
結論(先に要点)
- Flash Liveは、ASR→LLM→TTSの「配線」をやめて、会話セッション(双方向ストリーミング)を前提に音声対話を扱う設計に寄せています。
- 自然な割り込み/ターンテイキングが作りやすくなる一方、プロトコル/挙動レベルのロックインと、コスト・帯域の読みづらさが増えます。
- 導入はまずPoCで、レイテンシ/コスト上限/ログ・音声データの扱いを先に固めてから段階的に広げるのが安全です。
想定読者:音声UI/音声エージェントを設計・実装するPM/エンジニア
導入判断チェックリスト(実装・運用の最低限)
- コスト上限:無音時の切断・待機モード・上限アラートを設計できるか
- ストリーミング品質:ネットワーク劣化時の再接続/セッション継続をUX込みで扱えるか
- ブラックボックス耐性:会話の“間”やトーンが変動しても許容できる業務か
- プライバシー:環境音を含む音声が送信され得る前提で、保存/削除/通知を設計できるか
- 移行性:OpenAI Realtime等への切替を見据え、抽象化レイヤーを用意できるか
「音声アシスタントを作るたびに、毎回 ASR と LLM と TTS を配線し直してるんだけど?」
そう思ったこと、ありませんか。
- ユーザーの声 → スピーチ認識(ASR)
- テキスト → LLM
- 返答テキスト → 音声合成(TTS)
- 途中でユーザーが割り込んだら?
- ネットワークが少し詰まったら?
- ASR が微妙に聞き間違えたら?
このへん、全部「自前で」ハンドリングしてきた人には、正直うんざりする世界だと思います。
そのど真ん中に、Google DeepMind が「Gemini 3.1 Flash Live」という、新しい爆弾を落としてきました。
一言でいうと:音声版 WebSocket がようやくクラウドから降ってきた

一言でまとめると、Gemini 3.1 Flash Live は、
「音声インターフェイス界の WebSocket」
です。
- 以前:ASR / LLM / TTS / 対話制御を寄せ集めて、なんちゃってリアルタイムを実装
- これから:耳と口を持った LLM に、双方向ストリーミングでしゃべりかけるだけ
技術的には「Gemini 3.1 系列の、低レイテンシ音声+テキスト特化モデル」ですが、
本質的には 「会話そのものが API プリミティブになった」 ところがポイントです。
Web アプリの世界が、ポーリング地獄から WebSocket で救われたのと、かなり感触が似ています。
何が本当に変わるのか:開発者目線で3つだけ挙げる
「LLM に音声を足す」ではなく「会話セッションを前提にする」世界になる
これまでのよくある構成は、
- 音声 → ASR → テキスト → LLM → テキスト → TTS → 音声
という「ステージ制」パイプラインでした。
Flash Live はここを一気に潰して、
- マイクからの音声フレームをストリーミングで投げる
- モデルからはトークンと音声がストリーミングで返ってくる
- セッションは継続し、文脈も維持される
という 1 本の「会話ソケット」 にしてしまいます。
正直、エンジニア側から見るとこれはかなり大きいです。
- 自前の「バージイン制御」(ユーザーがしゃべったら TTS を止める)ロジックが不要
- ASR の「中間結果」と LLM の入力タイミングを気にしなくてよくなる
- ノイズやかぶり(ダブルトーク)の処理もモデル側に寄せられる
つまり、「声でしゃべってくる LLM」を前提にプロダクトを設計できるようになる。
これは単なる音声 I/O の追加ではなく、アーキテクチャの前提が変わる話です。
「速度 vs IQ」の割り切りが、ようやく製品レベルで整理された
Gemini 3.1 系列は大きく、
- Pro:高能力・やや重い
- Flash:軽量・速い
- Flash Live:音声ファースト・リアルタイム特化
という整理になりました。
