
結論(導入判断)
- モデル本体の漏えいでなくても、オーケストレーション/ツール連携など「運用の配管」が流出すると、競争優位・攻撃面が一気に崩れ得ます。
- 利用企業側は、停止ではなくゾーニング(扱うコード種別/権限/ログ/共有範囲)と、.map(ソースマップ)等の公開設定点検を優先すると実務的です。
- ベンダー選定・導入判断は、機能だけでなく配布/更新/サンドボックス/監査を含む「運用設計」で評価するのが安全です。
想定読者:CISO/情シス、SRE、開発責任者、AIコード支援ツールを本番導入している(または検討中の)方
関連記事(先に読むなら):
Anthropic内部文書リークで見えた「PSM」とClaude Mythos:LLM本番導入の判断ポイント /
Claude 4.6 Sonnetとは?粒子物理・数学・PC操作エージェント“三連発”で見えた導入判断 /
OpenAI GPT‑5.4公開:思考API(Thinking tokens)の要点と導入判断
「AIコードアシスタントを本番で使ってて、ある日いきなり“中身の設計図”がネットに流出したと知ったらどうしますか?」
正直、自分がSREやセキュリティ担当なら、その日の予定は全部吹き飛びます。
今回の「Anthropic Claude Code ソースコード 51万行流出騒動」は、まさにそれに近い出来事です。
しかも「バグった .map ファイル経由でプロダクションコード一式が出ていったらしい」というオチ付き。エンジニアとしては笑えない悪夢です。
- 一言で言うと、「AI版・Windowsソースコード流出事件」
- なぜ大ごとなのか:LLMそのものより「周りの配管」が価値になってきている
- 競合目線で見ると:GitHub Copilot ほかは「ほくそ笑みつつも、ちょっとビビる」案件
- 開発者にとっては「最高の教材」だが、それでいいのか?
- 「.map ファイル経由で漏れたらしい」という事実が一番こわい
- 現場開発者目線の「三つの現実」
- 懸念点:Anthropic 側の「エンジニアリング負債」と「信頼コスト」
- それでも「AIコードアシスタントを捨てる」選択肢はほぼない
- 結論:プロダクションで Claude Code をどう扱うか?正直「様子見しつつ、使う」が現実解
- 導入・運用チェックリスト(最小)
- FAQ:企業の導入・運用でよくある質問
- 関連記事
一言で言うと、「AI版・Windowsソースコード流出事件」

この事件を一言で表すなら、
「AIコードアシスタント界の Windows ソースコード流出」
です。
- LLMの重み(Claude 本体の「脳みそ」)ではなく
- その周りを支える実戦投入済みのオーケストレーション/インフラコード
が、約51万行まるっと見えてしまった、という構図。
歴史的には、NVIDIA ドライバソースの流出や、Windows 内部コードの流出に近いです。
「製品そのもの」ではなく、「どうやって回しているかのプレイブック」が盗み見られたパターンですね。
