
結論(導入判断)
Gemma 4の基本仕様(モデルサイズ/ライセンス/長コンテキストなど)の整理は こちらの記事 もあわせてどうぞ。
- Gemma 4は「ローカルでマルチモーダル」が現実的になり、設計前提(クラウドAPI固定)を見直す価値が出てきた
- ただし「全部ローカル」はGPU/運用/MLOpsの負債が増えるため、PoC→段階移行の意思決定が安全
- 採用のカギは、必要VRAM・精度要件・機密/データ境界・運用体制(回帰テスト/更新管理)を先に決めること
想定読者:社内アシスタント/業務アプリで「画像+日本語」を扱いたい開発者・アーキテクト、もしくはクラウドAPIコスト/機密要件でローカル運用を検討している方
「マルチモーダルを入れたいけど、
- API コストが怖い
- 機密情報は外に出せない
- でもローカルの OSS モデルは画質も精度もイマイチ…
こんな三重苦で、設計会議が毎回モヤっと終わっていないでしょうか。
そういう人にとって、Google Gemma 4 の Zenn / note 実践記事を一通り読んでいて感じたのは、
「あ、これは本当に前提が変わるやつだな」ということです。
一言でいうと「マルチモーダル版 Docker モーメント」
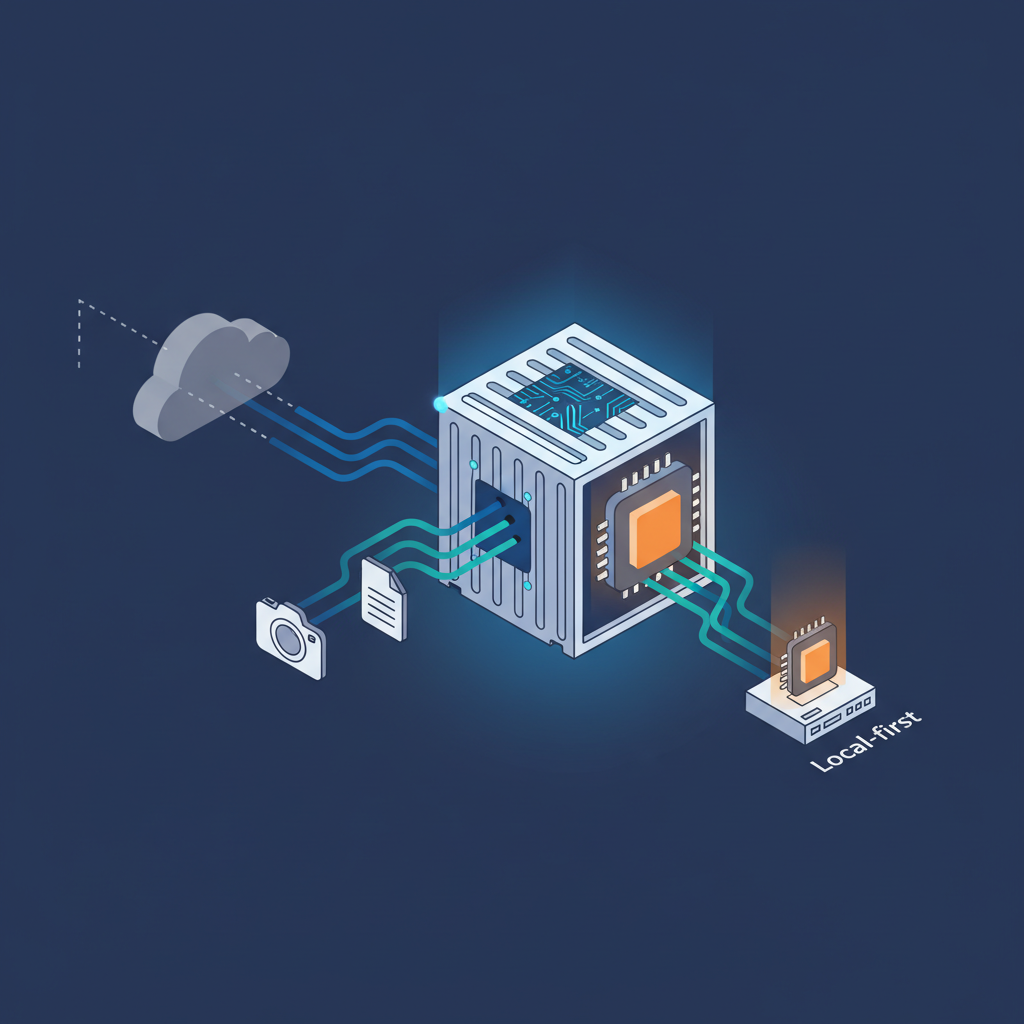
一言でいうと、Gemma 4 は 「マルチモーダル界の Docker」 です。
- 以前:
- 高性能コンテナは一部の人だけが使えるニッチ技術
-
開発者は素直に「VM 前提」でインフラ設計していた
-
Docker 登場後:
docker run一発で誰でもコンテナ- 「アプリはとりあえずコンテナ前提で考える」が当たり前に
Gemma 4 で起きているのは、その マルチモーダル版 に近いです。
- 以前:
- 「画像も読ませたい? じゃあ GPT-4o / Gemini 1.5 API だよね」
-
ローカルはせいぜいテキスト専用か、お試しレベルの Vision
-
Gemma 4 後:
ollama pull gemma4:***あるいはtransformers数行で- 「そこそこ賢い Vision 付きモデル」がローカル GPU で普通に動く
正直、Zenn / note の記事群を読む限り、
「これもう“マルチモーダル=クラウド”という前提を引きずるのは損だな」と感じます。
何がそんなに違うのか:Gemma 4 が「ただの新モデル」で終わらない理由
「フルスタック・マルチモーダル」がガチでローカルに降りてきた
Gemma 4 の一番のポイントは、テキスト+画像をローカル完結で扱えることです。
- 31B IT をはじめ、2B / 9B / 12B などサイズ展開
- Vision 対応(画像入力)込み
- Apache 2.0 相当レベルの商用利用 OK に近いライセンス
- Hugging Face / Ollama / vLLM 等ですぐ使える形で公開
ここまで揃った「フルスタック・マルチモーダル OSS」を、
しかも Google 自らが出してきた のは、さすがに空気が変わります。