Flash Live は、ぶっちゃけ「最高スコアを叩き出す頭脳」ではなく、
- サブ秒レイテンシ
- 途切れない会話
- 割り込み・聞き返し・ノイズ耐性
を優先した「会話に最適化された頭脳」です。
しかも、ComplexFuncBench Audio や Audio MultiChallenge みたいな、
音声→関数呼び出し→結果→再応答、という複雑タスクでもかなり良い数字を出している。
これ、「コールセンターやライブエージェントで実用に耐えるライン」に乗せに来ている、というメッセージだと読んでいます。
「耳と口を持つエージェント」が現実路線に乗る
DeepMind 側の発表を見ると、Flash Live では Function Calling(ツール実行)がかなり強化されています。
つまり、
- ユーザーがしゃべる
- Flash Live が聞きながら必要な API を叩く
- 結果を踏まえて、そのまま話し続ける
という「音声エージェント」が、かなり素直に作れるようになる。
これまでは、
- ASR の結果を見て、ツールを叩くかどうか決めるロジック
- LLM の出力からさらにツールコールを抽出するロジック
- それを元に TTS に投げるテキストを組み立てるロジック
と、どうしても中間レイヤーだらけになりがちでしたが、
Flash Live は 「音声付きエージェント」を 1 プリミティブとして扱える ところが本当に大きい。
なぜ今これが重要か:OpenAI Realtime とのガチ勝負が始まった

正直、Google がここまでやってこないと、
「音声リアルタイム」は OpenAI GPT-4o Realtime の独壇場になりかねない状況でした。
機能面ではかなり「ガチの正面衝突」
ざっくり比較すると、
- OpenAI Realtime / GPT-4o Live
- 先行イメージが強い
- 開発コミュニティ・ツールのエコシステムが厚い
-
Agents / Realtime API のデモも豊富
-
Gemini 3.1 Flash Live
- 「ターンテイキング」「割り込み」「ノイズ」「感情ニュアンス」といった会話の質をかなり押している
- もともとの Google エコシステム(Android / Chrome / Workspace / GCP)との統合が見込める
- SynthID で音声に透かしを入れるあたり、ディープフェイク対策も意識
機能的には、ほぼ 「パリティ+α」 を取りにきている印象です。
複数ステップの関数呼び出しを含むベンチマークでトップをとっているのも、「エージェント用途を本気で取りに行っている」と読めます。
でも、一番効いてくるのは「配布チャネル」です
正直ここが一番エグいポイントで、
- Android の「Gemini Live」
- 検索の「Search Live」(AI Mode)
- Chrome や Workspace の音声アシスト
ここに Flash Live が「デフォルトの頭脳」として入ってくるなら、
- 世界中のスマホ・ブラウザが、実質 Flash Live のクライアントになる
という話です。
API ビジネスとしては OpenAI と横並びに見えても、
「デバイス側プリインストール」という点で、Google は圧倒的な配布力を持っています。
ぶっちゃけ、モバイルでの音声インターフェイスは Google が本気を出した瞬間、一気に主戦場が変わる 可能性がある。
これは、サードパーティの「音声アシスタント風アプリ」を作っている人たちには、かなり重い現実です。
「正直ありがたい」一方で、見て見ぬふりをすると危ない罠
とはいえ、全部がバラ色かというと、そうでもありません。
Flash Live には、エンジニア目線でいくつかガチで気をつけた方がいいポイントがあります。
インタラクションモデルごと縛られる「ベンダーロックイン」
Flash Live の本当の価値は、
- モデルの重みそのもの ではなく