ぶっちゃけ、これが意味するのはこうです。
- 「Claude Code をどうやって構成しているか」が業界の共通知見になってしまった
- 競合やスタートアップが、Anthropic が数年かけて試行錯誤した設計を一気にショートカットできる
これ、他人事なら「勉強になるからありがたい」ですが、当事者なら胃が痛くなるやつです。
なぜ大ごとなのか:LLMそのものより「周りの配管」が価値になってきている
多くの人は「モデルの重みが漏れてないなら、そんなに大したことないのでは?」と思うかもしれません。
正直、それは2023年くらいまでの感覚だと思います。
2026年の今、AIプロダクトの価値はかなり「オーケストレーション側」に寄ってきているからです。
モデルは“コモディティ化”しつつある
- 優秀なオープンモデル(Llama 系など)はどんどん出てきている
- API も各社横並びで、「チャットしてツール呼べます」はもはや差別化になりにくい
となると、差がつくのはここです。
- どうプロンプトを組み立てるか
- どんなツール郡とどう連携させるか
- どうコンテキストを分割・保持し、どうリトライ・ロールバックするか
- どう安全にコードをファイルシステムに反映するか
今回のリークは、まさにそこが丸見えになった事件です。
「Claude Code の本当の価値」は、コードの“運用知”だった
Note 記事の著者も、
- マルチサービス構成で
- オーケストレーションやツール連携周りの設計が
- 「勉強になるレベルで成熟している」
と評価しています。
つまり、
「Claude Code が“現場で戦ってきたノウハウ”ごと GitHub にぶちまけられた」
くらいのインパクトがある、ということです。
競合目線で見ると:GitHub Copilot ほかは「ほくそ笑みつつも、ちょっとビビる」案件
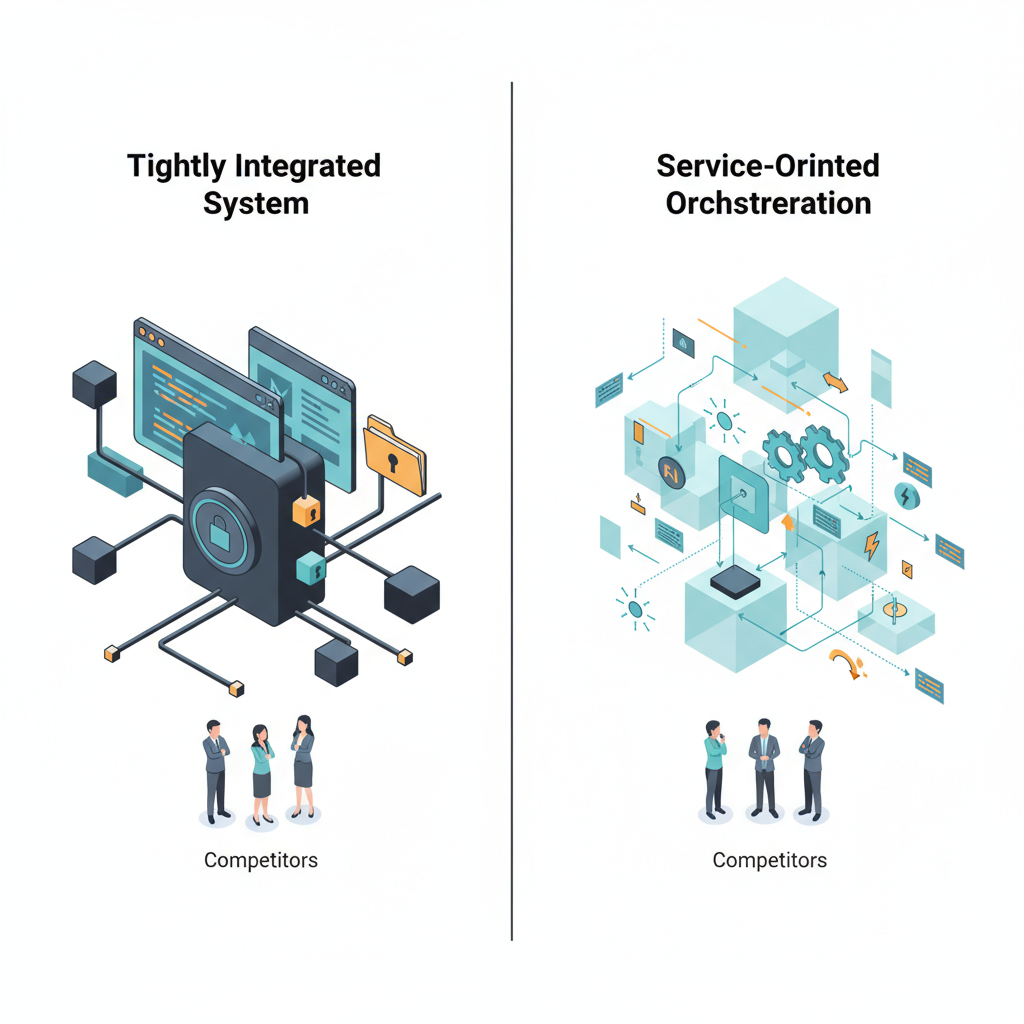
エンジニアらしく、冷静に競合比較してみます。
GitHub Copilot & Copilot Workspace との比較
- GitHub Copilot
- GitHub リポジトリと VS Code / JetBrains にどっぷり統合
- GitHub アカウントや Git ベースのワークフローと密結合
-
内部構造はほぼブラックボックス
-
Claude Code(リークされた側)
- サービス指向のオーケストレーション(API 中心)で IDE 非依存っぽい
- リポジトリやファイルシステムとの連携ロジックがコードとして可視化
- プロンプト構築やツール呼び出しの「具体的な設計パターン」が分かる
競合各社が一番「おいしい」と感じるのはここです。
- LLMをどう呼ぶか
- どのタイミングでどのコンテキストを渡すか
- 失敗したときにどうリカバリを設計しているか
こういう「本当に使えるコードアシスタントを作るための設計資料」を、GitHub は公開していません。