これまでも Qwen 2-Vision などはありましたが、
- 商用利用ポリシーへの心理的ハードル
- 日本企業の法務が嫌がりがちなライセンス文言
- 日本語圏での「情報量」と「事例の少なさ」
このあたりで、「技術的には良いけど、社内稟議的にはつらい」という声をよく聞きました。
Gemma 4 はここを一気に突いてきていて、Zenn / note の記事でも
「Google 製+明快なモデルカード+日本語もちゃんと動く」 という安心感が何度も言及されています。
軽さと賢さのバランスが、現実的なラインに乗った
記事群を読むと、だいたいこんな体感でまとまっています。
- 8GB VRAM:
- 2B / E2B の 4bit 量子化 → チャット・要約なら実用レベル
- 12〜16GB VRAM:
- 9B 4bit → マルチモーダル+そこそこの推論も現実的
- 24GB VRAM〜:
- 12B / 31B IT 4bit / 8bit → 本格的に「仕事で使える」レベル
ここが重要で、「マルチモーダルなのに Llama 3 と同じ感覚で積める」 という評価が多い。
ぶっちゃけ、これまでの OSS Vision モデルは、
- 「精度は悪くないけど、とにかく重い」
- 「軽くすると、精度が一気に落ちる」
という印象が強かったのですが、Gemma 4 の記事では
「あれ、Llama 3 使うか Gemma 4 使うか、サイズ感ではほぼ同じ議論で済むぞ?」 という温度感なんですよね。
競合と比べてどこがうまいのか:Gemma 4 を選ぶ理由・選ばない理由

ここからは、記事群の比較や自分の感触を踏まえて、
「実際にプロダクションでモデル選定するときどう考えるか」 の視点で整理します。
Gemma 4 vs Qwen 2-Vision:画像精度か、日本語テキストか
各記事を読む限り、ざっくりこんな棲み分けです。
- Qwen 2-Vision
- 画像理解・UI 解析・OCR 的なタスクに強い
- 中国語・英語中心だが、日本語も十分使える
- Gemma 4
- 画像精度は Qwen 2-V と同等〜やや劣るケースもある
- ただし 日本語テキストの自然さ・長文構造化はかなり良い
- ライセンス・ブランドの安心感で日本企業に刺さりやすい
正直、「スクショから UI 構造を抽出する」「PDF の日本語 OCR をガチでやる」なら、
まだ Qwen 2-Vision を選ぶケースは普通にあると思います。
一方で、
- 「日本語 UI + 画像をちょっと読ませる社内アシスタント」
- 「日本語ドキュメント+図表を含む要約・説明」
- 「コードも書かせるけど、ユーザーとの対話は日本語中心」
こういう現場感の案件だと、Gemma 4 の方がバランスがいいという印象です。
特に 31B IT のコード生成について、
- 「Llama 3 と体感同等以上」
- 「Web 系・Python 系ならかなりイケる」
というレビューが多く、日本語+コードが主戦場の国内 SIer / SaaS 企業には相性が良さそうです。
Gemma 4 vs Llama 3:デフォルトテキストモデルの牙城は崩れるか?