- 「会話セッションの設計+イベントモデル+ターンテイキングの挙動」
にあります。
つまり、
- クライアント側のコードは
- Google 独自のセッション管理
- イベント種別(ユーザー割り込み、発話終了、など)
- モデル特有の“間”や応答パターン
を前提に最適化されていきます。
その結果どうなるかというと、
- 将来「やっぱり OpenAI Realtime に移行したい」「社内ポリシーで別クラウドに統一したい」となったとき、
- 単なる「ベース URL の差し替え」では絶対に済まない
という状況になります。
ぶっちゃけ、プロトコルと会話設計を API ベンダーに持っていかれる ので、
今から作る人は、
- 自分たちのアプリ側に「抽象化レイヤー」をちゃんと切っておく
- Google / OpenAI / 他社の Realtime API を差し替え可能なインターフェイスにしておく
くらいは、真面目に検討した方がいいと思います。
コストと帯域は「テキスト API の延長線」では考えない方がいい
常時ストリーミングの音声セッションは、
- 接続が開きっぱなし
- しゃべっていようがいまいが、ある程度の心拍(keep-alive)トラフィックは流れる
- 会話が長引けば長引くほど、トークン+音声分だけ課金も増える
という世界です。
開発の PoC フェーズだと軽く見積もりがちですが、
本番運用で例えば、
- 同時接続 1,000 セッション
- 平均通話時間 5〜10 分
- コールセンター営業時間フル稼働
みたいな構成になると、
「あれ、これ普通に人件費級のクラウドコストでは?」 という数字が出てきてもおかしくありません。
- アイドルタイムをちゃんと切る
- 一定時間以上の会話は人間オペレーターに手動移行する
- 料金アラートや上限をインフラ側で必ず設定する
こういった「運用としての安全装置」は必須になるはずです。
複雑さは「バックエンドからクライアント」に移る
Flash Live で嬉しいのは、
- サーバーサイドのオーケストレーション(ASR → LLM → TTS → …)がかなり薄くできる
という点です。一方で、
- クライアント側(Web / モバイル)が
- 安定したストリーミング接続
- 再接続時のセッション継続
- ネットワークが不安定なときの UI/UX
- 部分的な音声出力へのフィードバック(字幕、波形表示など)
を面倒みる必要が出てきます。
リアルタイム通信に慣れていないフロントエンドチームにとっては、
「LLM だから楽になる」と思ったら、別のところでちゃんと難易度が上がる 可能性が高いです。
会話の「挙動」がブラックボックス化する
Flash Live は、
- どこで一呼吸置くか
- どこまでユーザーの割り込みを許容するか
- どんなトーンで返すか
といった部分もモデル内部で学習・調整されています。
これは自然さの面では非常に嬉しい反面、
- コールセンターのブランドトーン
- 法務的に NG な表現
- 業界特有の話し方(敬語の粒度、専門用語の出し方)
を 「完全に」コントロールしたい 場合は、むしろやりづらくなります。
ある程度はプロンプトやパラメータで寄せられるとしても、
従来の IVR のような「台本通りに 1 文ずつ読む」世界とは、かなり設計思想が違う。
このギャップを理解せずに「既存のコールセンタースクリプトをそのまま LLM にしゃべらせるだけ」と考えると、
現場から「なんか違う」「勝手に話を広げすぎ」といったフィードバックが返ってくる未来が見えます。
プライバシー:音声=環境ノイズ込みで吸い上げられる
コミュニティの声を見ていると、
- Gemini Live のアクティビティページに
- 「自分の声+背景ノイズ」まで含んだ生の音声スニペットが残っている
ことに、かなり敏感な反応が出ています。
つまり、
- 後ろで流れているテレビの音
- 家族・同僚の会話
- オフィスの環境音
まで、自分が意図していないレベルでクラウドに乗りうる ということです。
