
結論(導入判断 / 忙しい方向け)
- APIの変動費をローカル処理に逃がすと請求のブレが小さくなる(完全無料ではなく機材・運用費はかかる)
- 定型の要約/社内生成はローカル、重要な顧客向け出力や高度推論はクラウドに残すハイブリッド運用が現実的
- 議事録/テストコード生成など、まずは1業務ずつ移して月額API請求を見ながらROIを評価する
想定読者: AI費用(トークン代)が気になり始めたエンジニア、情シス/開発リード
「3ヶ月でAnthropicのトークン代が約90万円。だからこのMac Studioは3ヶ月くらいで元が取れる計算!」
そんなパンチのあるポストが、すぐるさん(@SuguruKun_ai)のXで流れてきました。
「AIのトークン代が月30万円かかってたけど、このやり方を試したら月0円になった」
月30万円……。
家賃かよ、ってレベルの数字ですよね。
しかも「やり方を変えたら月0円」なんて言われたら、そりゃタイムラインもざわつきます。
ただ、エンジニア目線でここをちゃんと分解しておかないと、
- 「やっぱりみんなMac Studio買ってるのか!」
- 「ローカルLLM入れれば全部タダになるんでしょ?」
- 「うちも“AI費用0円”にしろって言われたんだけど?」
みたいな、“ふわっとした期待”だけが独り歩きしがちです。
この記事では、このバズを入り口にしつつ、
- Xでの主張(何が言われているのか)
- 事実として確認できる範囲(どこまで本当か)
- そこからエンジニアがどう設計を変えるべきか
を、「ローカルLLMで“変動費”をどこまで“固定費化”できるか」という視点で整理します。
※Gemma 4の仕様・ライセンス整理は Gemma 4(DeepMind)とは?、ローカル運用の設計ポイント(量子化/NPU/ハイブリッド)は オンデバイスLLM入門 も参考になります。
この記事を読むと、次のことが分かります。
- 月3万・10万・30万円のAI費用で、ローカル化の損益分岐がどこにあるか
- Gemma系を含むローカルLLMで、どんなタスクなら現実的に節約できるか
- 個人開発・副業・社内導入それぞれで、どこから手を付けると安全か
- 「月0円」という言葉を、エンジニアとしてどう“翻訳”して判断すればいいか
「毎月のAPI請求が読めない」「エージェントを本格導入したいけど費用が怖い」「高いマシンを買うべきか判断できない」といったモヤモヤを、できるだけ数字と設計の話に落としていきます。
【月30万円級のAI請求に終止符?】日本のエンジニア向け、ローカルLLMで固定費化する5つの考え方
「3ヶ月でAnthropicのトークン代が約90万円。だからこのMac Studioは3ヶ月くらいで元が取れる計算!」
そんなパンチのあるポストが、すぐるさん(@SuguruKun_ai)のXで流れてきました。
「AIのトークン代が月30万円かかってたけど、このやり方を試したら月0円になった」
月30万円……。
家賃かよ、ってレベルの数字ですよね。
しかも「やり方を変えたら月0円」なんて言われたら、そりゃタイムラインもざわつきます。
ただ、エンジニア目線でここをちゃんと分解しておかないと、
- 「やっぱりみんなMac Studio買ってるのか!」
- 「ローカルLLM入れれば全部タダになるんでしょ?」
- 「うちも“AI費用0円”にしろって言われたんだけど?」
みたいな、“ふわっとした期待”だけが独り歩きしがちです。
なのでこの記事では、このバズを入り口にしつつ、
- Xでの主張(何が言われているのか)
- 事実として確認できる範囲(どこまで本当か)
- そこからエンジニアがどう設計を変えるべきか
を、「ローカルLLMで“変動費”をどこまで“固定費化”できるか」という視点で整理していきます。
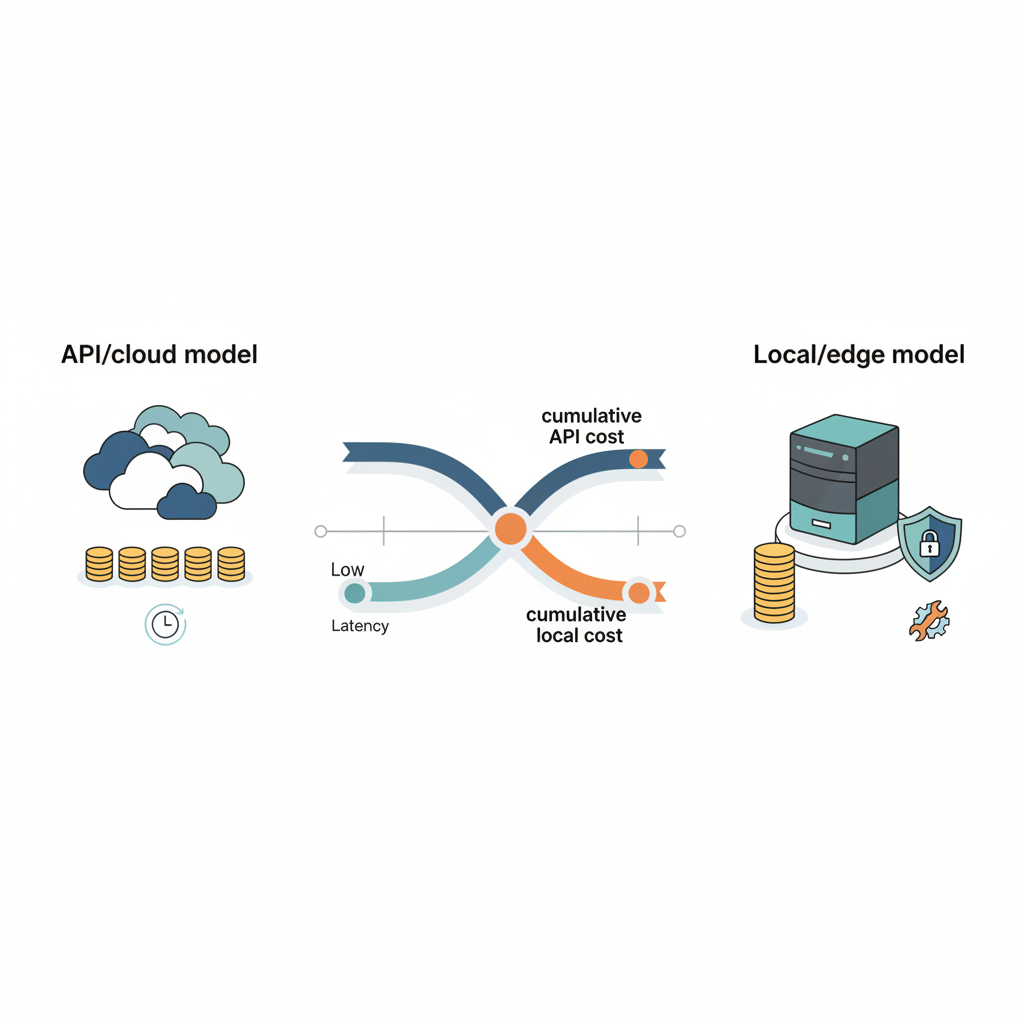
結論から言うと、「全部ローカルにすれば月0円!」ではなく、
高いクラウドAPIを“なんでも屋”として使うのをやめて、
安い処理はローカル/OSSモデルに逃がしていくと、
請求のブレ幅が一気に小さくなる
という話です。
その上で、具体的には次の5つの考え方が効いてきます。
-1. なぜ2026年前後は『AIコストの見直し』が一気に進んでいるのか?
まず前提として、「今なぜこんなに“AI節約術”がバズるのか?」を軽く整理します。
Xでの主張・論点(例)
- Claude Code や Cursor みたいなコーディングAIをガチで回すと、月数万〜数十万円の請求になる
- OpenClaw(Claudeのサブスク代替)の停止もあって、「じゃあ次どこに乗るの?」という不安
- そこに「Gemma 4(※実際はGemma 3/3n世代のローカルモデル)でローカル運用すればタダ同然」という話が刺さる
事実として確認できる背景(参考リンクベース)
- オープン/ローカルLLMの性能が上がりまくっている
- Qwen3、DeepSeek-V3.2、Nemotron 3、Gemma 3/3n など
- 日本語性能も Qwen3 系や Nemotron 系がかなり強い(日本語LLMランキング 参照)
- ローカルLLMを動かす環境がめちゃくちゃ整ってきた
- Ollama / LM Studio / llama.cpp など(ノートPCで動くローカルLLM完全ガイド)
- API課金 vs ローカルGPU投資のコスト構造が、
「月数十万円クラスまで使うなら、3〜6ヶ月でGPUの元が取れる」ラインに入ってきている
(オンプレLLMのコスト比較例 → コスト比較|クラウドLLM vs ローカルLLM)
そして決定打になっているのが、
- AIエージェント化で「呼び出し回数が人間の操作感覚を超えて増える」
- それなのに従量課金モデルのまま、というギャップです。
人間がチャット1回打つのと違って、エージェントは裏で何十回も LLM を叩きます。
API側の単価が変わっていなくても、設計の都合で“面積”が爆増しているわけですね。
そりゃ月30万円いくよね、という。
-2. この記事が刺さる読者:月1万〜30万円のAI費用にモヤッとしている人
「うちはそこまで使ってないから関係ないかな」と思うかもしれませんが、
個人〜小規模チームでも、意外とすぐ“痛み”が出ます。
こんな人向けです。
- 個人開発・副業エンジニア
- Cursor / Claude Code / ChatGPT Plus などに
「月1〜2万円くらいなら…」で課金したら、
気づけば API 課金も積み上がって月3〜5万になってきた人 - スタートアップ・小規模チーム
- 社内でAIエージェント PoC をやっていたら、
月10〜30万円くらいのAPI請求が刺さるようになってきたCTO / Tech Lead - 社内AI推進担当
- 生成AIツールの利用は伸びているが、
経理や上層部から「この請求どこまで伸びるの?」と突っつかれ始めている人
逆に、「月1000円課金でたまにGPT使う程度」の人には、
ローカルLLMの初期投資はまだオーバースペックかもしれません。
-3. 先に結論:『全部オンプレ化』より『安い処理だけ地元採用』が勝ちやすい
Xでは「月0円!」みたいなキャッチーな表現になりがちですが、
実務で見るべきは「変動費(API課金)をどれだけ固定費(マシン+電気代)に置き換えるか」です。
Xでの主張
- ローカルに Gemma 4(※実態は Gemma 3 / 3n 4B/12B/27B 相当のモデル)を載せる
- それで普段の開発・チャット・要約・軽いコード生成などを回す
- 高精度がほしいときだけ GPT や Claude API をピンポイントで叩く
→ その結果、「毎月のAnthropicトークン代がほぼゼロになった」
ここから読み取れる“実務的な翻訳”はこんな感じです。
1. 完全無料ではなく「従量課金の圧縮」
- 0円になるのは「外部APIの請求」であって、
- マシンの減価償却(たとえば Mac Studio 40〜60万円)
- 電気代(GPU載せっぱで月数千〜1万円)
- 自分のセットアップ・保守コスト
は普通にかかります。 - なので正確には、
「月30万円のAPI変動費を、数万円レベルの固定費+ちょっとのクラウドに変えた」
くらいに読むのが安全です。
2. “全部ローカルにする”のはほぼ負けパターン
- DeepSeek-V3.2 や Qwen3-235B のようなトップクラスのオープンモデルでも、
GPT-5 や Claude Opus 4.5 みたいな商用フラッグシップに、
あらゆるタスクで肩を並べるわけではありません。 - 特に
- 高難度の推論
- 長大コンテキスト(数十〜数百ページ)
- お客さんに直接見せる最終アウトプット
この辺は、まだクラウドAPI側に分があります。
3. だから“ハイブリッド構成”が現実解
ざっくり分けると:
- ローカルLLM(Gemma 3/3n 4B / Qwen3-8B など)に向いているのは
- 議事録・チャットログの要約
- 社内FAQのドラフト生成
- コードのリファクタ案の叩き台
- ログからのエラー候補洗い出し
- RAG で手元ドキュメントを読むボット
- クラウドAPI(GPT-5.x / Claude Opus/Sonnet / Gemini 3 Pro など)に残すべきは
- 大事な顧客向けの提案書や仕様書
- 難しいバグ調査や設計レビュー
- マルチモーダル(画像・動画込み)の重いタスク
- 社外公開サービスでの本番推論
この「軽い処理だけ“地元採用”して、重鎮タスクはまだ外注」というバランス感が、
費用も、品質も、精神衛生も守りやすいです。
-4. 5つの考え方:ローカルLLMで“請求のブレ”を小さくする
ここから先の記事全体で深掘りしていく内容を、最初にざっくり並べておきます。
-
考え方①:API課金は「単価 × 呼び出し設計」の掛け算
→ モデル乗り換えより、まず“どう呼んでいるか”を疑う。 -
考え方②:「変動費を固定費に移す」ときは、月いくら使っているかがすべて
→ 月3万・10万・30万で「元が取れるマシン」のラインが変わる。 -
考え方③:Gemma/Qwen/DeepSeekなどのローカルモデルは、“定型タスク担当”として見る
→ 「なんでもGPTレベル」を期待すると燃える。役割を落とすと一気に強い。 -
考え方④:ローカル化は“1業務ずつ”やるのが正解
→ いきなり「全部ローカルに」ではなく、「まずは議事録要約だけ」「まずはテストコード生成だけ」みたいに刻む。 -
考え方⑤:クラウドもローカルも“ログとテンプレ”を資産化してこそ安くなる
→ 毎回ゼロからプロンプトを書いて、毎回長い履歴を送るのが一番高い。
このあと、
- SNSの「月0円」発言を4つの論点で分解しつつ
- API vs ローカルの損益分岐をざっくり試算して
- 実際に Gemma 系をローカルで立ち上げる手順
- そして、エージェント設計でどこをいじればコストが落ちるか
まで、一気に掘っていきます。
自分の請求画面を片目に、「うちの使い方だとどこをローカルに寄せるのが効きそうか?」を想像しながら読んでもらえると、かなり設計のヒントが出てくるはずです。
SNSの『AI費用ほぼゼロ化』はどこまで本当? 4つの論点で冷静に分解してみた
まずは、今回の元ネタになっているポストをざっくり整理しておきます。
- すぐるさんのポスト(@SuguruKun_ai)
- 「AIのトークン代が月30万円かかってたけど、このやり方を試したら月0円になった」
- 「3ヶ月で約90万円のAnthropicトークン代を使ってた」
- 「だからこのMac Studioは3ヶ月くらいで元が取れる計算!」
さらに動画内では、Gemma 4(※実際には Gemma 3/3n 世代のローカルモデルと考えるのが自然)を使ったローカル運用の話が出てきます。
Xでの主張・論点としてはだいたいこんな感じです。
- Claude API(Anthropic)のトークン代がとにかく高い
- コーディングや日々の作業をローカルLLMに寄せたらAPI利用がほぼ不要になった
- 結果、毎月30万円かかっていたAPI費用が「0円」に近づいた
- その金額でMac Studioクラスのマシンなら数ヶ月で元が取れる
インパクトある表現なんですが、このまま真に受けると危ないポイントがいくつかあります。
ここでは4つの論点に分けて、「どこまでが事実ベースで、“どう読むべきか”」を整理していきます。
-1. 論点1:『0円』の正体は完全無料ではなく“従量課金の圧縮”では?