Llama 3 は「とりあえずこれでいいか」のデフォルトとして強いですが、Gemma 4 の登場で事情が変わります。
記事をまとめると:
- モデルサイズ・VRAM 要件:
- 量子化前提だと軽さはほぼ同等
- 「マルチモーダル込みでこの軽さ」は Gemma 4 が一歩リード
- 言語性能:
- 英語:ベンチによって前後、誤差レベル
- 日本語:
- 「Llama 3 より Gemma 4 の方が自然で好み」という声が多数
- コード:
- 31B IT は Llama 3 70B に肉薄する場面もあるが、
超ニッチ・超難問ではまだ GPT-4o / Gemini 1.5 Ultra が優位
ここで重要なのは、「Llama 3 の上位互換」ではなく「選択肢として並んだ」ということです。
- テキスト専用で、英語中心:
→ 依然として Llama 3 のほうが王道路線 - 日本語+マルチモーダル+ローカル前提:
→ Gemma 4 を第一候補に挙げる価値が出てきた
正直、これまで多くのチームが
「テキストは Llama 3、マルチモーダルは GPT-4o / Gemini API」という構成で考えていたはずですが、
Gemma 4 で 「全部ローカル」構成がほんのり現実味を帯びてきた のは無視できません。
一番のインパクトは「アーキテクチャの前提」が変わること
技術的には、Gemma 4 は単なる新しい OSS モデルです。
既存の API を壊すわけでもないし、Breaking Change ではありません。
でも、アーキテクト目線で見ると話が違ってきます。
これまでの前提
- マルチモーダル:クラウド API 前提
- ローカル:テキスト中心、マルチモーダルは諦めるか、オマケレベル
- 設計パターン:
- フロント → 自社バックエンド → 各種 LLM API(テキスト / マルチモーダル)
Gemma 4 後の現実的なオプション
- マルチモーダルもローカル GPU で完結可能
- Hugging Face / Ollama / vLLM で簡単に差し替え可能
- 機密データも外に出さずに画像+テキスト処理
つまり、
- 「マルチモーダル部分だけはクラウドに投げるアーキテクチャ」
- 「画像系の処理は別途オンプレの専用 OCR / CV モデルを用意」
こうした構成が、わざわざ複雑な構成を維持する理由を失いつつある わけです。
正直、
「マルチモーダルだけクラウド API に投げる構成をこれから新規開発で採用する?」
と聞かれたら、私はかなり慎重になります。
とはいえ落とし穴もデカい:「全部ローカル」は甘くない

ここまで褒めたので、ちゃんと懸念も書きます。
Gemma 4 記事群にも、いろいろと「現実」がにじんでいました。
GPU コストは消えない、形を変えてやってくる
- 8GB VRAM で 2B / E2B が動くのは確かに偉い
- ただし、「画像+長文+高速応答」 を両立させるなら、
- 現実的には 16〜24GB VRAM クラスが欲しくなる
クラウド API のトークン課金が嫌でローカルに逃げても、
参考:推論コスト(特に長文/高並列)を下げるアプローチとして、KVキャッシュ量子化(TurboQuant)の整理も 別記事 にまとめています。
- GPU ハードウェア費
- 電気代
- 冷却・設置スペース
- 運用担当者の工数
という別種のコスト構造に置き換わるだけです。
ぶっちゃけ、「API の請求書が怖いからローカルに逃げよう」という発想だけで Gemma 4 を選ぶと、
半年後にインフラチームと殴り合いになる未来 が見えます。
振る舞いのバラつきと、チューニング沼
Zenn / note の非エンジニア記事でも、
- 想定外の脱線回答
- 回答の抜け・取りこぼし
- 似た質問でも答えの安定感が足りない
といった話が出ています。
クラウドの SOTA モデルと比較すると、
- パラメータ数・トレーニングデータ量
- 安全性・一貫性チューニングのノウハウ
でまだ差があり、「そのまま投げれば大抵なんとかしてくれるモデル」ではない という印象です。
実務利用では、
- プロンプト設計
- RAG(検索拡張生成)
- ツール呼び出し / ルールベース制御
を組み合わせて、Gemma 4 のクセを吸収する設計 が必要になります。
MLOps / モデル運用という新しい負債
クラウド API だと、
- モデル更新はベンダー任せ
- バージョン固定も API パラメータで済む
ローカルに Gemma 4 を持ち込むと、代わりにこうなります。
- モデルバリアント(2B / 9B / 12B / 31B IT)の管理