Anthropic は、意図せず先に晒してしまった格好です。
競合にとっては、
- 「あ、うちの設計ここダメかも」と気づく鏡にもなるし
- 「この書き方そのまま真似しよう」ができる青写真にもなる
という、かなり強力な“リファレンス実装”になってしまいました。
開発者にとっては「最高の教材」だが、それでいいのか?
技術者としての正直な本音を言うと、
「これは相当うまい実戦サンプルだから、勉強にはめちゃくちゃ良い」
です。
- LLM コードアシスタントを自社で作りたいスタートアップ
- 既存サービスに AI コーディング機能を埋め込みたい SaaS 企業
にとっては、
- サービス分割の粒度
- API 設計の現実解
- プロンプトエンジニアリングを“コードとして”どう組み込むか
などが丸ごと教材になるレベルでしょう。
ただ、ここで押さえておきたい「勘違いポイント」があります。
「Claude をタダで手に入れた」は完全に誤解
- LLM の重みも
- 学習データも
- Anthropic の安全性検証プロセスも
は、もちろん一切漏れていません。
漏れたのは、
- 優れたモデルをどう現実世界のタスクに接続しているか
- そのための配管・制御ロジック一式
であって、「Claude を自前で動かせるようになった」わけではないです。
なので、
- これを基にクローンを作っても、モデル品質や安全性までは再現できない
- でも、そこそこのクオリティの「Claudeライクな体験」には、かなり早く近づけてしまう
という、微妙に嫌なラインのリークだと言えます。
「.map ファイル経由で漏れたらしい」という事実が一番こわい
個人的に一番ゾッとしたのは、
「バンドラ(Bun のバグ?)由来の
.mapファイルを通じて、プロダクションコード一式が露出した」
という指摘が出ている点です。
正直、これ、他人事じゃありません。
- フロントエンドのビルド設定
- ソースマップの扱い
- “本番には出さないはずだった”アーティファクト
このあたり、現場では「なんとなく動いているから」レベルで放置されがちです。
でも AI 時代のプロダクトでは、
- 一つの
.map- 一つの S3 バケット設定ミス
- 一つの CI/CD の権限設定
が、数十万行規模の知財流出に直結し得ることが、今回ハッキリしました。
「LLM はブラックボックスだから安全性を担保しづらい」と言いながら、
自分たちのビルドチェーンや artifact 管理はガバガバ、という組織は少なくありません。
この事件の一番の教訓は、
「AI だから特別に危ない」のではなく
「CI/ビルド/配布の一つひとつが“LLM級にセンシティブ”になっている
という現実を突きつけられた、という点だと感じています。
現場開発者目線の「三つの現実」
コミュニティの反応や日常の開発現場を見ていると、この事件と地続きの“空気感”が三つあります。
安定性問題:みんなこっそり「バージョン固定」している