まず一番バズりやすいワード、「月0円」の話から。
Xでの主張
- 以前:Anthropic のトークン代 → 月30万円
- 今:Gemma 系ローカルモデルに切り替えた → Anthropic の請求が0に近くなった
- 結果として「AIのトークン代が月0円になった」と表現している
ここで冷静に分けておきたいのは、
- 「外部APIに払う従量課金」
- 「自分のマシンにかけている固定費(ハード代・電気代)」
は別物、という点です。
事実として確認できる範囲
関連している「クラウドLLM vs ローカルLLM」のコスト比較記事だと、だいたいこんな整理になっています(例:コスト比較|クラウドLLM vs ローカルLLM)。
- クラウドLLM
- 初期費用:0円
- 従量課金:トークン数 × 単価(例:入力 $0.03/1K, 出力 $0.06/1K など)
- ローカルLLM
- 初期費用:GPUマシンやサーバー → 数十万〜
- 月次:電気代+保守費用 → 月数万程度(構成による)
なので、「月0円」というのは厳密にはこう読むのが正解です。
外部のLLM APIに対する従量課金はほぼ0円になった
ただし、ハードウェア投資と電気代、運用の手間は発生している
実務への落とし込み(エンジニアがやること)
- 自分の請求を「固定費」と「変動費」に分解してみる
- ChatGPT / Claude / Gemini など → どこまでがサブスク固定、どこまでが従量?
- 特に「API従量部分」が増えているなら、ローカル化の余地が大きい
- ローカルLLMを検討するときは、
- 「従量課金を削る代わりに、どのくらいの固定費を許容できるか?」
- 「何ヶ月運用したらペイできそうか?」
をざっくり試算してみる
「完全無料化」ではなく、
“APIの変動費を、予測しやすい固定費に置き換える”という目線で見ると、判断を誤りにくくなります。
-2. 論点2:Gemma系ローカルモデルは、どの仕事なら十分戦えるのか?
次の論点は、「じゃあローカルモデルで本当に実用に耐えるの?」というところ。
X での空気感
- 「もうGemma 4で良くない?」
- 「Qwen3やDeepSeek-V3.2があれば商用モデルいらないのでは?」
- 「ローカルに乗せてAPI解約したわ」
このあたり、タスクごとにちゃんと分けて考えないと危険です。
事実として確認できる範囲
ベンチマークや実測をまとめてくれている記事をいくつか見ると:
- ノートPC向けローカルLLM比較(ノートPCで動くローカルLLM完全ガイド)
- Gemma 3 / 3n 4B / 12B / 27B
- Qwen2.5 / Qwen3 系
- DeepSeek-R1 蒸留モデル
- 2026年時点のローカルLLM事情(2026年のローカルLLM事情を整理してみた)
- Qwen3-14B が中型ローカルモデルの鉄板
- Nemotron 3 Nano や gpt-oss-20b など推論強めモデルも登場
これらを見る限り、
- 「一般的なチャット」「要約」「比較的シンプルなコード補助」
→ 8B〜14Bクラスのローカルモデルで、かなり実用レベル - 「高度な推論」「SWE-bench級の本気のバグ修正」「長大な技術文書解析」
→ まだ GPT-5 / Claude Opus / Gemini 3 Pro クラスに分がある
というのが現状です。
実務への落とし込み(エンジニアがやること)
手元のタスクを、次の2レーンに分けてみるのがおすすめです。
レーンA:ローカルに寄せやすいタスク
- 議事録・チャットログの要約
- 仕様書やチケットの要点抽出
- FAQの草案生成
- コードの叩き台(テストコード生成、単純なリファクタ案)
- 社内ドキュメントをRAGで検索するボット
→ Gemma 3 4B/12B、Qwen3-8B/14B、DeepSeek-R1 8Bあたりで試す価値あり
レーンB:まだクラウドAPIを使った方が安定するタスク
- 重大バグの原因特定や大規模リファクタの設計
- 直接クライアントに渡る提案書・企画書・仕様書の最終版
- マルチモーダル(画像・動画・音声込み)の解析
- 100ページ級ドキュメントを一気に読ませるような長文処理
→ GPT-5.x / Claude Opus / Claude Sonnet / Gemini Pro などをピンポイントで
ポイントは「全部ローカルに寄せる前提で考えない」ことです。
まずはレーンA側から1つ切り出して、ローカルに寄せてみるのが現実的です。
-3. 論点3:20万〜50万円級マシンは何カ月で元が取れる? 個人とチームで差が出る理由
すぐるさんのポストで一番インパクトがあったのがここですね。
「3ヶ月で約90万円のAnthropicトークン代を使ってた
だからこのMac Studioは3ヶ月くらいで元が取れる計算!」
ざっくり言うと、
- 1ヶ月のAPI課金:30万円
- Mac Studio:40〜60万円くらい(構成による)
- → 2〜3ヶ月でペイできる
というロジックです。
これは、「それだけAPIをヘビーに使っている人なら」という前提付きで成り立ちます。
事実として確認できる範囲
ローカルLLMのコスト比較例では、こんな感じの試算があります(同上のコスト比較記事 より)。
- モデル利用が多い場合(例:1日100万トークン処理)
- クラウドLLM:月額75万円
- ローカルLLM(初期300万+月20万):
→ 5ヶ月で初期投資回収、それ以降はローカルが有利
ポイントは「毎月どれくらい使っているかで、損益分岐がまるで変わる」ことです。
ざっくりした目安ですが:
- 月3万円レベル:
→ 個人でMac Studioクラス買ってペイするには時間がかかる - 月10万円レベル:
→ 1〜2年使うつもりなら、ローカル投資を真剣に検討してよい - 月30万円レベル:
→ かなり短期間でペイする可能性が高い
さらに、個人とチームでROIが全然違うのも重要です。
- 個人利用:
→ ハイエンドマシンを1人で占有。
元を取るには「その人1人のAPI消費」が基準。 - チーム利用(3〜5人):
→ 同じマシンを複数人でシェアできれば、
「メンバー全員分のAPI消費」が投資回収に効いてくる。
実務への落とし込み(エンジニアがやること)
- まず自分(orチーム)の月間AI費用をざっくり出す
- APIダッシュボードから月の総額を確認
- ChatGPT PlusやClaude Proのサブスクも含めて「AI関連コスト」を足し上げる
- それをベースに、
- 「このペースで1年続けたらいくらかかる?」
- 「Mac Studio / RTX 4080〜4090 クラスのマシン1台買った場合、何ヶ月でペイする?」
をざっくりExcelかスプレッドシートで計算してみる
ここを数字で見てみると、
「うちはまだローカル投資するほどじゃないな」なのか、
「そろそろ本気で考えないと燃えるな」なのか、方向性がかなりクリアになります。
-4. 論点4:コストだけでなく『使えなくなるリスク』も見ておくべき
最後の論点は、お金以外のリスクです。
Xでの空気感
- OpenClaw のサブスク停止のように、「頼りにしてたサービスが突然変わる」ケース
- APIの価格改定・レート制限変更・アクセス障害などで、
「使いたいときに使えない」問題への不安
これも、「ローカルに寄せる=節約」だけでなく、
「継続利用のリスクヘッジ」という見方をしておくと、設計の意味が変わってきます。
事実として確認できる範囲
- 2024〜2026年にかけて、
- APIの価格改定
- モデルラインナップの整理・統合
- 特定プランの新規受付停止
- サードパーティツールの仕様変更・停止
がちょこちょこ起きているのは事実です。 - 直近でも、「あるサブスク経由で安価にClaudeを叩けていた」のが、
プラン廃止で一気に使えなくなるパターンが話題になりました。
実務への落とし込み(エンジニアがやること)
- 「この処理が止まると、どのくらい業務に影響が出るか?」を洗い出す
- クリティカルなバッチ処理
- 基幹業務の一部を担っているエージェント
- 社内ユーザーが日常的に使っているチャットボット
- それらについて、
- 「このタスクは、最悪ローカルモデルに切り替えてもしのげるか?」
- 「APIが落ちたときのフェイルオーバー先はあるか?」
を一度考えておく
ここでも、「全部ローカルにしろ」ではなくて、
- 普段:クラウドの高性能モデルを使う
- 障害・制限時:ローカルモデルに切り替えて“最低限の機能”は動かす
という二段構えを作っておくイメージです。
節約というより、「AIインフラのBCP(事業継続計画)」に近い話ですね。
章の小まとめ
- 「月0円」は外部API従量課金の話であって、
ハード代・電気代・自分の工数は別腹 - Gemma/Qwen/DeepSeek系ローカルモデルは、
タスクを選べば十分実戦投入できる - ハイエンドマシン投資がペイするかどうかは、
今どれだけAPIを燃やしているか(月3万・10万・30万…)で全然違う - ローカル化の価値は、節約だけじゃなく
「いつ仕様が変わるかわからない外部サービス依存を減らす」ことにもある
次のセクションでは、この話をもう一歩踏み込んで、
「API課金とローカルLLM、結局どっちが得か?」を、月3万・10万・30万円のケース別にざっくり試算してみます。
API課金とローカルLLM、結局どっちが得? 月3万・10万・30万円で損益分岐を試算
「3ヶ月でAnthropicトークン代90万円だから、Mac Studioは3ヶ月で元が取れる」という、すぐるさんのポスト(主参照:Xの投稿)は、かなり極端な“ヘビーユーザーケース”です。
じゃあ、自分の月3万〜30万クラスの利用だと、どのタイミングでローカルに寄せるのが得なのか?
