのビジネスロジックと、ハードウェア依存のオーケストレーションロジックを コードレベルで分離 しておく
まだ踏み込まない方がいいこと
- データセンター丸ごと「Vera+NemoClaw 前提」に設計し直す
- 既存の x86 クラスタや OSS エージェントフレームワークを、短期間で一気に置き換える
正直、2026 年のタイミングで 本番の基幹システムを全面移行 するのは、かなり攻めすぎだと思います。
とはいえ、「様子見で一切触らない」というのも、それはそれでリスクです。
Apple Silicon のときも、
「うちはまだ Intel でいいや」と言っていたチームが、2〜3 年後に一気にキャッチアップを迫られました。
Vera+NemoClaw も、おそらく似た曲線をたどる可能性があります。
最後に
AI プラットフォームの世界は、これまでは
- 「GPU をどれだけ積むか」と
- 「Python でどれだけ器用にチェーンを書くか」
の勝負でした。
Vera CPU と NemoClaw が本当に普及すると、勝負の軸はこう変わります。
- 「どの AI OS(= ベンダーのフルスタック)に賭けるか」
- 「ハードウェア前提の最適化を、どこまでビジネスロジックから切り離せるか」
正直、エンジニアとしてはめんどくさい時代に突入したとも言えます。
でも、その“めんどくささ”をうまく抽象化できたチームが、次の 3〜5 年のプロダクション AI で優位に立つのは間違いないはずです。
Vera と NemoClaw は、そのゲームチェンジの“前触れ”として、かなり本気度の高い一手だと感じています。
FAQ:Vera CPU / NemoClaw を検討するときの論点
Q. どんな組織・ワークロードで効果が出やすい?
GPUはあるのにCPU側やオーケストレーションが詰まってGPU利用率が上がらない、もしくはp99が跳ねるタイプの基盤ほど効果が出やすいです(推論API、ツール呼び出しが多いエージェント、前後処理が重いパイプラインなど)。
Q. まずPoCで何を測ればいい?
p50/p95/p99レイテンシ、GPU利用率、CPU利用率、ツール呼び出し回数あたりのオーバーヘッド、障害時の切り分け時間(MTTR)を、既存構成と並走比較するのがおすすめです。
Q. ロックインを抑える現実的な方法は?
NemoClawを“唯一の実装”にせず、エージェントの業務ロジックと実行ランタイム依存部(DAG/スケジューリング)をコードで分離しておくと、将来の差し替えコストを下げられます。
Q. 運用は楽になる?それとも難しくなる?
自動最適化が効くと性能は上がりやすい一方、制御フローがランタイム内に吸い込まれてデバッグが難しくなる可能性があります。早期は運用チームの観測・トレーシング整備が重要です。


コメント