Claude Code では実際に、
- あるバージョン(2.1.72/73)でメモリリークが見つかり
- ユーザーが
CLAUDE_CODE_DISABLE_AUTOUPDATE=1で自動アップデートを止めている
という話も出ていました。
これは、
- 「最新が必ずしも正義ではない」
- 「とりあえず動いているバージョンをロックする」
という、ごく人間らしい、でもプロダクションでは当たり前の反応です。
LLM製品側がどれだけモダンでも、クライアントツールとしては昔ながらの“バージョン地獄”をちゃんと内包している。
この現実は、リーク騒動とは別軸ですが、けっこう重い事実です。
サンドボックスとファイルアクセスの“気持ち悪さ”
Claude Code のサンドボックス機能を有効にしたら、
- 「あー、サンドボックス有効だから○○できません」的なメッセージが出て
- それを「ちょっとウザい」「でも怖いから切りたくない」と感じるユーザーもいる
という声もありました。
AI コードツールって、
- フル権限でファイルを触らせると怖い
- かといって制限しすぎると「使いものにならない」
というジレンマを常に抱えています。
今回のリークは、まさにその「あまりにも権限が大きい存在」の設計図ごと漏れた事件です。
サンドボックスをどう実装するかまで含めて見られてしまうのは、セキュリティ的にはかなり痛いポイントでしょう。
「うちのコードはそこまで機密じゃない」という発想
一方でコミュニティには、
「うちのアプリのコードなんて、そんなにヤバい機密でもないし」
「セキュリティを理由に AI コーディング全面禁止はやりすぎじゃない?」
という空気も確実にあります。
これは完全に現場感として理解できます。
- ほとんどが OSS の組み合わせ
- ビジネスロジックもそんなにユニークじゃない
- それより開発速度を上げたい
というプロジェクトは山ほどある。
そういう現場からすると、「Claude Code にソースを投げるリスク」と「開発効率アップのリターン」を天秤にかけて、後者を取るのは合理的です。
今回のリークは、
- 「ベンダー側の中身も、ここまでまとめて漏れうる」
というリスクを突きつけたので、企業のCISOはますます慎重になるでしょう。
一方で現場開発者は「また AI 禁止ルールが増えるのか…」とため息をつく。
この緊張関係は、今後しばらく続くと思います。
懸念点:Anthropic 側の「エンジニアリング負債」と「信頼コスト」

技術とビジネスの両方の視点から、Anthropic にとっての痛手を整理しておきます。
セキュリティ負債の急増
- 漏れたコードの中に秘匿情報(キー、エンドポイント、内部プロトコル)が含まれていれば、それらの全面的な洗い替えが必要
- システム内部の構造を把握した上で攻撃してくる相手に備え、
- 増強された監視
- 追加の防御レイヤー
- 異常検知ロジックの見直し
が必要
これはそのまま、開発速度の低下や運用コストの増加に直結します。