ここをざっくり数字で見ておきましょう。
-1. 比較表:API型 vs ローカル型を6項目で見比べる
まずは構造を整理します。
Xでの主張
- 「API(Anthropic)に毎月30万円払っていた」
- 「Gemma系ローカルに寄せたら、その部分のトークン代は0円になった」
- 「Mac Studioが3ヶ月で元取れるレベルだった」
これをそのまま真似る前に、API型とローカル型の向き不向きを一度テーブルで眺めるのがおすすめです。
(ざっくりイメージの比較です。実際の単価・スペックはモデルや環境で変わります)
| 項目 | クラウドAPI型(GPT/Claude/Gemini など) | ローカルLLM型(Gemma/Qwen/DeepSeek など) |
|---|---|---|
| 初期費用 | 0円 | 数十万〜(GPUマシン or Mac Studio 等) |
| 月額変動費 | トークン数 × 単価(=青天井) | 電気代+(場合により)運用代行費 |
| 応答品質 | フラッグシップモデルはトップクラス | モデルと設計次第。定型タスクなら十分 |
| 速度 | ネットワーク次第。レイテンシあり | ローカルGPUならかなり速い/CPUのみだと遅め |
| 機密性 | ベンダーポリシー依存。エンタープライズならかなり厳格 | データを外に出さない設計も可能だが、端末管理は自前 |
| 運用の手間 | ほぼゼロ(たまにバージョン指定変える程度) | インストール・更新・モデル差し替え・監視などが必要 |
ここで押さえておきたいのは、
- クラウドは「高品質+ノー運用」の代わりに、使うほどお金が増える構造
- ローカルは「運用コストと初期投資」と引き換えに、「1トークンあたりはほぼタダ」に近づける構造
ということです。
「どっちが得か?」は、“どれくらい使うか”と“どれくらい運用に時間を割けるか”の掛け算になります。
-2. ケーススタディ:月3万円・10万円・30万円の利用額で回収期間はどう変わる?
じゃあざっくり、3パターンで見てみます。
前提となるラフなモデル:
- API側:
- 月のAI費用(トークン課金+サブスク):3万 / 10万 / 30万円
- ローカル側:
- マシン:40万円(Mac Studioクラス or RTX 4080級PC)
- 電気代:月5,000円〜1万円(LLMをそこそこ回す前提)
「完全にAPIをゼロにする」のは非現実的なので、
“削れるのはAPI費用の7割”くらいと仮定します(高精度タスクなど3割はAPIに残すイメージ)。
ケースA:月3万円(ライト〜ミドルユーザー)
- 今:月3万円 × 12ヶ月 = 年36万円
- ローカル移行で7割削減できたと仮定すると:
- API:9,000円/月
- ローカル電気代:1万円/月
- 合計:約1.9万円/月 → 年22.8万円
年間での差額
- クラウド継続:36万円
- ハイブリッド+ローカル:22.8万円
- → 年間約13.2万円の削減
ここに初期投資40万円が乗るので、
- 40万円 ÷ 13.2万円 ≒ 約3年 でトントン
→ 個人で「仕事にも趣味にもガンガン使う」レベルならまだしも、
正直、「今すぐハイエンドマシン買おう!」とまでは言いにくいラインです。
ケースB:月10万円(ガチ開発チーム or 個人ガチ勢)
- 今:月10万円 × 12ヶ月 = 年120万円
- ローカル移行で7割削減:
- API:3万円/月
- ローカル電気代:1万円/月
- 合計:4万円/月 → 年48万円
年間での差額
- クラウド継続:120万円
- ハイブリッド+ローカル:48万円
- → 年間72万円の削減
初期投資40万円は、
- 40万円 ÷ 72万円 ≒ 0.55年(約6〜7ヶ月) で回収
→ ここまで使っているなら、半年〜1年のスパンでわりと堅い投資になってきます。
特に、3〜5人くらいのチームで1台のマシンをシェアしているなら、
「各自のAPI利用を合算した金額」が効いてくるので、回収はさらに早くなります。
ケースC:月30万円(すぐるさん寄りのヘビーユーザー)
これは、すぐるさんのケース(主参照:ポスト本体)に近いやつですね。
- 今:月30万円 × 12ヶ月 = 年360万円
- ローカル移行で7割削減:
- API:9万円/月
- ローカル電気代:1万円/月
- 合計:10万円/月 → 年120万円
年間での差額
- クラウド継続:360万円
- ハイブリッド+ローカル:120万円
- → 年間240万円の削減
初期投資40万円は、
- 40万円 ÷ 240万円 ≒ 0.17年(約2ヶ月)
このレベルになると、すぐるさんの言う
「このMac Studioは3ヶ月くらいで元が取れる計算!」
も、“かなり現実的なライン”として見えてきます。
もちろん実際の削減率や電気代で多少ブレますが、
APIをこれだけ燃やしているなら、「ローカル投資しない方がむしろもったいない」ゾーンです。
-3. 見落としやすい“隠れコスト”4選:電気代、メモリ不足、保守時間、モデル更新
ここまで読むと「よし、Mac Studioポチるか!」となりがちですが、
ローカル化には表に出にくいコストもちゃんとあります。
ざっくり4つ挙げておきます。
-
電気代・発熱
-
GPUを載せたマシンをほぼ常時フルロードで回すと、
想像以上に電気を食います。 -
特に自宅運用だと「PC本体よりエアコン代の方が効いてきた」パターンもあるので、
長時間フルで回すならオフィス/サーバールームでの運用も検討。 -
メモリ不足との戦い
-
モデルサイズによって必要メモリが変わります(参考:ローカルLLM完全ガイド)。
- 4B:8〜16GB
- 8B:16〜32GB
- 14B以上:32GB〜
-
「せっかく買ったのに、微妙にメモリ足りなくて一番使いたいモデルが載らない」という事故、
ローカル勢あるあるなので要注意です。 -
保守・アップデートの工数
-
APIなら「裏側が勝手に強くなる」のに対し、
ローカルは「自分でモデルを入れ替えないと進化しない」世界です。 -
Ollama や LM Studio がかなり楽にはしてくれてますが、
- 新モデル出たらpullして試す
- 以前のモデルとの互換性を確認
みたいな作業は、どうしても人がやることになります。
-
監視とトラブルシューティング
-
急に重くなった/落ちる/応答が妙に遅い、みたいなトラブルを
「誰が見るのか?」問題。 - 個人なら自分が見るしかないし、チームなら誰かが“AIインフラ担当”になるイメージです。
すぐるさんのような「もともと生成AIをいじり倒している人」は、
この辺りも趣味半分で乗りこなしている感じですが、
「AIは全部SaaSで任せたい」タイプの人にとっては、普通に負担になります。
-4. むしろAPI継続が正解なケース:高精度・長文・マルチモーダル重視の仕事
ここまでローカル寄りの話をしてきましたが、
正直言って、「ローカル化しない方がコスパも精神衛生も良い」ケースも普通にあります。
たとえば:
-
月あたりのAIコストが1〜2万円レベル
-
SaaS課金+たまのAPI利用くらいなら、
ローカル投資はまだ慌ててやらなくてOK。 -
まずは「呼び出し設計の最適化」でムダを削る方が早いです。
-
「とにかく精度と安定性が最優先」の仕事
-
クライアントワークで、直接お金をもらうレイヤーの成果物
(提案書、本番コード、契約書案など) -
ここは、まだ GPT-5 / Claude Opus / Gemini 3 Pro みたいな
フラッグシップAPIにお金を払う価値があります。 -
長文 or マルチモーダルをゴリゴリ使うケース
-
100ページ超のPDFまとめ
- 動画×テキスト×画像をまとめて扱う分析
-
こういうのは、現時点だとまだクラウド側がかなり有利。
-
運用に時間を割きたくない or 割けない組織
-
「インフラ担当を立てる余裕がない」
- 「そもそも社内にGPUマシン置ける文化じゃない」
みたいな組織は、無理してローカルに寄せると逆に足を引っ張ります。
章の小まとめ
ざっくりこんなイメージです。
- 月3万円前後
- まずは「呼び出し設計」「プロンプト設計」「ログ再利用」でムダを削るフェーズ
- ローカルLLMは、安いPC+小型モデルから軽く試すくらいでOK
- 月10万円前後
- 「ローカル投資 → 半年〜1年で回収」が見えてくるライン
- チームで使うなら、本気でローカル化を検討して良いゾーン
- 月30万円前後
- すぐるさんのような“3ヶ月でMac Studioがペイする世界”に入ってくる
- ここまで来たら、ローカル化しない理由を探す方が難しい
そして共通して言えるのは、
「どのモデルが安いか」より、
「そのモデルをどんな設計で、どれだけ叩いているか」がコストを決める
ということです。
次のセクションでは、
その「どんな設計で叩くか?」に直結する話として、
Gemma 4(実際は Gemma 3/3n 系)を中心としたローカルLLMが、“どんな実務タスクにハマりやすいか/向かないか”を具体的に仕分けていきます。
Gemma 4は実務で使える? 日本の現場でハマりやすい7つのタスクを向き・不向きで整理
すぐるさんのポスト(主参照:https://x.com/SuguruKun_ai/status/2040755405585084873)では、
「Gemma 4 を活用したAI節約術」
という表現が出てきます。
実際の技術スタックとしては、現状公開されているのは Gemma 3 / Gemma 3n 系(4B / 12B / 27B など)なので、
この記事では「Gemma 4 = Gemma 3/3n 世代の後継としての“ローカルGemma系”」というニュアンスで扱います。
で、みんなが一番気になっているのはここですよね。
「で、ローカルGemmaって、仕事でどこまで使えるの?」
ベンチマーク表を眺めるより、
「自分の業務のこのタスクにハマるかどうか」の方が100倍重要なので、
ここでは実務タスクベースで「向く/向かない」を切り分けてみます。
-1. 向いている仕事1〜4:議事録要約・問い合わせ分類・FAQ草案・コードの叩き台
まずは「ローカルGemmaに寄せると気持ちよくハマる4タスク」から。
① 議事録・チャットログの要約
Xでの現場感
- 社内・クライアント問わず、「会議は増える一方、議事録読む時間は減る一方」問題
- GPT / Claude にそのまま投げると、地味にトークン代が刺さる
事実ベース(Gemma系のスペック)
- Gemma 3 4B / 12B でも、要約タスクはかなり得意
(参考:Gemma 3 詳細解説 @ サイオス) - 128Kコンテキスト(テキスト長)に対応するサイズもあり、
会議1本分なら十分飲み込める
向いている理由
- 要約は「完璧な1文」を求めるより、「要点が押さえられていればOK」なケースが多い
- ローカルでバッチ的に何度回してもお金が増えないので、
「とりあえず全部の会議ログに要約を自動添付」がやりやすい
実務イメージ
- Zoom / Teamsの文字起こし → ローカルGemmaで要点3〜5個に圧縮
- 社内Slackチャンネル(#project-xxx)の1日分ログ → 「今日の進捗サマリ」を毎晩生成
このあたりは 「まず最初にローカル化する候補」として激推しです。
② 問い合わせ・チケットの分類(ラベリング)
よくある悩み
- ヘルプデスク/CSチーム/社内IT窓口に来る問い合わせを、
手動で「カテゴリ」や「優先度」に振り分けている - ここで毎日ちょっとずつ人間の時間が溶けていく
Gemma系での対応
- 自然文を「ラベル」にマッピングする tasks(テキスト分類)は、
4B〜8B級ローカルモデルがかなり得意 - Qwen系やNemotron系も強いですが、Gemma 3は140言語対応で日本語も普通に扱えるので、
社内向けツールとして十分戦えます
例:問い合わせ文を3分類するプロンプト
次の問い合わせ文を、以下の3つのカテゴリのいずれかに分類してください。 カテゴリ: - アカウント・ログイン - 請求・契約 - システム不具合 出力は JSON 形式で、"category" キーにカテゴリ名のみを入れてください。 問い合わせ文: """ <ここにユーザーからの問い合わせ本文> """
これをローカルGemmaに投げておけば、
- 月何万件という問い合わせの「一次ラベリング」をほぼタダで回せる
- 手動でのチェックだけ人間がやる
という運用が可能になります。
③ FAQ・マニュアルのドラフト生成
ここも「精度7〜8割でいいから、とにかく量をさばきたい」系の典型例です。
Xの空気感
- 「社内FAQをAIに作らせた」「操作マニュアルのドラフトをAIに書かせてから人間が整える」みたいな話はかなり増えている
ローカルGemmaでの向き・不向き
- 元となるナレッジ(過去のQA、マニュアル、仕様書など)をRAGで噛ませておけば、
4B〜12B級モデルでもそこそこまともなドラフトが出てきます。 - 完璧な日本語表現やニュアンスはクラウドAPIに軍配が上がりますが、
「とりあえず骨子を出してほしい」レベルならローカルで全然OK。
実務フローのイメージ