- 量子化版のダウンロード・更新
- 推論サーバ(Ollama / TGI / vLLM)のアップデート
- ベンチマークと回帰テスト
つまり、MLOps を自前でやる覚悟 が必要です。
正直、「小さなチームが最初からここまでやるべきか?」というと、
私は「まずはクラウドで PoC、当たりが見えたらローカル移行を検討」でいいと思っています。
ベンダーロックインとエコシステム分断へのささやかな不安
Gemma 4 は OSS ですが、背後にいるのはもちろん Google です。
- 開発の方向性
- モデル更新の頻度
- ライセンスや提供ポリシーの変化
ここは Google のビジネス判断に依存します。
Llama 系、Qwen 系、Mistral 系などと合わせて、エコシステムが細かく分断されていく流れ も見えてきました。
- プロンプトテンプレート
- システムメッセージ形式
- Fine-tuning のフォーマット
- ツール呼び出しの仕様
これを Gemma 4 前提でベタ書き してしまうと、数年後に確実に技術的負債になります。
個人的には、
- 自前で「LLM Adapter レイヤー」を用意する
- あるいは LangChain / LlamaIndex などで抽象化する
など、「Gemma 4 を差し替え可能な1モデルとして扱う」 設計を強く推したいところです。
結局、プロダクションで使うか?自分ならこう決める

最後に、一番気になるところをはっきり書きます。
「Gemma 4 を今、プロダクションで採用するか?」
私の答えはこうです。
- 社内 PoC / プロトタイプ用途:積極的に使うべき
- ローカル環境でマルチモーダル UX を試すには最高の選択肢
- Zenn / note の記事をなぞれば、非エンジニアでもセットアップできるレベル
- 小〜中規模のクローズド社内ツール:十分“アリ”
- GPU コストと運用を吸収できるなら、
「機密情報を外に出さない」メリットは相当大きい - 大規模プロダクションのコア:正直まだ様子見
- 超高い安定性・再現性が求められる領域(金融・医療・公共など)
- 海外ユーザー比率が高く、英語圏の SOTA に乗っておいた方が得なサービス
こういうところでは、まだ GPT-4o / Gemini 1.5 / Claude などの
クローズド超大型モデルをメインに据えるほうが安全だと思います。
では、明日から何を変えるべきか
最後に、この記事をここまで読んでくださった開発者・アーキテクトに、
「Gemma 4 時代に合わせて、今日から変えておいたほうがいいこと」 を 3 つだけ挙げます。
-
- アーキテクチャ設計の前提をアップデートする
- 「マルチモーダルはクラウド API」がデフォルト前提になっていないかを見直す
-
ローカル GPU オプションを最初から設計資料に載せておく
-
- モデル依存を抽象化するレイヤーを用意する
-
自前の LLM クライアント or LangChain / LlamaIndex 等で、
「Gemma 4 / Llama 3 / Qwen 2」を差し替えできるようにしておく -
- まずは 9B / 12B クラスで PoC を回してみる
- 16〜24GB VRAM クラスの GPU があるなら、
「日本語+マルチモーダル+コード」を Gemma 4 ベースで試してみる価値は大きい
Gemma 4 は、単に「また一つ強いモデルが出た」という話ではなく、
「ローカルでマルチモーダルをやるのが、ようやく現場の現実に追いついてきた」 という転換点です。
ここで設計思想をアップデートしておけるチームと、
「とりあえず今までどおりクラウドで…」と惰性で進むチームの差は、
たぶん 1〜2 年後、かなりはっきり出てくるはずです。
FAQ(導入判断のよくある質問)
Q. まず試すなら、どのサイズ(VRAM目安)から?
A. まずは手元のGPUに合わせて小さめ(例:2B/9Bの量子化)でUX検証→要件が固まったら12B/31B系を検討、が安全です。最初から最大モデル前提にすると運用が重くなりがちです。
Q. 「全部ローカル」にする判断基準は?
A. 機密データ境界(外部APIに出せない)と、応答品質/再現性の要件、そして回帰テストやモデル更新を回せる体制が揃うかで決まります。体制が薄い場合は、PoCはクラウド→段階的にローカル移行が現実的です。
Q. 商用利用や社内利用で注意すべき点は?
A. 具体的な可否はモデルカード/ライセンス条項(派生物・再配布・利用制限など)を必ず確認してください。社内利用でも、ログ/学習/データ保持の扱いを運用手順に落とすのが重要です。

コメント