設計の“粗”が全部見える
どんな大規模サービスにも、
- 歴史的経緯から残っている謎のモジュール
- 本当は直したいけど回せてしまっている“暫定実装”
- コメントで「TODO: いつか直す」と書いてある地雷
があります。
リークは、それを世界中のエンジニアにレビューされるイベントでもあります。
- 競合
- セキュリティ研究者
- 大口エンタープライズ顧客
が、好き放題コードベースを眺めて評価できてしまう。
これは、単なる知財流出以上に、信頼のレイヤーに効いてきます。
Enterprise セールスへの逆風
大企業の IT 部門からすると、
「自社の機密コードを預ける相手の、プロダクションコードがごっそり漏れた」
という事実だけで、延々と社内稟議が止まる原因になります。
- セキュリティチェックシートの項目が増える
- リーク後の再発防止策の説明を延々と求められる
- 既存顧客からの監査が増える
これは短期的にはかなりのビジネスダメージです。
それでも「AIコードアシスタントを捨てる」選択肢はほぼない
ここまでネガティブな側面を列挙しましたが、
現場エンジニアとしての感覚を言うと、
「だから Claude Code や Copilot を全部やめます、にはまずならない」
です。
- ローカルに閉じたリポジトリで試す
- テストコードやドキュメント生成から導入する
- 機密度の低いサービスから徐々に範囲を広げる
など、リスク分散をしながら使い続ける方向が現実的です。
企業としても、
- 何もかも禁止して開発効率を落とす
- ある程度ガイドラインを整えて共存を図る
の二択なら、後者を選ぶところが増えていくと見ています。
結論:プロダクションで Claude Code をどう扱うか?正直「様子見しつつ、使う」が現実解
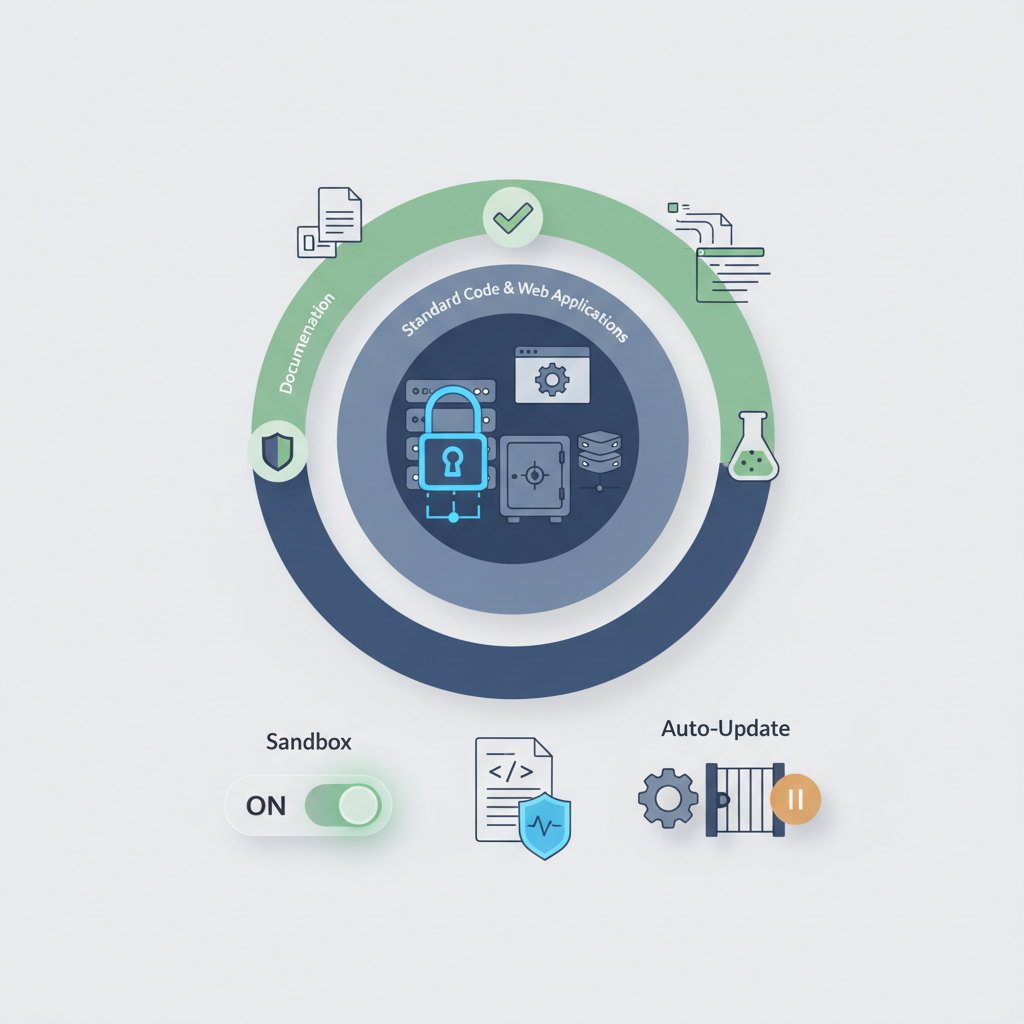
最後に、自分が技術責任者だったらどう判断するか、という観点でまとめます。
いきなり全面停止はしない
- すでに Claude Code に依存したフローがあるなら、
それを即日止めるほどの直接的な危険は、現時点の情報からは見えません。 - ただし、Anthropic 側のセキュリティ・設計変更に伴う一時的な不安定さは覚悟します。
「使う範囲」と「コード種別」を分ける
- 機密性の高いコアアルゴリズム・未発表製品のコード
→ そもそもどの AI コードツールにも出さないポリシーを明文化 - 一般的な Webアプリ、社内ツール、OSS ベースのサービス
→ Claude Code / Copilot を普通に使う - ドキュメント生成・リファクタ提案・テストコード作成
→ もっとも積極的に使ってよい領域として推奨
という“ゾーニング”をした上で、ツールを許可します。
ローカル環境の安全側設定をデフォルトにする
- サンドボックスを標準でオン
- 自動アップデートはチームで検証してから反映(CLAUDE_CODE_DISABLE_AUTOUPDATE 的な運用)