- 社内の既存マニュアル・FAQをベクタDBに突っ込む
- 「よくある問い合わせ」だけ抽出(分類タスクと組み合わせるとベスト)
- 各問い合わせに対して、Gemma + RAGで回答ドラフト生成
- 担当者がチェックして公開
ここも「APIでやると回数×トークン量で地味に高くなるゾーン」なので、
ローカルGemmaに寄せると嬉しいタイプです。
④ コードの叩き台生成(特に単体テスト・軽めのスクリプト)
すぐるさん自身も Claude Code ガチ勢 なので、
「コーディング系タスクをローカルGemmaにどこまで寄せるか」は超重要ポイント。
現状の肌感としては:
- プロダクションレベルの実装設計・高度なバグ解析
→ まだ Claude / GPT / Qwen-Coder クラスを使いたい - しかし、
- 単体テストのたたき台
- 単純な変換スクリプト
- 退屈なボイラープレート
くらいなら、Gemma 3 12Bクラスでも結構いける
例:pytest のひな形を作らせる
あなたはPythonエンジニアです。次の関数に対して pytest の単体テストコードの雛形を生成してください。 - 前提: - 外部APIには実際には接続せず、モックを使ってください。 - 異常系のテストケースも最低2つ含めてください。 対象コード:
<ここに関数定義>
これを「人がレビュー前提」の叩き台として使う分には、
ローカルGemmaでも十分なことが多いです。
-2. 向いている仕事5〜7:社内検索補助・RAGチャット・夜間バッチ処理
ここからは「回数が多いほどローカル化の恩恵がデカい」系の3つ。
⑤ 社内検索の“賢い補助”(ナレッジベースの自然文検索)
よくあるパターン
- Confluence / Notion / SharePoint / Google Drive に山ほどドキュメントがある
- しかし検索が弱くて、「どこに何が書いてあるか覚えてる人」がバス係数1
ローカルGemmaで何ができるか
- 文書本体は既存の全文検索エンジン(Elasticsearch / OpenSearch / Meilisearch 等)に任せる
- ヒットした候補から、「質問に関係ありそうな部分だけ抽出→要約」するのを
ローカルGemmaにやらせる
簡単なフロー例
- ユーザーのクエリを全文検索エンジンに投げる
- 上位5件の文書と、その本文を取得
- それを Gemma + 簡易RAG で要約して返す
RAGの実装そのものは API でもローカルでも同じですが、
「1検索あたり毎回数十〜数百行のテキストをLLMに投げる」設計は、
回数が増えると API だと普通に痛いです。
ここをローカルGemmaで回せれば、「社内検索ボット使い放題」に近づけます。
⑥ RAGチャットボット(社内向け)
すぐるさんのようにClaude Codeのログを勝手に「本」にするOSS(CC-books)もそうですが、
ログ・ナレッジ・議事録を「後からAIに聞ける状態」にしておくのは、もはや定番です。
ここでのポイントは、
- 社外向けのチャットボットなら品質のためにGPT/Claudeを採用すべき場面も多い
- ただ、社内向けで“ざっくり答えてくれればOK”なボットは、ローカルGemmaでも十分
という切り分け。
特に、夜中でも文句言わない後輩AI的に、
- 開発中の仕様の読み合わせ
- 過去のバグ報告を元に「似たような事例」を探す
- 社内ルールのFAQに答える
みたいな用途なら、Gemma+RAG構成でかなり快適に回せます。
⑦ 夜間・定期バッチ処理(要約・分類・変換)
最後は「人が寝てる間に回したい系」のやつです。
例:
- 毎晩、1日の Slack ログを集めて「チャンネルごとのハイライト」を自動生成
- 全ての Pull Request に「AIによる変更概要コメント」を自動で追加
- 監視ログから「気になるイベント候補」を抽出してSlack通知
こういうのをクラウドAPIでがっつりやると、
- 実行回数 × ログサイズ × 単価
でそれなりの課金爆弾になります。
一方、ローカルGemmaなら「どうせ夜間バッチなので多少遅くてもいい」ので、
CPUオンリーでも、時間をかけて処理させればコストほぼゼロに近いです。
- 速度が不要
- 数が多い
- 多少ミスっても致命傷にはならない(人間が後で見る)
という3条件が揃っているタスクは、
夜間バッチ×ローカルGemmaのド本命ゾーンです。
-3. 向かない仕事:高難度推論・厳密な実装支援・対外公開の最終成果物
逆に、「ここを無理にローカルGemmaでやろうとすると燃える」領域もちゃんとあります。
✕ 高難度の推論・数学・複雑ロジックの設計
- SWE-bench や数学系ベンチマークを見ると、
推論特化の DeepSeek-V3.2 / Nemotron 3 Nano ですら、
GPT-5 / Claude Opus クラスとはまだ差があります。 - 特に「仕様が曖昧なまま」「既存コードが複雑なまま」投げる系の相談は、
最上位APIの方が「変な方向に行きにくい」です。
プロジェクトの成否に関わる設計相談や、
複雑な競合条件がからむロジックのレビューなんかは、
まだ素直にクラウドAPIにお金を払っていい領域です。
✕ プロダクションコードの最終版を“丸ごと任せる”
- テストコードの叩き台、単純な変換系スクリプトくらいならローカルGemmaでも十分
- ただ、本番投入するコードをノーチェックで出力させるのは、どのモデルでも危険です
特に、外部サービス連携・セキュリティまわり・パフォーマンスがシビアな部分は、
- AI → 叩き台
- 人間 → 設計・レビュー・最適化
の流れを、ローカルでもクラウドでも徹底した方がいいです。
✕ 顧客に直接見せる提案書・資料・メール原文
- 品質の微差が信用に直結するアウトプット
(提案書、企画書、営業メール、広報文、プレスリリースなど) - ここでの「3%の差」は、ビジネス的にはかなり大きいことが多いです。
ローカルGemmaの日本語は実用範囲に入っていますが、
- トーンの調整
- 微妙なニュアンス
- 長文構成のうまさ
はまだ GPT-5 / Claude / Gemini Pro に一日の長があります。
ドラフトはローカルGemma+RAGで作り、最終版の磨き込みだけClaude/GPTに投げる
という二段構えが、コストと品質のバランス的にはオススメです。
-4. 30秒セルフ診断:あなたの業務はローカル向き? API向き?
ここまで読んで「うちのタスクだとどっち寄りかな?」と迷っている人向けに、
ざっくり自己診断を置いておきます。
それぞれ直感で◯×つけてみてください。
Q1. このタスクは、毎日/大量に発生しますか?
- はい → ローカル化のメリットが出やすい
- いいえ → APIのままでもコストインパクトは小さいかも
Q2. 多少のミスは人間のレビューで吸収できますか?
- はい → ローカルGemmaの出番
- いいえ → クラウドAPIの高精度を優先した方が安全
Q3. このタスクの結果は、社外の人の目に直接触れますか?
- はい → 最終版はAPI側で磨くのが安心
- いいえ → ローカル専用でもOK
Q4. 入力テキストは、最大でも数千〜数万トークン程度に収まりますか?
- はい → 4B〜12B級ローカルモデルで現実的
- いいえ → 100K〜1Mコンテキスト級が得意なクラウドに任せたい
Q5. 機密性が高く、クラウドに出したくないデータですか?
- はい → ローカルLLMを検討する強い動機になる
- いいえ → コストだけ見て判断してよい
◯が多いほど「ローカル向き」、×が多いほど「クラウドAPI向き」です。
両方混ざる場合は、
- 「頻度が高い」×「ミス許容度が高い」タスク
→ まずそこだけローカルGemmaに寄せてみる
から始めるのが、いちばん事故りにくい進め方かなと思います。
次のセクションでは、
「じゃあ実際にローカルGemma(+他のローカルLLM)をどう立ち上げるか」を、
Mac / Windows / Linux別に、Ollamaベースの最短ルートで書いていきます。
初心者でも試しやすい:Gemma 4系ローカルLLMの最短セットアップ手順【Mac/Windows/Linux対応】
すぐるさんのポスト(主参照:https://x.com/SuguruKun_ai/status/2040755405585084873)でも出てきた「Gemma 4(実態としては Gemma 3/3n 系)」ですが、
「いや、その前に “ローカルでLLM動かす”ってどうやるの…?」
というところで止まっている人も多い気がします。
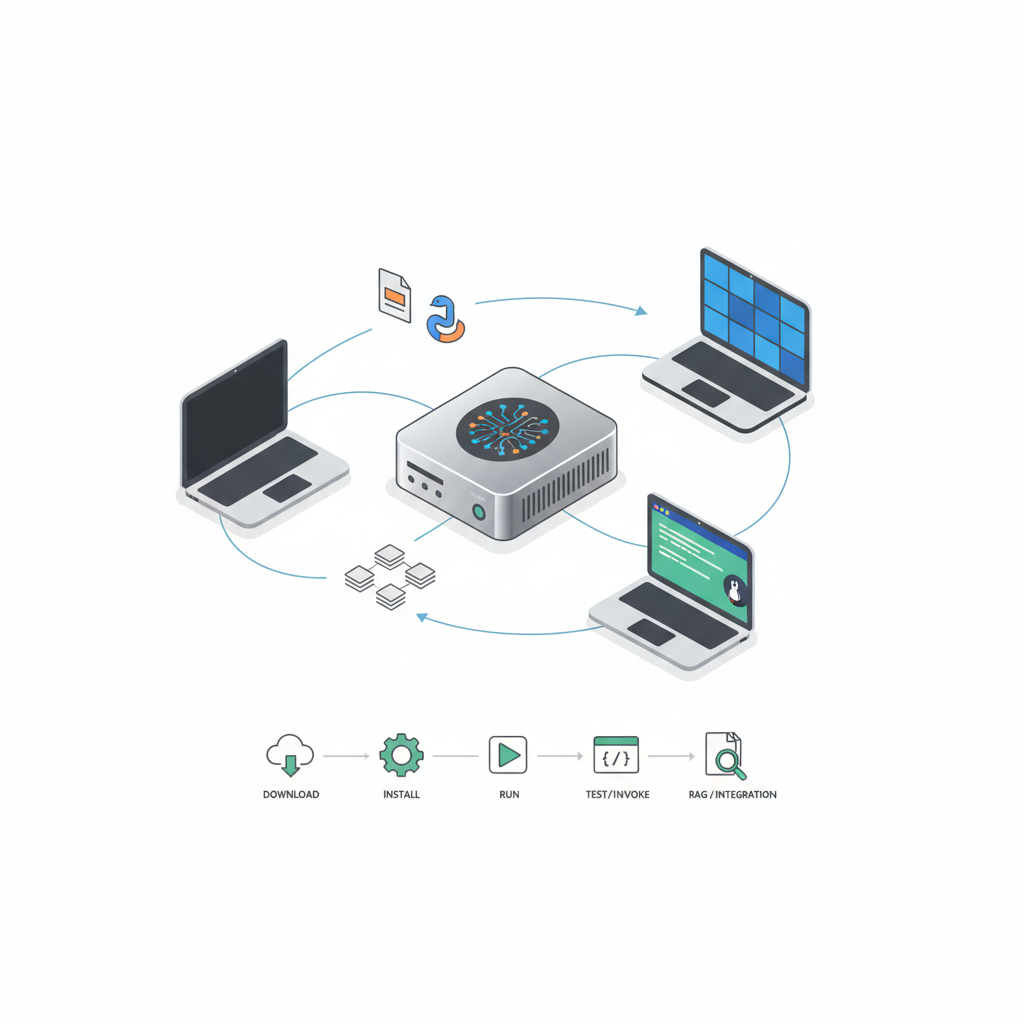
結論から言うと、Ollama 使えば「とりあえず動かすだけ」なら30分コースです。
Mac / Windows / Linux どれでもいけます。
ここでは、
- 予算別のざっくり構成イメージ
- Ollama でローカルモデルを立ち上げる 5 ステップ
- Python から叩く最小サンプル
- RAG で「ただのおしゃべり」から「社内検索ボット」に格上げする考え方
- よくハマるポイントと回避策
まで、一気に駆け抜けます。
-1. 予算別おすすめ構成3選:まず試す・しっかり回す・チームで使う
Xでの主張
- 「Mac Studio 買ったら3ヶ月で元取れた」
(主参照:すぐるさんのポスト)
ここをいきなり真似する前に、自分の用途×予算でざっくりターゲットを決めておくと失敗しにくいです。
パターンA:まず試す(個人・予算0〜5万円)
- 手元の PC のまま(MacBook / Windows ノート / Linux 機)
- 条件
- メモリ:16GB あればかなり楽、8GB でもギリ動く
- GPU:なくても OK(CPU 推論。遅くてもまずは動かせればいい)
- できること
- Gemma 3 4B クラス(4B モデルの量子化版)
- 要約・分類・軽いチャット・短いコードサンプルくらい
→ 「まずはローカルLLMってどんなもんか触ってみたい」なら、今のマシンで4Bモデルからで十分です。
パターンB:しっかり回す(個人・副業用、予算10〜25万円)
- 想定マシン
- メモリ:32GB 以上
- GPU:
- Mac:M2 Pro / M3 以上
- Windows:RTX 4060〜4070 クラス(8〜12GB VRAM)
- できること
- 4B〜8B クラスをサクサク
- 12B 級も量子化すればそこそこ動く
- コーディング補助・議事録要約・RAG チャットボットくらいまで実用範囲
→ 「副業・受託で毎日AIを触る」「社内のPoCを自分マシンで回したい」人は、このレンジが現実的なスイートスポットです。
※「量子化でどれだけVRAM/コストを削れるか」の実務寄りの論点(KVキャッシュ量子化など)は Google TurboQuantとは?KVキャッシュ量子化でLLMのVRAMを削る導入判断ポイント も参考になります。
パターンC:チームでガチ運用(3〜5人用、予算30〜60万円)
- 想定マシン
- メモリ:64GB 以上推奨
- GPU:
- RTX 4080〜4090 クラス(16〜24GB VRAM)
- or Mac Studio(M2 Ultra/M3 Max系)
- できること
- 12B〜24B クラスを複数モデル並行で
- RAG+エージェント系のサービスをチーム全員で共有
- 夜間バッチで大量ログ処理など
→ すぐるさんが言うような「Mac Studio 3ヶ月でペイ」ゾーンは、このクラスの使い方をしている人たちの話です。
ポイントは、いきなりCにジャンプしないことです。
まずは A か B で「4B〜8Bクラスを1つ動かしてみる」ところから始めると、
「あ、うちの使い方ならここまでで十分だな」とか、「いや、もっと積みたいな」が実感でわかります。
-2. セットアップ実例:Ollamaでローカルモデルを立ち上げるまでの5ステップ
ここからが実際の手順です。
Gemma 3 4B モデルを例に、Ollama で動かして API で叩ける状態までいきます。
Step 0. 事前チェック(OS別メモ)
- macOS
- Intel / Apple Silicon 両対応
brewが入っていると何かと楽- Windows 10/11
- 管理者権限でインストーラを実行できるか確認
- Linux (Ubuntu系想定)
curlが入っているか (which curlで確認)systemd使用中なら自動起動も簡単
Step 1. Ollama をインストール
公式のワンライナーが一番早いです(macOS / Linux)。
curl -fsSL https://ollama.com/install.sh | sh
Windows の場合は:
- 公式サイト https://ollama.com/ にアクセス
- 「Download for Windows」からインストーラを落とす
- Next 連打で完了
インストール後に、ターミナル/PowerShell でバージョン確認。
ollama --version
バージョンが出れば OK です。
Step 2. Gemma 系モデルを pull する