企業でこれを使うなら、
- 会話内容だけでなく「周囲の環境音も扱っている」ことを明示する
- 記録・保存ポリシーをユーザーにちゃんと伝える
- 必要であれば、マイク ON/OFF を物理的・UI 的にわかりやすくする
あたりは、法務・コンプライアンスとセットで設計しないと危ない領域です。
SynthID による音声透かしも、ディープフェイク抑止の文脈では良い話ですが、
「どこまでメタデータが付与されるのか」「トレース可能性がどの程度なのか」も、
規制業界ではいずれ議論の対象になると思います。
じゃあ、プロダクション投入するか?自分の結論
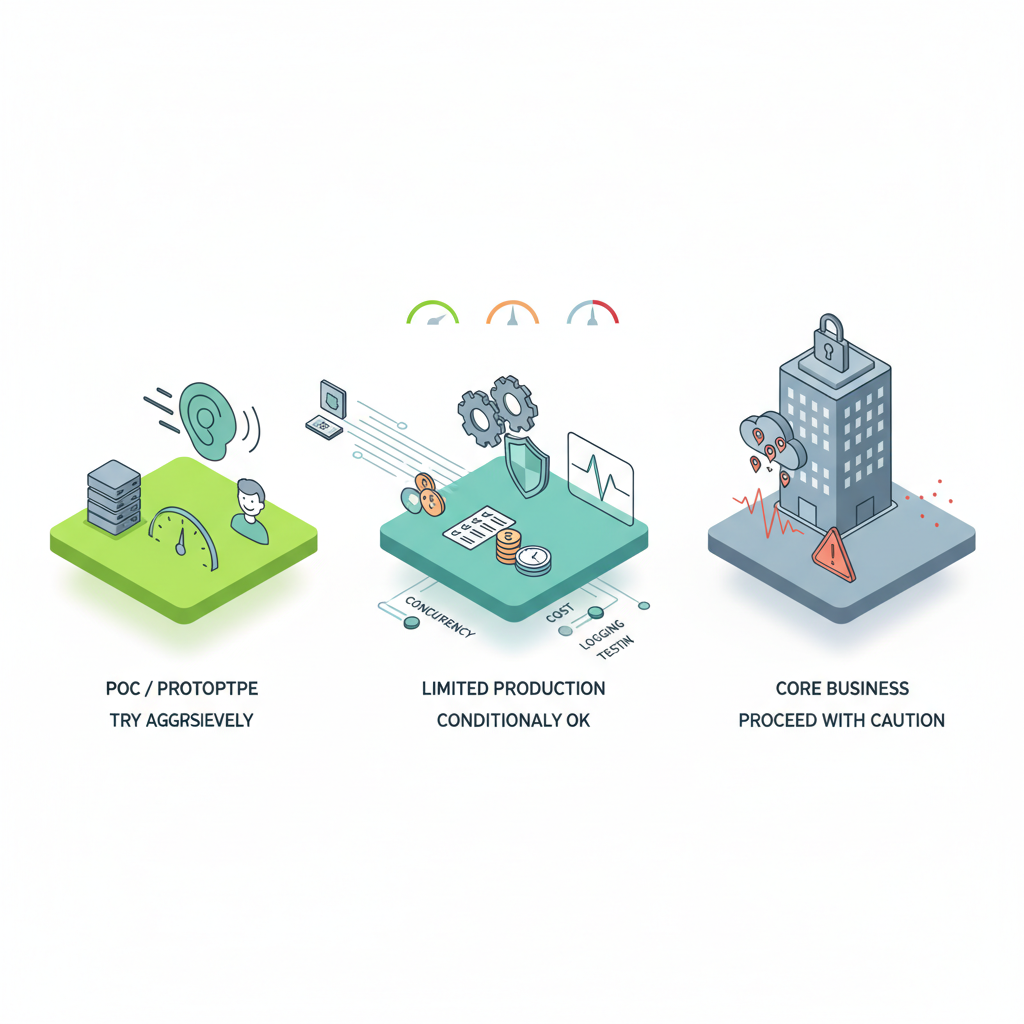
現時点での個人的なスタンスを整理すると、こんな感じです。
- PoC / プロトタイプ用途
→ 積極的に使ってみる価値はかなり高いです。 - 「耳と口付き LLM」を前提に UI/UX を組み替える経験は、今後数年単位で効いてきます。
-
OpenAI Realtime と並べて、レイテンシ・自然さ・ツール連携を比較する意味も大きいです。
-
限定的な本番(社内ツール、非ミッションクリティカルな音声ボット)
→ 条件付きで「あり」だと思います。 - コスト上限と同時接続数をきちんと決める
- ログと音声データの扱いを事前に合意しておく
-
クライアント側のストリーミング実装に十分テスト時間を割く
-
コアビジネスを丸ごと乗せる(大規模コールセンター、金融・医療系の本番)」
→ 正直、まだ様子見が妥当だと考えます。 - ベンチマーク上は優秀でも、「現場での予期せぬ挙動」をどこまで抑えられるかはこれから。
- ベンダーロックインとリージョン・データ保持要件を十分に検討しないまま、大規模移行するのはリスクが高い。
- まずは一部業務を切り出して、SLO(会話成功率・転送率・ユーザー満足度など)を見ながら徐々に広げる方が健全です。
最後に:これを「音声の便利機能」で終わらせるのはもったいない
Gemini 3.1 Flash Live を「音声入力ができる Gemini」と捉えると、たぶん本質を見誤ります。
- これは「耳と口を持ったエージェント」を、クラウドが標準機能として提供し始めた、という話です。
- Web が WebSocket を手に入れて、リアルタイムアプリが「普通の選択肢」になったのと同じフェーズに入ろうとしています。
正直、個人的には、
- 技術的前進としてはかなり評価していますし、
- Google が本気でここに投資しているのは歓迎すべきことだと思っています。
一方で、
- インタラクションモデルごとのロックイン
- コストプロファイルの変化
- 音声ならではのプライバシー問題
このあたりを「なんとなく便利そう」で流してしまうと、
数年後にかなり重いツケを払うことになりかねません。
これから音声 UX を設計するエンジニアは、
- 「どのクラウドを使うか」だけではなく
- 「会話そのものを、誰のプロトコルの上に構築するのか」
という視点で、一度立ち止まって設計してみる価値があると思います。
FAQ(導入判断でよくある質問)
Q. 既存のASR/LLM/TTS分割構成と何が一番違う?
「会話」を単一セッションとして扱い、割り込みやターンテイキングまで含めてモデル側に寄せる点です。個別最適の自由度は下がる一方、実装の泥臭さが減ります。
Q. テキストチャットも同じセッションで扱える?
音声/テキストのモード切替を前提に設計されており、UI次第で“会話の続き”として扱いやすくなります。
Q. 一番ハマりやすい落とし穴は?
常時接続前提のUIにしてしまい、セッション数×時間でコストが膨らむことと、会話データ(音声)の取り扱いが社内ルールと噛み合わないことです。
Q. まずPoCで何を計測すべき?
体感レイテンシ(割り込み含む)、会話成功率、転送率、1セッションあたりの平均コスト、ログ/監査の運用負荷の5点です。


コメント