- ログの扱い(AI に渡したコード片がどこまで残るか)をチームで共有
など、「使い方の標準」を決めてから展開するのが現実的です。
正直に言えば、今回のリークは Anthropic にとってはかなり痛手であり、
AI コードアシスタント時代の「セキュリティの新常識」を突きつけた事件だと思います。
一方で、開発者としては、
- 「大手が実戦投入している AI コードアシスタントのアーキテクチャを、こんなに早く覗けることは本来あり得なかった」
- 「この知見を踏まえた上で、どう安全に AI を現場に組み込むか」を考えるチャンス
でもあります。
プロダクションで Claude Code を使うか?
正直、全面禁止にするほどではないが、“何でもかんでも投げる時代”は終わった、というのが自分の結論です。
- 機密コードの取り扱いポリシーをきちんと決める
- ツール側のアップデートやリーク情報を常時ウォッチする
- それでも、AI コードアシスタントは開発フローの中心に据える
この「慎重な楽観主義」くらいが、2026年の現実解ではないでしょうか。
導入・運用チェックリスト(最小)
- ビルド成果物の公開点検:.map / debug 画像 / 例外ログ / artifact 配布先(S3/CDN)を棚卸し
- 権限の最小化:AIツールのファイルアクセス範囲、リポジトリ権限、Secrets閲覧権限を分離
- 扱うコードの線引き:未発表機能・鍵/設定・コアアルゴリズムは投入禁止、テスト/ドキュメントは積極活用など
- 更新の運用:自動アップデートはチーム検証後に反映(固定/ロールバック手順を準備)
- ログの取り扱い:AIに渡した断片がどこに残るか、社内規定(保存/共有/マスキング)を明文化
- ベンダー監査観点:インシデント時の通知SLA、監査証跡、キー洗い替え手順、再発防止の透明性
FAQ:企業の導入・運用でよくある質問
Q. 今すぐ AIコーディングツールの利用を止めるべき?
A. 一律停止は現実的でないことが多いので、まずは機密コードのゾーニングと権限/ログ/共有範囲の見直しを優先するのが実務的です。
Q. .map(ソースマップ)は本番に置いても大丈夫?
A. 原則は本番公開しない(少なくとも第三者が取得できないようにする)方が安全です。必要なら、アクセス制御・短期保管・配布設定(CDN/S3/ヘッダ)まで含めて管理しましょう。
Q. 「AIに渡してよいコード」と「ダメなコード」の線引きは?
A. まずは「鍵/認証情報」「未発表製品のコア」「競争優位の中核アルゴリズム」を禁止にし、テスト/リファクタ提案/ドキュメント生成などリスクの低い領域から拡大するのが事故りにくいです。
Q. ベンダー側のリーク/事故が起きたとき、導入企業は何を確認すべき?
A. 影響範囲(漏えいデータの種別/期間)に加え、再発防止策・キー洗い替え・監査ログ・通知SLAを具体で確認し、必要なら一時的な利用範囲の縮小(ゾーニング強化)を行います。


コメント