Gemma 3 (4B) の例:
ollama pull gemma3:4b
- 初回は数GB ダウンロードが走るので、回線にコーヒーを奢ってあげてください。
- 他にも Qwen3 や DeepSeek, Llama など色々ありますが、最初は 4B くらいからをおすすめします。
Step 3. 対話テスト:ローカルGemmaとおしゃべりする
モデルが入ったら、まずは CLI でおしゃべりしてみます。
ollama run gemma3:4b
すると対話プロンプトが開くので、適当に聞いてみましょう。
> こんにちは。あなたは何ができますか?
それっぽい自己紹介が返ってきたら成功です。
この時点で、「Gemma 3 4B が自分のマシンだけで動いている」状態です。
Step 4. API が立っているか確認する
Ollama はデフォルトでローカルに HTTP API を立ててくれます。
別のターミナルから、curl で軽く叩いてみましょう。
curl http://localhost:11434/api/generate -d '{
"model": "gemma3:4b",
"prompt": "日本語で短く自己紹介してください。"
}'
レスポンス例(抜粋):
{
"model": "gemma3:4b",
"created_at": "2026-04-05T12:34:56.789Z",
"response": "こんにちは、私はローカルで動作している言語モデルです。"
...
}
response にそれっぽい文が返ってくれば、API 経由でも利用可能になっています。
→ Cursor や VS Code 拡張(Continue / Cline)からも、このエンドポイントを叩けば Gemma が使えます。
Step 5. (任意)Windows / Linux でサービス常駐させる
GUI で立ち上げ直すのが面倒な人は、
- Windows:スタートアップ登録
- Linux:systemd サービス
で常駐させておくと楽です。
Linux(Ubuntu)の systemd サンプルだけ置いておきます。
/etc/systemd/system/ollama.service
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/local/bin/ollama serve Restart=always User=your-username WorkingDirectory=/home/your-username [Install] WantedBy=multi-user.target
有効化して起動:
sudo systemctl enable ollama sudo systemctl start ollama
-3. すぐ使えるPythonサンプル:要約・分類をローカルLLMに任せる
「動いた!で終わると、だいたい二度と触らなくなる」ので、
ここでそのまま業務や個人開発に組み込みやすい最小サンプルを書いておきます。
前提:pip install requests 済み。
import requests
import textwrap
OLLAMA_URL = "http://localhost:11434/api/generate"
MODEL_NAME = "gemma3:4b"
def call_llm(prompt: str) -> str:
payload = {
"model": MODEL_NAME,
"prompt": prompt,
"stream": False,
}
resp = requests.post(OLLAMA_URL, json=payload)
resp.raise_for_status()
data = resp.json()
return data["response"]
def summarize(text: str) -> str:
prompt = textwrap.dedent(f"""
次の文章を、重要なポイントを3つに絞って日本語で要約してください。
文章:
\"\"\"
{text}
\"\"\"
""")
return call_llm(prompt)
def classify_ticket(text: str) -> str:
prompt = textwrap.dedent(f"""
次の問い合わせ文を、以下のいずれかのカテゴリに分類してください。
- アカウント・ログイン
- 請求・契約
- システム不具合
出力はカテゴリ名のみを1行で返してください。
問い合わせ文:
\"\"\"
{text}
\"\"\"
""")
return call_llm(prompt).strip()
if __name__ == "__main__":
sample_text = "本日10時からのミーティングでは、新しい料金プランの案と、既存顧客への移行方針について議論しました。..."
print("要約結果:")
print(summarize(sample_text))
ticket = "昨日からログインしようとするとエラーが出て、マイページに入れません。パスワードリセットも試しましたが状況は変わりません。"
print("分類結果:")
print(classify_ticket(ticket))
これだけで、
- 議事録テキストを
summarize()に渡して要約 - 問い合わせ文を
classify_ticket()に渡してカテゴリ判定
が、すべてローカル Gemma 4B で完結します。
API キーもいりません。請求も飛んできません。
このサンプルをベースに:
- Slack Bot から呼ぶ
- 社内Webツールから呼ぶ
- バッチ処理で1日分のログを全部まとめて回す
みたいに拡張していくのが王道ルートです。
-4. RAGを足すと何が変わる? ローカルでも精度を底上げする基本設計
すぐるさんの世界観だと、「Claude Code のログが勝手に“本”になる OSS(CC-books)」のように、
「自分のデータ + LLM」で価値を出していくのが鍵になっています。
ここで出てくるのが RAG(Retrieval-Augmented Generation)です。
ざっくり言うと、
- まず検索で“それっぽい情報”を集める
- その情報をプロンプトに添えて LLM に渡す
→ “勘だけで答える”のではなく、“ちゃんと資料見ながら答えてもらう”
という構造です。
ローカルGemmaと相性がいい理由:
- モデル単体の知識には限界があるが、
社内ドキュメントやログと組み合わせると精度が一気に上がる - 検索部分は SQLite / Meilisearch / Qdrant / Chroma など、
軽量なOSSで十分(最初は SQLite + いい感じに全文検索でもOK)
超ざっくり構成イメージ:
- ドキュメント(社内Wiki、議事録、仕様書など)を小さめのチャンクに分ける
- 各チャンクを埋め込み(embedding)してベクタDBに格納
- ユーザーの質問文を埋め込み→類似チャンク上位N件を取得
- そのチャンク本文+質問文を、ローカルGemmaに渡す
コード例を書くと長くなるので割愛しますが、
まずは「LlamaIndex / LangChain で RAG サンプルを動かし、
モデル名だけ gemma3:4b に差し替える」ところから始めるのがおすすめです。
-5. よくある詰まりポイント5選:遅い・落ちる・賢くない・日本語が揺れる・メモリ足りない
最後に、最初にだいたいみんながハマるポイントと、軽めの対策をまとめておきます。
1. とにかく遅い(CPU 100%なのに返ってこない)
- 原因:
- GPU なし&4B 以上のモデルをフル精度で回している
- 対策:
- 量子化版(
q4_0など)があるならそちらを使う - まずは 2B〜4B クラスで試す
- 長いテキストをそのまま突っ込まず、「要点だけ」先に絞る
2. メモリ不足で落ちる or 起動しない
- 原因:
- 8B〜12B モデルを 16GB 未満で無理やり動かそうとしている
- 対策:
- まず 4B 以下から試す
- 32GB 未満の環境で 12B 以上は「動いたらラッキー」くらいに思っておく
- Mac の場合、他アプリを閉じてメモリを空けてから実行
3. 思ったより賢くない/クラウドより明らかに劣る
- 原因:
- モデルサイズの限界+プロンプト設計が雑
- 対策:
- 期待値を「叩き台生成」に下げる
- 役割・制約・出力形式をプロンプトにちゃんと書く
- RAG で手元の資料を一緒に渡す
4. 日本語が微妙に変 or 英語混じりになる
- 原因:
- 英語中心で学習されたモデルは、日本語がやや弱いこともある
- 対策:
- 日本語強めの Qwen3 系や Nemotron 系も試してみる
- プロンプトの先頭で「日本語で回答してください」を入れる
- どうしても気になるところは、最後だけ GPT / Claude に「校正だけ」頼む
5. モデル更新が追えずに放置されがち
- 原因:
- 手動で
ollama pullするのがだんだん面倒になる - 対策:
- 「本番用モデル」は半年に1回くらいの更新で割り切る
- 検証環境だけ新モデルを試して、よければ本番に上げるルールにする
章の小まとめ
- すぐるさん級の「月30万→Mac Studio3ヶ月でペイ」はヘビーユーザーの世界
- その手前の「議事録要約だけ」「問い合わせ分類だけ」なら、
今のPC+Ollama+4Bモデルで十分 - 手順としては
- Ollama を入れる
ollama pull gemma3:4bollama run gemma3:4b- Python サンプルを1つ動かす
までやれば「自分のマシンで動く“小さめGemma”」が手に入る
『モデル選び』だけでは節約できない? 生成AIコストを左右するアーキテクチャ設計の新常識
すぐるさんのポスト(主参照:https://x.com/SuguruKun_ai/status/2040755405585084873)だと、
「Anthropicトークン代 月30万円 → Gemma 4系ローカル運用 → 月0円になった」
という“モデル乗り換え”のインパクトが前面に出ています。
ただ、ここまで読んできた人はもう薄々気づいていると思うんですが、
本当に効いているのは「モデル名」だけじゃなくて、「呼び出し方」と「アーキテクチャ」の方
なんですよね。
極端な話、
GPT-5 を使っていても呼び出し設計がうまければそこまで燃えないし、
逆にローカルLLMでも、設計が雑だとマシンが悲鳴をあげます。
このセクションでは、
- Xで話題になりやすい「モデル変えたら安くなった」話と、
- 実務で効いてくる「呼び出し設計・ログ設計・エージェント設計」
を分けて考えつつ、「2026年のコスパ設計はここを押さえようぜ」という4ポイントを書いていきます。
-1. ログはコスト削減の武器になる:同じ失敗を何度も課金しない仕組みへ
Xでよく見るパターン
- 「このプロンプトいい感じにハマる!」→ スクショ or ノートにメモ
- でも次の案件や別のエージェントでは、またゼロから試行錯誤
結果として、
- 似たようなタスクに毎回「探索コスト+トークン代」を払っている
- けどその“勝ちパターン”が資産化されていない
というもったいない状態が起きがちです。
事実として確認できる範囲
- すぐるさん自身も、Claude Code のログを本にしてしまう OSS「CC-books」を公開しています
(参照:CC-books公開ポスト) /daily-flipbookで「今日のセッション1冊分」- 本棚UIでストックが溜まっていく
- これは「知識のアーカイブ」としても面白いんですが、
「同じようなやり取りを何度も繰り返さないための仕組み」とも読めます。
実務への落とし込み(エンジニアがやること)
コスト視点でログを扱うなら、少なくともこの2ステップはやりたいです。
-
「うまくいった会話」だけを抜き出す場所を作る
-
例:
- Git リポジトリ内に
ai_prompts/ディレクトリを作る - Notion / Confluence に「AIレシピ集」を1ページ作る
- Git リポジトリ内に
-
「タスクの説明」「プロンプト」「良い出力例」「使ったモデル」をセットで保存
-
エージェントやツール側で“勝ちパターン”をテンプレ化する
-
例:
- CLIツールに
--prompt profile_nameみたいなオプションを用意しておく - Web UI側で「用途別テンプレ(要約/レビュー/テスト生成…)」をプルダウンにする
- CLIツールに
こうしておくと、
- 1回目:探索コスト + トークン代(必要経費)
- 2回目以降:テンプレ+微調整だけ(= トークン代も試行回数も減る)
という構造にできます。
「勝ちログをどう溜めるか?」は、そのまま「同じ失敗に何回課金するか?」の話なので、
節約のためにも、精神衛生のためにも、ちゃんと整備しておく価値があります。
-2. AIコーディング支援の改造熱が示すもの:もう“そのまま使う”時代ではない
最近のXを眺めていると、
- Cursor をローカルLLMとつなぐための設定記事
- Claude Codeクライアントをリビルドして OSS 化した話(om_patel5 さんのポスト)
- 「CC-books」のように Claude Code のログを可視化・資産化する OSS
など、「既製ツールをそのまま使う」から一歩進んで、
「自分のワークフローにフィットするように改造する」動きがかなり増えています。
これは単に「ハックして遊んでいる」だけじゃなくて、
- 高いAPIを“丸投げ”で使う時代から、
- “どういうフローで、どういうモデルを、どのタイミングで叩くか”を設計する時代
にシフトしつつある兆候だと感じています。
実務への落とし込み(エンジニアがやること)
- 「エディタにAIが付いてくる」前提から、「AIを中心に開発環境を組む」前提へ頭を切り替える
たとえば:
- コーディングエージェント用に専用の「作業ディレクトリ」「タスクキュー」「ログビューア」を用意する
- 「コード補完」用プロンプトと、「リファクタ提案」用プロンプトを分離して設計する
-
Cursor / Claude Code / Cline / Continue などを、「1ツール完結」ではなくて役割分担で使い分ける
-
ヘビーに叩くところほど、ローカルモデル or 安価モデルに“逃がす”設計を先に決めておく
例:
- コードベースのインデックス生成・解析 → ローカルLLM(Qwen3-14B, Gemma 3 12B)
- 実際のバグ修正プラン・設計レビュー → Claude / GPT
これだけで、「なんとなく全部 Sonnet / GPT-5 でやってみるか」エンジニアリングから抜け出せます。
-3. 高いのはモデル単価だけじゃない:無駄なループ、長すぎる履歴、雑な再送が犯人かも
すぐるさんの「月30万円」のケースみたいな話を聞くと、
つい「Anthropic の単価が高いからだ」と思いがちですが、
実際には「設計由来のムダ遣い」がかなり混ざっていることが多いです。
よくあるパターン:
- 会話履歴を毎回全部そのまま送っている
- チャットUIで「過去50往復分」をそのままcontextに乗せ続ける
-
結果、後半になればなるほど1リクエストあたりのトークン数が爆増
-
エージェントが同じツールを何度も叩き直している
- “プラン→実行→確認→やっぱり別案→実行…”を、
LLM 内ループで延々繰り返す -
人間目線だと「そこまで悩まなくていいからw」というところまで考えてしまう
-
うまくいかなかったときに“再試行”を雑に設計している
- 「エラーが返ってきたら、同じプロンプトでもう一回」みたいな再送
- 原因を変えない再試行は、たいていお金だけ増える
事実として確認できる範囲
- vLLM / llama.cpp / LM Studio などの実運用記事でも、
「トークン単価よりも、トークン総量 = context 設計がコストを左右する」と何度も指摘されています(例:2026年ローカルLLM事情)
実務への落とし込み(エンジニアがやること)
「モデル単価より前に、この3つをチェックする」だけでだいぶ変わります。
-
会話履歴の「要約メモリ」を入れる
-
10往復に1回くらい、「ここまでの会話の要点を200文字にまとめて」と LLM に要約させる
- 以降のプロンプトでは、元の履歴を削って要約だけ載せる
-
これで context トークンをかなり削れます
-
エージェントの max_steps / max_tool_calls を決める
-
例:
- 1タスクあたり最大10ステップまで
- 同じツールの再実行は3回まで
-
「そこまで悩むなら一旦人間に返せ」というガードレールを付けるだけで、
ループ地獄をだいぶ防げます。 -
再試行ロジックに“条件分岐”を追加する
-
単純な再送ではなく、
- 「タイムアウトならレートを落として再試行」
- 「バリデーションエラーならプロンプトを修正して再試行」
- それでもダメなら「人間レビュー」にフォールバック
「モデルを安いのに変えたのに請求があんまり減らない」パターンは、
だいたいこの3つのどこかが雑です。
-4. 筆者の見立て:2026年以降の本命は『クラウド×ローカル×資産化』の三層構成
すぐるさんの「Mac Studio で元取った」話は、象徴としてめちゃくちゃ分かりやすいんですが、
それをそのまま “ハイエンドマシン必須論” に読み替えるのは危ないかなと。
僕の感覚だと、2026年以降の“勝ちパターン”はだいたいこんな三層構成に落ち着きそうです。
-
クラウド層:フラッグシップモデルで“ここぞ”にだけ課金する
-
GPT-5 / Claude Opus / Gemini 3 Pro / DeepSeek-V3.2 など
-
使いどころ:
- 高難度推論
- 対外向け成果物の最終チェック
- 長大コンテキスト・マルチモーダル
-
ローカル層:Gemma / Qwen / DeepSeek-R1 などで“日常的な反復作業”を回す
-
会議要約、FAQドラフト、ラベリング、軽いコード補助、RAGチャットボット…
-
使いどころ:
- 回数が多い
- 多少ミスっても人間レビューで吸収できる
- 機密性が高い
-
資産化層:ログ・テンプレ・ナレッジを“二度とゼロから書かない”形で貯める
-
CC-books 的なログアーカイブ
- 用途別プロンプトテンプレ集
- 社内RAG用のベクタDB
- これらがあることで、
- トークン消費(再試行回数)が減る
- エージェント設計の再利用性が上がる
この三層がちゃんと噛み合うと、
- クラウドの請求は「ここぞの一撃」のみに絞られる
- ローカルは「黙々と回す日常業務」の受け皿になる
- ログ/テンプレは「次のプロジェクトの初速」を上げる
という構造になっていきます。
AIエージェントの費用を本気で下げる4つのコツ:モデル変更より効く設計改善とは
すぐるさんのポスト(主参照:https://x.com/SuguruKun_ai/status/2040755405585084873)だと、
「AIのトークン代が月30万円 → Gemma 4系ローカル運用で月0円になった」
という、“モデル乗り換えインパクト”が前面に出ています。
でも、ここまで読んできた人はもう気づいていると思いますが、
本当に効いているのは「モデル名」だけじゃなくて、「エージェントの設計」そのものです。
- 会話履歴をどう扱うか
- どのタスクをどのモデルに振るか
- どれくらい回しているかを可視化しているか
- 成功パターンをちゃんとストックしているか
このあたりが雑なまま「モデルだけ変えた」のでは、
請求グラフの傾きはほとんど変わりません。
ここでは、エージェント設計の観点から、
モデル変更より効く4つのコスト削減テクを整理していきます。
-1. コツ1:毎回フル履歴を投げない—要約メモリでトークンを痩せさせる
Xでよく見る“やりがち設計”:
- チャットっぽいUIでエージェントを作った結果、
- 過去の全メッセージを
messagesにそのまま積み続ける - 50往復くらいしたあたりで、1リクエストあたり数万トークンに膨張
- ユーザーの体感は「なんか最近ちょっと遅いな」くらい
- でも請求はちゃんと増え続ける
エージェントにとって一番高いのは、「あまり意味のなくなった履歴を延々と抱え続けること」です。
実務への落とし込み(エンジニアがやること)
ポイントは「フル履歴」→「要約メモリ+最近の生ログ」という2段構造にすることです。
イメージ:
- 会話が10往復くらい進んだら、LLM自身にこう頼む:
ここまでの会話の要点を、後から思い出せる程度に200〜300文字で日本語要約してください。 - 合意済みの前提 - ユーザーの目的 - これからやろうとしているタスク を含めてください。
- 返ってきた要約を
memory_summaryみたいなフィールドに保存 - 以降のリクエストでは、
- フル履歴のうち「直近 3〜5往復」だけをそのまま載せる
- それ以前のやり取りは、要約だけを
systemorassistantメッセージに埋め込む
疑似コードで書くとこんな感じです(Python 風):
def build_messages(summary: str, recent_history: list[dict], user_input: str):
system = {
"role": "system",
"content": f"これまでの会話の要点は次の通りです:\n{summary}\n\nこの要約を前提として、続きの会話に回答してください。"
}
return [system] + recent_history + [{"role": "user", "content": user_input}]
メリット:
- 「今の話題に必要な文脈」は残しつつ、トークンはかなり痩せる
- エージェントが長期の経緯をそれなりに覚えつつ、請求が爆増しにくくなる
Xでバズる「月30万」クラスの請求は、だいたいこの履歴膨張+エージェントループが合わさった産物です。
モデル替えより先に、ここをいじるのがコスパ的には正解です。
-2. コツ2:軽作業は軽量モデルへ—ルーティング設計でコスパを最大化
すぐるさんのケース(主参照ポスト)だと、「Claude で全部やってたのを Gemma 系ローカルに振り替えた」という話になっていましたが、
実務的には「全部ローカル」より、「軽い処理だけローカルに逃がす」構成が多いと思います。
Xでの主張(一般的な空気感):
- 「推論タスクは DeepSeek-V3.2 で十分では?」
- 「コード補助は Qwen3-Coder でいける」
- 「チャットは安い mini で / 難しいときだけ big に投げる」
ここをエージェント設計に落とすと、
「タスクごとにモデルを振り分けるルーティング層」を作ることになります。
例:3レベルのモデル構成
- L1:軽量モデル(ローカル or 安価API)
- 用途:
- テキストの整形(箇条書き化・敬語変換)
- ラベリング・分類
- 簡単な要約
-
例:
- Gemma 3 4B / Qwen3-1.7B / GPT-4o mini
-
L2:中堅モデル(そこそこ高性能+そこそこ高価)
- 用途:
- コード補助の叩き台
- 複数文書を跨いだ要約・比較
-
例:
- Qwen3-14B / gpt-oss-20b / Claude Sonnet クラス
-
L3:フラッグシップモデル(高性能+高価)
- 用途:
- 難度高めの設計レビュー
- 顧客向け資料の最終ブラッシュアップ
- 例:
- GPT-5.2 / Claude Opus 4.5 / Gemini 3 Pro
エージェント側では、
- 最初に「どのレベルのモデルが適切か」を軽く判定(これ自体は軽量モデルでOK)
- L1 でいけそうならそのまま完了
- L1 で怪しかったら L2 or L3 にエスカレーション
という多段階ルーティングをするイメージです。
実務への落とし込み(エンジニアがやること)
- まず、自分のエージェントがやっているタスクを棚卸しして、
- 「整形・要約・分類系」
- 「生成・リファクタ系」
- 「推論・設計判断系」
に分ける - それぞれに「最低限このレベルのモデルが必要」というラインを決める
- コード上で
call_llm(task_type, payload)的な共通関数を作り、 task_typeごとに裏で使うモデルを切り替える
これだけでも、
- 以前:全部 GPT-5 / Claude Opus
- 以後:7割はローカルGemma / Qwen、2割は中堅、1割だけフラッグシップ
みたいな構成に寄せることができます。
-3. コツ3:可視化しない節約は運任せ—高額リクエストを計測して潰す
Xでの「月◯万円燃やした」ポストを見ていると、
- 「昨日のコミットがヤバかった」感覚はある
- でも「どのエンドポイントが」「どのタスクで」どれくらい燃えたかは曖昧
というケースがめちゃくちゃ多いです。
ログがない節約は、ぶっちゃけただの運ゲーです。
事実として確認できる範囲
- vLLM / LM Studio / 各種プロキシツールには、
API呼び出しのログ・メトリクスを吐き出す仕組みがだいたい入っています - 2026年ローカルLLM記事(参考)でも、
「高負荷時のスループット計測」や「MoEモデルのCPU offloading時の速度」などの数値をちゃんと取って比較しています
実務への落とし込み(エンジニアがやること)
最低限これだけはやっておくと、改善サイクルが回しやすくなります。
-
APIプロキシ or ミドルウェアで、「1リクエストあたりのトークン数+レスポンス時間」を記録する
-
自前で書いてもいいし、既存ツールを挟んでもOK
-
出力形式は JSON / CSV などなんでもいいので、とにかく残す
-
「高額っぽいリクエスト」をランキングで出す
たとえば:
SELECT
endpoint,
task_type,
COUNT(*) AS calls,
SUM(input_tokens + output_tokens) AS total_tokens
FROM logs
GROUP BY endpoint, task_type
ORDER BY total_tokens DESC
LIMIT 20;
みたいなクエリで、「どのタスクが一番トークンを消費しているか」を可視化。
-
上位から順に、“なぜ高いのか”を設計レベルで見直す
-
履歴が長すぎる → 要約メモリを導入
- タスクに対してモデルが過剰 → ルーティングで軽量モデルに寄せる
- 再試行が多すぎる → エラー処理をちゃんと書き直す
「よくわからんけど月30万飛んだ」から、
「この3パターンのタスクが、全体の7割燃やしてる」まで分かれば、
一気に“エンジニアリング対象”になります。
-4. コツ4:勝ちプロンプトを資産化して“毎回ゼロから考える病”を卒業する
最後のコツは、精神論っぽく見えて実はかなりコストに効きます。
X で生成AI界隈を追っていると、
- 「◯◯タスク最強プロンプト」「この一文足すだけで精度爆上がり」的なTips
- 「プロンプトギャラリー」「レシピ集」がめちゃくちゃシェアされている
一方で、自分のチームの“勝ちプロンプト”はその場限りになりがちです。
- Slack/Notionに貼ったまま流れていく
- 口頭で「この前のやつ良かったよ」で終わる
これをやっていると、当然ですが毎回試行錯誤 → 毎回トークン消費になります。
実務への落とし込み(エンジニアがやること)
テンプレ化とインターフェース化、この2つだけはやっておきたいです。
- 用途別テンプレを決める
例:
summarize_meeting:会議ログ要約review_code:コードレビューコメント生成generate_tests:単体テスト叩き台classify_ticket:問い合わせラベリング
それぞれについて、
- 役割(“あなたは◯◯です”)
- 入力フォーマット
- 出力フォーマット
- 禁止事項(嘘を書かない、答えられないときは謝る 等)
を1つのテンプレとして決め打ちしてしまう。
- コード側で「プロンプトID」で呼び出せるようにする
擬似コード:
PROMPTS = load_prompts_from_yaml("prompts.yaml")
def call_task(task_id: str, **kwargs):
template = PROMPTS[task_id]
prompt = template.format(**kwargs)
return call_llm(prompt)
みたいな仕組みを作っておけば、
- 「テンプレを改良したい」ときは Yaml/JSON 側だけいじる
-
コード側は
call_task("summarize_meeting", text=...)のままでOK -
“勝ちテンプレ”をみんなで育てる文化を作る
-
うまくいったプロンプトは必ずテンプレに昇格させる
- 変更履歴をGitで追う
- たまに「プロンプトレビュー会」をやる
これをやると、
- 無駄な試行錯誤(= 無駄なトークン消費)
- 無駄なエージェント設計ミス
が自然と減っていきます。
すぐるさんの「CC-books」(Claude Codeログを「本」にするOSS)も、
ログ資産化の一種ですが、僕らが真似するなら「プロンプト・レシピの資産化」もセットでやるべきです。
日本のエンジニアはどう動くべき? 個人開発・副業・社内導入の3パターンで最適解を整理
すぐるさんのポスト(主参照:「AIのトークン代が月30万円かかってたけど〜」)を見て、
- 「うちもMac Studio買ったほうがいいのかな…?」
- 「Gemma 4入れればAI費用ゼロになるんでしょ?」
- 「上司にどう説明したら稟議通るんだこれ」
みたいなモヤモヤを抱えた人、多いと思います。
でも、「最適解」って、個人開発・副業・社内導入でまったく違うんですよね。
ここでは、
- 個人開発
- 副業・受託
- 会社/組織での導入
の3パターンに分けて、それぞれ「明日からどう動くか」レベルまで落とし込んで整理していきます。
-1. ケース1:個人開発なら、まずは“1つの定型作業”だけローカル化する
個人開発者/フリーランス予備軍のよくあるパターン:
- ChatGPT Plus や Claude Pro に月3,000〜5,000円
- たまに API も触ってみる
- 「でもMac Studioクラスを買うほどではないよなあ…」
このフェーズでいきなり「全部ローカル化するぞ!」はほぼ確実に燃えます。
おすすめは、“1つの定型作業”だけローカル化してみること。
具体的な候補:
- ブログ用の下書き要約
- 技術記事を読む前の「ざっくり要点抽出」
- 勉強会・社内MTGの議事録要約
- GitHub Issue やPRの「サマリ文」生成
- 個人プロジェクトのテストコードたたき台
やることはシンプルです。
- 「毎週必ずやっているAIタスク」を1つ書き出す
例:「勉強会の議事録を毎回GPTに投げて要約させている」
-
そのタスクだけ、Ollama+Gemma 4B に差し替えてみる
-
この記事の手順どおり:
ollama pull gemma3:4b- Pythonサンプルの
summarize()に置き換え
-
1ヶ月くらい動かしてみて、「体感」と「請求」を見比べる
-
体感:
- 要約の質はどうか?
- ローカルでも十分? それとも明らかにクラウドの方が嬉しい?
- 請求:
- ChatGPT/Claude の利用額はどれくらい減ったか?
ここで、
- 「質も速度もローカルで十分」 → そのタスクは完全ローカル化
- 「最後の微調整だけGPT/Claudeにやらせたい」 →
ローカルGemmaで叩き台 → GPT で仕上げ、という二段構え
みたいに、「1タスクずつハイブリッド構成にしていく」のが現実的です。
いきなり Mac Studio をポチるかどうかは、
この「1タスク検証」を2〜3個回してから決めても全然遅くありません。
-2. ケース2:副業・受託なら、粗利を守るためにAI費用をブレにくくする
副業・フリーランス・小規模受託チームの場合、
AI費用は「案件の利益率を直撃する変動費」になります。
Xでもよく見ますが、
- 「見積り時はAI費用ほぼゼロ想定 → 実務でガンガン叩いたら利益が溶けた」
- 「単価5万円のLP制作案件なのに、AIに8,000円くらい払ってた」
みたいな事故、普通に起こりがちです。
すぐるさんのケース(主参照ポスト)だと、
- 月30万円のAnthropicトークン代
- = ある意味「案件の粗利を食いまくっていた変動費」
を、「Mac Studio+ローカルGemmaでほぼ固定費化した」とも読めます。
副業/受託でやるべきは、
「案件ごとに AI費用がブレないようにする」=「変動費の一部を固定費にする」
です。
実務への落とし込み:
-
まず「1案件あたりどれくらいAIを使っているか」をざっくり書き出す
-
例:Webアプリ開発 50万円/件 の場合
- 要件整理:プロンプト生成・要約 → 30回
- 設計レビュー:コードレビュー支援 → 20回
- 実装補助:コーディングアシスト → 毎日ガンガン(感覚値)
-
「どこで一番AIを叩いているか」がなんとなく見えてくるはずです。
-
“単価は低いけど回数が多い”タスクをローカル化候補にする
-
例:
- Issue 要約
- テストコードたたき台
- ドキュメントの文言調整
-
ここをローカルGemma / Qwen に寄せるだけで、
1案件あたり数千円〜1万円レベルの変動費削減が見えてきます。 -
見積書テンプレに「AI利用枠」を項目として入れておく
-
例:
- 「AIアシスタント利用・上限◯円まで費用に含む」
(超えた分をどうするかは事前に決めておく)
- 「AIアシスタント利用・上限◯円まで費用に含む」
- あるいは:
- 「AI利用費は月額◯円を固定費として計上」「それ以上は原則ローカルで対応」
副業・受託の場合、“利益の読みやすさ”はかなり重要な武器です。
- ローカルLLMを入れる=「イケてるエンジニアっぽいから」ではなく、
- 「案件ごとの粗利を安定させるためのインフラ投資」
として捉え直すと、
「Mac Studio買う/GPU鯖借りる」の判断もしやすくなります。
-3. ケース3:社内導入なら、コスト削減より先にガバナンス設計を固める
最後が一番ややこしくて、一番インパクトが大きいところです。
企業内でのAI導入/ローカルLLM導入ですね。
Xの空気感:
- 「API利用料が高すぎるからローカルLLMにしよう」
- 「クラウドに機密情報を出したくないからオンプレで」
- 「でも正直、誰がどう使ってるのかよく分からない」
このフェーズで一番やっちゃいけないのは、
「節約だけを旗にして、ガバナンスを後回しにする」ことです。
すぐるさんの「月30万→Mac Studio」話(主参照)も、
個人〜小規模チームだからこそスピード感で動けたわけで、
企業だともう1〜2段階足場を作る必要があります。
社内導入でまず整えるべき項目:
-
機密情報の扱い方(データフロー図レベル)
-
どのデータが
- ローカルLLMにだけ渡されるのか
- クラウドLLMにも渡されるのか
-
どのレイヤーで
- マスキング
- 匿名化
- ログ削除
を行うのか
-
ログ・監査のポリシー
-
誰が
- どのモデルに
- どんなプロンプトを送り
- どんな出力を得たか
を、どの粒度で・どれくらい保存するか。
-
ログを
- セキュリティ監査用の“証跡”としてだけ使うのか
- ナレッジ/プロンプト資産としても使うのか
-
出力責任・検証プロセス
-
「AIの出力をそのまま社外に出してはいけない」
(これは総務省+経産省のAI事業者ガイドラインにも近い発想です) -
どのレベルの成果物までは
- 担当者チェック
- 上長チェック
が必須なのか
-
モデル更新・差し替えの手順
-
どの環境で検証し
- どういう基準で本番採用し
- いつ・どうやってロールバックするか
この辺りは、総務省+経産省の「AI事業者ガイドライン」最新版(1.2版)が
AIエージェントやフィジカルAIの定義も含めて整理しているので(参照:関連Xポスト)、
法務・情シスと一緒に一度は目を通しておくことをおすすめします。
実務への落とし込み:
- フェーズ1(ルール作り)
- 上記4項目+「利用目的・対象部門・対象業務」をざっくりドキュメント化
-
小さくてもいいので、「AI利用ポリシー/ガイドライン」を1枚にまとめる
-
フェーズ2(小さなPoC)
- 対象業務を「社内向け」「機密低め」「失敗許容度高め」に絞る
- 例:
- 社内FAQボット
- マニュアル生成のドラフト
- 社内レポートの要約
-
ここでローカルGemma+クラウドAPIのハイブリッドを試しつつ、
- コスト
- 性能
- ユーザー体験
を計測
-
フェーズ3(インフラ+ガバナンス本格整備)
- PoCの結果をもとに、
- 「月◯万まではこの構成でOK」
- 「このレベルの機密データはローカル必須」
という線引きを決める
- その上で、正式にローカルLLM環境(オンプレ or VPC)に投資するか判断
「節約&セキュリティ」の話は上層部にも刺さりやすいですが、
“どこまでやるか”を数字とルールで決めてから投資するのが、
社内導入の一番の肝です。
-4. 上司・決裁者にどう説明する? 稟議が通りやすい3つの伝え方
最後に、「これ上にどう説明すればええねん…」問題。
すぐるさんレベルのヘビーユーザーだと、
「Anthropicに3ヶ月で90万円払うくらいならMac Studioの方が安いっす」
というインパクトだけで押し切れるかもしれませんが、
普通の会社だと、それだけだと稟議はまず通りません。
日本の組織で通りやすいのは、この3軸です。
-
年間コストの予測性
-
今のままAPI一択だと:
- 利用拡大に比例して、コストが青天井
- 来期予算が立てにくい
- ローカルLLM+ハイブリッド構成だと:
- 「ハード代 + 月◯万円までのAPI」という上限を決めやすい
-
→ 決裁者にとっては、「予算を読みやすい」のが一番安心材料です。
-
情報管理のしやすさ
-
「全部クラウドに投げてます」だと:
- ベンダー側のポリシー変更に振り回されがち
- ローカルLLMを組み合わせると:
- 「この種類のデータだけは外に出さない」という線引きができる
-
ガイドライン(総務省+経産省)や社内規程との整合性も取りやすい。
-
作業時間の削減=人件費の削減 or 付加価値業務へのシフト
-
具体的なPoC結果として、
- 「議事録作成の平均時間が30分→10分になった」
- 「問い合わせの一次振り分けが自動化されて、担当者の時間が月◯時間浮いた」
- これをお金に換算して示すと、
「初期投資◯◯万円 vs 年間で◯◯万円分の人件費削減 or 創出」の構図にできます。
プレゼンのフレーズとしては、たとえばこんな感じです。
- 今:API課金の変動が大きく、来期のAI関連費用が読みにくい状態です
- 提案:
- 回数が多い定型処理だけローカルLLMに寄せることで、
- 年間◯◯万円の費用圧縮と、
- 重要データを外に出さない運用ルールを実現できます
- 投資:Mac Studio / GPU サーバー×1台(◯◯万円)
- PoC結果から見て、◯ヶ月〜1年程度で回収可能と見込んでいます
「Gemma 4がやばいんですよ!」ではなく、
「数字・リスク・ガバナンス」の3点セットで話すと、
確率はかなり上がります。
FAQ:ローカルLLM節約術で失敗しないための疑問を先回りで解消
最後に、ここまで読んだ人がほぼ確実に思うであろう疑問を、ざっとまとめておきます。
元ネタになっているポストはこちらです → 「AIのトークン代が月30万円かかってたけど…」
Q. 本当に月0円になりますか?
A. 「外部APIのトークン代がほぼ0円になった」はあり得ますが、“AIコスト完全ゼロ”ではありません。
すぐるさんのポストでは、
「AIのトークン代が月30万円かかってたけど、このやり方を試したら月0円になった」
と書かれていますが、ここで言っている「0円」は、Anthropic(Claude)の従量課金が0円に近づいたという意味で読むのが安全です。
現実には:
- ハードウェアの費用
- 例:Mac Studio / GPUマシン 40〜60万円
- 電気代
- GPUをそこそこ回すと月数千〜1万円くらい
- セットアップ・保守の自分(orチーム)の工数
は普通にかかります。
なので実務的には、
- Before:
- 「毎月30万円のAPI“変動費”」
- After:
- 「数十万円のマシン+数千円〜1万円の“固定費”+必要なところだけAPI」
くらいに“コストの構造が変わった”という方が正確です。
Q. 高価なMacやGPUマシンがないと始められませんか?
A. いきなりMac Studio級は不要です。いまのPC+4Bクラスのモデルで十分“実験”できます。
すぐるさんは「3ヶ月で90万円分Anthropicを燃やしていた人」なので、
Mac Studioクラスを買っても数ヶ月でペイする世界の話です。
でも、多くの人はそこまで燃やしてないはずで、
- 月1万〜3万円程度のAI費用
- ChatGPT Plus+たまのClaude / Gemini API
くらいの使い方なら、いきなり数十万円のマシンに飛びつく必要はありません。
やれることとしては:
- 手持ちPC+Ollama+4Bモデルから始める
- メモリ16GBあればだいぶ楽、8GBでも最小構成ならなんとか
- Gemma 3 4B / Qwen3-4B あたり
- 要約・分類・軽いチャット・短いコード生成なら十分実用レベル
- 実際に1〜2ヶ月運用してみてから、
- 「うちの使い方だとローカルを増やした方が得だ」
- 「いや、そんなにヘビーじゃないから今のままでいい」
を自分の数字で判断する
Q. ClaudeやGPT系APIを完全に置き換えられますか?
A. “全部置き換え”は現実的ではありません。
定型タスクや回数の多い処理だけ肩代わりさせるだけでも、十分ペイします。
Xでの空気感的には、
- 「Qwen3 / DeepSeek-V3.2 があれば GPT いらないのでは?」
- 「Gemma 4 で全部ローカルにしたった」
みたいなノリも流れてきますが、
ベンチマークや実務感を見る限り、
- 高度な推論
- 複雑なバグ調査・設計レビュー
- 重要クライアント向けの提案資料
- 長大なマルチモーダル処理
ここはまだ GPT-5 / Claude Opus / Gemini Pro クラスに分があります。
一方で、
- 会議要約
- 問い合わせ分類
- FAQドラフト
- テストコードの叩き台
- 社内RAGチャットボット
このあたりは Gemma / Qwen / DeepSeek-R1 の8B〜14Bクラスでも十分戦える ので、
ここだけローカル化するだけでも、API費用はかなり圧縮できます。
おすすめの発想
- ❌ 「Claude/GPTを捨ててローカルだけにする」
- ✅ 「“高い処理だけ残す”方向に持っていく」
- 回数が多い・ミス許容度高い処理 → ローカルLLMへ
- 難易度高い・信用が売上に直結する処理 → Claude/GPTを残す
Q. ローカル実行はセキュリティ的に本当に安心ですか?
A. 「データをクラウドに送らない」という意味では安心材料になります。
ただし、端末管理やアクセス制御をサボると別のリスクが出ます。
Xでのよくある主張:
- 「機密情報を外に出したくないからローカルLLM一択」
- 「オンプレに置けばセキュアでしょ」
ここは少し整理が必要で、
- クラウドLLM
- ベンダーのポリシー・インフラに乗る
- Enterpriseプランならログ保持や学習利用の有無もかなりコントロールされている
- ローカルLLM
- データが社外サーバーに出ない構成を取りやすい
- 反面、「誰がどのマシンをどの設定で使っているか」を自前で管理する必要がある
です。
具体的には、ローカルでもこんな事故は全然起こり得ます:
- ノートPCごと盗まれる
- ログファイルに機密データが生で残っている
- 社内の誰でもローカルLLMサーバーにアクセスできてしまう
安全性は「クラウド or ローカル」そのものより、運用設計で決まります。
エンジニアがやるべきこととしては:
- ローカルLLMでも
- OSとディスクの暗号化
- 端末のパスワード/MFA
- LLMログの保存期間・保存場所・アクセス権
をちゃんと決める - 「この種類のデータはクラウド禁止/ローカル必須」みたいな線引きを
情シス・法務と一緒に決めておく - 可能なら、ローカルLLMサーバーを個人マシンではなく、
専用サーバー or 社内VPCに立てて、ネットワークで制御する
まとめ:AI費用を下げるカギは『安いモデル探し』ではなく『呼び出し設計』にあった
最後に、この記事全体で言ってきたことを、「明日どう動くか」ベースで整理して締めます。
主ネタになったポストはこちら → 「AIのトークン代が月30万円かかってたけど…」
-1. このバズから読み取るべき5つのポイント
すぐるさんの
「AIのトークン代が月30万円かかってたけど、このやり方を試したら月0円になった」
というポストは、インパクトがありすぎて
- 「Gemma 4さえ入れれば全部タダ!」
- 「Mac Studio3ヶ月で元取れるらしいぞ!」
みたいな“雑な希望”も生んでしまうタイプのバズでした。
この記事でずっとやってきたのは、そのバズをエンジニアの実務に耐える形に翻訳することです。
要点はこの5つです。
- SNSの“AI費用激減”は、ローカル運用再評価の象徴
- 「月0円」は無料化ではなく、変動費の圧縮と構造変化の話
- Gemma/Qwen/DeepSeek系は、定型タスク担当として見ればかなり強い
- 勝ち筋は、クラウド×ローカル×資産化の三層構成
- 一番効くのはモデル探しではなく「呼び出し設計+ログ/プロンプトの資産化」
-2. 今日やること3つ:請求確認・高頻度業務の洗い出し・小さな検証
「分かったけど、結局何からやればいいの?」という人向けに、
“今週中にできる3ステップ”を置いておきます。
Step 1. 先月分のAI利用額をざっくり把握する
- ChatGPT / Claude / Gemini / 各種APIダッシュボードを開いて、
- サブスク固定費
- API従量課金
をざっくりメモる(円換算でOK)
→ 「うちは月1万」「うちは月10万」「すぐるさん寄りで月30万」
どのラインかが分かるだけで、判断材料が一気に変わります。
Step 2. AIに毎週お願いしている“定型タスク”を1つ書き出す
- 例:
- 会議議事録の要約
- 問い合わせメールの要約&分類
- テストコードたたき台生成
- GitHub PR のサマリコメント生成
- 「頻度が高い」「多少ミスっても人間が直せる」タスクを1つだけ選ぶ
Step 3. その1タスクだけ、ローカルLLMで試してみる
- 手順はこの記事のとおり:
curl -fsSL https://ollama.com/install.sh | shでOllamaインストールollama pull gemma3:4bで4Bモデルを入れる- Pythonサンプルの
summarize()/classify_ticket()を自分のタスクに合わせて少し書き換え - 1〜2週間だけでも運用してみて、
- 体感(使い勝手・質)
- 請求(クラウド側の利用額変化)
を見てみる
ここまでやってから、
- 「もっとローカルに寄せる」か
- 「やっぱりクラウド中心で行く」か
- 「Mac Studio / GPU投資するか」
を考えても、まったく遅くありません。
-3. 次に読むと理解が深まるテーマ:RAG、AIコーディング支援、ガバナンス
もしこの記事で火がついたら、次はこのあたりを掘っていくと理解が一気に深まります。
- RAG(Retrieval-Augmented Generation)
- モデルの“地頭”だけに頼らず、
自社のナレッジやログと組み合わせて正確さを上げる設計 - AIコーディング支援の設計
- Cursor / Claude Code / Cline / Continue とローカルLLMをどう組み合わせるか
- コーディングエージェントの「やらせすぎない」ガードレール設計
- ガバナンスとセキュリティ
- 総務省+経産省のAI事業者ガイドライン
- ログ・アクセス権・出力責任のルール作り
この3本柱が整ってくると、
「Gemma 4がすごい」ではなく「うちのAI基盤、ちょっと自慢できるかも」レベルに近づいていきます。
最後にひとつだけ質問で締めると、
あなたの業務の中で、“回数が多くて、多少ミスっても致命傷じゃないタスク”は何ですか?
その1つをローカルLLMに任せてみるところから、
あなたなりの「月30万円→月◯円」のストーリーが始まるはずです。
そのとき、もしXで「やってみた」レポートを書くなら、ぜひ
すぐるさんの元ポスト も一緒に貼って、
“バズを設計に変えた体験談”として流してみてください。
タイムライン、たぶんまたちょっとざわつきます。
参考記事: X:SuguruKun_ai - 「AIのトークン代が月30万円かかってたけど、このやり方を試したら月0円になった」Gemma 4を活用したAI節約術が話題に
- 【月30万円級のAI請求に終止符?】日本のエンジニア向け、ローカルLLMで固定費化する5つの考え方
- SNSの『AI費用ほぼゼロ化』はどこまで本当? 4つの論点で冷静に分解してみた
- API課金とローカルLLM、結局どっちが得? 月3万・10万・30万円で損益分岐を試算
- Gemma 4は実務で使える? 日本の現場でハマりやすい7つのタスクを向き・不向きで整理
- 初心者でも試しやすい:Gemma 4系ローカルLLMの最短セットアップ手順【Mac/Windows/Linux対応】
- 『モデル選び』だけでは節約できない? 生成AIコストを左右するアーキテクチャ設計の新常識
- AIエージェントの費用を本気で下げる4つのコツ:モデル変更より効く設計改善とは
- 日本のエンジニアはどう動くべき? 個人開発・副業・社内導入の3パターンで最適解を整理
- FAQ:ローカルLLM節約術で失敗しないための疑問を先回りで解消
- まとめ:AI費用を下げるカギは『安いモデル探し』ではなく『呼び出し設計』にあった
- 関連記事


コメント